Turning a server into a client
Clients and servers
One of the most common ways for networked devices and computers on the Internet to discover and communicate with each other is as clients and servers. Generally speaking, a server will be a device that offers some sort of information or service (it 'serves' up information) whereas a client will be a device that accesses these services on the server.
Pictorially this can be imagined like the spokes of a bicycle wheel, with a single server sitting in the centre at the hub and lots of clients sitting around the edge, joined to the server via the spokes. Often a server will allow lots of clients to connect to it (although this need not necessarily be the case).
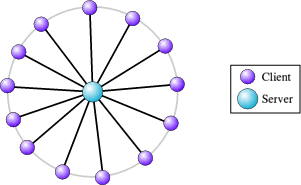
A classic example of the client server architecture as it's used on the Internet can be seen when you use the World Wide Web. To access a web page such as this one you might enter the address of the site into the URL bar of your web browser.
This URL identifies the location of the web server where the web page is kept. The viewer's computer therefore, controlled through the web browser, is acting as the client, whereas the web server where the page is stored acts (big surprise!) as the server. The client contacts the web server and requests the webpage, which the server then sends to the client. The client can then interpret and render this page in the web browser.
Location, location, location
From the description of clients and servers above it might seem reasonable to conclude that the server is always the computer providing a service to the client. Whilst this is generally the case, it needn't be. When a client contacts a server a two way link is established between the two devices, so information can travel between the two in both directions. It's therefore quite possible for a client to be providing a service to a server as well as the other way around. The real distinction between clients and servers actually concerns who contacts who first, and how they find the location of the other device.
The point is that the client is always the one that initiates the connection. In order to do this, the client needs to somehow know where the server is in advance so that it can send a message asking if it can have a conversation with the server. This is usually achieved manually, for example by the user entering the address of the server on the Internet, as was the case with our web-page example above. In establishing a connection, the first thing the client does (as part of the TCP/IP protocol) is provide the server with a return address; so that the server can send any reply to the right place. As we can see, then, the client needs to know how to locate the server, whereas the server gets the information about how to contact the client for free.
Role reversal
Applications tend to be written as either clients or servers (the exception being if it's peer to peer software, which we're going to ignore for simplicity). Often the client software and server software for a task will do different things (
e.g. a web browser and web server are very different). As a result you can't normally just swap them around. However, sometimes it can be useful to get them to reverse roles and get the server to act like a client and the client to act like a server. If we could do this we could have the server contact the client to establish whether the client happened to want to access anything on the server. The equivalent for our example would be if the web server contacted a particular web browser to see if the browser happened to want to access any of the pages on the server. To do this may seem all a bit topsy-turvy and pointless, but bear with me, and we'll find out why this might be a good idea!
What's the point?
In some circumstances the whole client-server thing just doesn't work very well. An example is when you have a firewall or NAT router that hides the server from the outside world. Firewalls and NAT routers do different things, but as far as we're concerned, the one important thing they will both often achieve is to prevent incoming connections to a device, whilst allowing outgoing connections. The result is that if you have a server hidden behind a firewall or NAT router, a client on the other side of the firewall will not be able to connect to the server. In the case of the firewall this will be because it specifically blocks the attempts made by the client to connect, whereas in the case of the NAT router it will be because the client doesn't even have a way to locate the server on the other network. However, the reverse is not the case. Firewalls and NAT routers will generally allow
outgoing connections. So if the client is behind a NAT router, it can connect to a server on the other side of the NAT router without any problem. It's a bit like being of no fixed abode. You can send letters to people, because you can just stick your letter in a letter box. But people can't send any letters to you, because they don't have an address to put on the envelope to send to you.
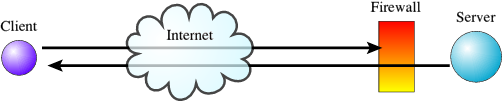
Note that once a connection has been made between a client and server the connection is bi-directional, and they can both happily talk to one another; it no longer matters about firewalls or NATs or whatever. It's just the initial setting up of the connection that can be a problem.
So, if we can somehow reverse the roles of the client and server, we could then access a server behind a firewall using a client on the other side; something which might otherwise be difficult or impossible.
Beacon and Watcher
We can use a couple of small pieces of software to make the role reversal that allows us to do exactly what we've just described. You can download these below; they've been called Beacon and Watcher. In short, Beacon will convert a server into a client, whereas Watcher will convert a client into a server.
Beacon works by sending connection requests at regular intervals to a particular IP address and on a particular port, thus acting like a client would; trying to connect to a specified server. If a connection is established Beacon then waits for any information to arrive. As soon it does, it connects itself to the server most likely running on the local machine (but which could in fact be running anywhere that the program can address). This is the server that we'll be converting to a client. It then passes any data it receives on to this server. Any data it receives back from the server it passes back out along the channel to the network and the original server that responded to the beacon.
Watcher works by listening for incoming connections. If it receives any connection requests (potentially any client, but most likely from the Beacon program just described) it accepts the connection and waits for a connection from somewhere else. Again, this is most likely the local machine, but could in fact be from anywhere. On receiving a second connection it then joins the two together and passes any data it receives on one connection to the other connection, acting as an intermediary just like Beacon. See the picture below for how this set up might look.
An example
Let's take a very concrete example. In fact it's the situation which motivated their creation in the first place. I have a computer at work and I find it very useful when I'm working from home to access it from my personal computer using VNC or terminal services. These servers run on my work computer, which is unfortunately hidden behind a firewall. Therefore I can't access these servers directly from home, since any incoming requests to my work computer are blocked by the firewall. I therefore run Beacon on my work computer, set up to periodically attempt to connect to my home computer.
When I want to access my work computer from home I run Watcher on my home computer. Ordinarily the connection requests sent out by Beacon to my home computer are just ignored, but when I run Watcher, it picks up these requests and a connection is made between Watcher and Beacon. At this point, I thererfore have a connection between my work and home computers. I then run a terminal server client called RDesktop on my home computer which connects to Watcher. Except that Watcher is passing all of the data sent to it on to my work computer where it is picked up by Beacon. Beacon then passes this data on to the terminal service server running on my work computer. The effect therefore is identical to me connecting to the server on my work computer, except now we are actually passing
through (or under) the firewall. Wahey! See the picture for what's going on here.

A word of warning
Normally firewalls will be set up for a reason, and often this reason will be security. As far as I'm concerned you're welcome to download and use Beacon and Watcher for legitimate purposes. However, bypassing a firewall could have dangerous effects and compromise the security of the network that is behind the firewall. If set up properly, the risks are likely to be minimal, but if it's not your network then you should be wary, and certainly make sure that it's okay for you to use the software in this way, before doing so. Apart from anything else, using it without agreement at work may be in violation of your workplace's IT policy.
Staying connected
As mentioned earlier, the way Beacon works is by sending out a connection request every 15 seconds or so. A legitimate question would be why it bothers to try to make repeated connections, when a single connection that doesn't timeout might work just as well. If we were to do this, we would get an instant connection as soon as we started up Watcher on the other machine, rather than having to wait up to a quarter of a minute before the connection is made. In fact, originally this is exactly what Beacon did. Unfortunately I found that if this method was used, it would eventually fail to work if the broadband router was left on for too long. My broadband router is also a NAT box, which I had set up as a virtual server to forward incoming connection requests to the computer on which I run Watcher. In order for a NAT to work, it must remember all connections in a connection table, so that it can translate the address used internally to the port used externally to identify it. It turns out that most NATs will discard entries in this table after a certain length of time if no data is sent or received on a connection. With Beacon set to send out a single continuous connection request that never timed out, eventually the NAT would drop the details of this connection from its connection table. The only solution was to reboot the NAT server and start again. Having Beacon renew its connection request every 15 seconds circumvents the problem, since the NAT router never stores the connection for long enough for it to discard it.
Descendburden
The download is an archive containing four programs, but you should only need two of them. The programs are as follows.
Beacon: A Windows program that does what was described above. It should be run with two optional parameters as follows:
bBeacon <Beacon IP> <Server IP>
The first is the IP address to send the beacon signal to; the second parameter is the IP address to connect to once the beacon signal has been acknowledged. In both cases, the port may be specified as a suffix to the IP address separated by a colon.
For example, you could use
Beacon 800.0.0.100:6456 127.0.0.1:23 to send a beacon to port 6456 of the machine with address 800.0.0.100 and connect to the local server on port 23.
BeaconService: This is the same as the Windows program Beacon described above, but implemented as a Windows service. This means that it can be run continuously, even it there's no user logged in. The downside is that it can only be installed by a user with administrator privileges. It takes the two same parameters as Beacon.
Watcher: This Windows application runs at the other end of the connection listening for messages from Beacon. It accepts two parameters, but instead of IP addresses, because it's effectively acting as two servers, it only needs two port numbers as follows:
Watcher <Listen port> <Listen port>
For example, you could use
Watcher 23 6456 to listen on ports 23 and 6456.
!Watcher: This is the same as the Watcher program described above, except that it runs as an application for RISC OS rather than Windows.
Feel free to
contact me about Beacon or Watcher.
