List items
Items from the current list are shown below.
Blog
14 Jan 2024 : Day 138 #
Finally, after much meandering and misdirected effort, an important reason for my copied version of DuckDuckGo failing became clear yesterday. I admit I'm a bit embarrassed that I didn't spot it earlier, but there's no hiding here.
Simply put, DuckDuckGo uses paths with a preceding / in the site HTML file rather than fully relative URLs. So by placing the files in a "tests/ddg8" folder on my server, I was breaking most of the links.
Now, admittedly, I've not yet had a chance to see what happens when this is fixed, so there could well be other issues as well. But what's for sure is that without fixing this, the copied site will remain broken.
My plan is to make use of the HTML base element to try to work around the issue. This can be added to the head of an HTML file to direct the browser to the root of the site, so that all relative URLs are resolved relative the the base address.
I should also check for URLs that start with https://duckduckgo.com/ or similar as these won't be fixed by this change.
Since the location of my test site is https://www.flypig.co.uk/tests/ddg8/ the addition I need to make is a line inside the head element of the index.html file like this:
So I'm going to have to make more intrusive changes, removing these preceding slashes from all instances of the URL in the page and all files that get loaded with it. I was hoping to avoid that.
There are alternatives to this intrusive fix though. Here are the three alternatives I can think of:
So this is what I've done. I didn't end up spinning up a server but rather copied the files over to an S3 bucket no Amazon Web Services. There's an option to serve static files from an S3 bucket as a website, which is exactly what I need.
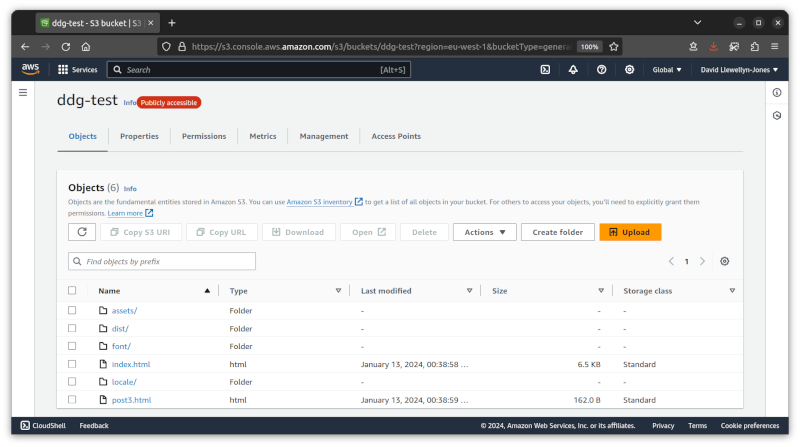
Testing the site using desktop Firefox shows a much better result than before. It's not perfect: there are still some missing images, but the copy I made to the bucket is the mobile version, so that's to be expected. Nevertheless it makes for a pretty reasonable facsimile of the real DuckDuckGo site.

But what about if I try it on mobile?
Using ESR 78 it's uncannily similar to the real DuckDuckGo site. Even the menu on the left hand side works. Search suggestions and search itself are of course both broken, but again this is entirely to be expected since these features require dynamic aspects of the site which can't be replicated using an S3 bucket.
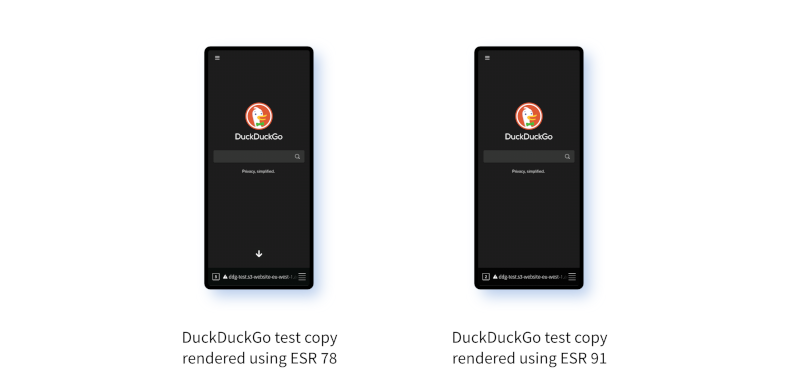
But the real test is ESR 91. When I try it there... I also get a good rendition of the DuckDuckGo site. This is both good and bad. If it had failed to render that would have been ideal, because then I'd immediately have a comparison to work with. But the fact that it works well means I can now compare it with the real version of the site and try to figure out what's different.
It's also worth noting that the results aren't the same. On ESR 78 I can scroll down to view all the "bathroomguy" images telling me how great the site is. On ESR 91 the rendered down arrow is missing and I'm not able to scroll, as you can see in the screenshots if you peer closely.
So, what's the difference? That'll be my task for tomorrow!
This lends more weight to the claim that the problem here DuckDuckGo serving different pages rather than the ESR 91 renderer or JavaScript engine choking on something. I have a plan for how to test this categorically tomorrow.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
Simply put, DuckDuckGo uses paths with a preceding / in the site HTML file rather than fully relative URLs. So by placing the files in a "tests/ddg8" folder on my server, I was breaking most of the links.
Now, admittedly, I've not yet had a chance to see what happens when this is fixed, so there could well be other issues as well. But what's for sure is that without fixing this, the copied site will remain broken.
My plan is to make use of the HTML base element to try to work around the issue. This can be added to the head of an HTML file to direct the browser to the root of the site, so that all relative URLs are resolved relative the the base address.
I should also check for URLs that start with https://duckduckgo.com/ or similar as these won't be fixed by this change.
Since the location of my test site is https://www.flypig.co.uk/tests/ddg8/ the addition I need to make is a line inside the head element of the index.html file like this:
<base href="https://www.flypig.co.uk/tests/ddg8/" />On trying this, in practice and contrary to what I'd expected, it turns out that when a URL has a preceding / it's considered an absolute URL as well. The spec wasn't clear on this point for me, but it means it's resolved relative to the domain name, not relative to the base. That's rubbish, but observable behaviour. Rubbish because it means I can't use this as my solution after all.
So I'm going to have to make more intrusive changes, removing these preceding slashes from all instances of the URL in the page and all files that get loaded with it. I was hoping to avoid that.
There are alternatives to this intrusive fix though. Here are the three alternatives I can think of:
- Move the site to the root of the URL. This will get it mixed up with the rest of my site so I'd rather not do that.
- Move it to a completely new URL. This is definitely an option. I could spin up a Cloud server for this pretty easily.
- Configure the server so that it serves the directory from the root URL. The would be cheaper than using a Cloud service.
So this is what I've done. I didn't end up spinning up a server but rather copied the files over to an S3 bucket no Amazon Web Services. There's an option to serve static files from an S3 bucket as a website, which is exactly what I need.
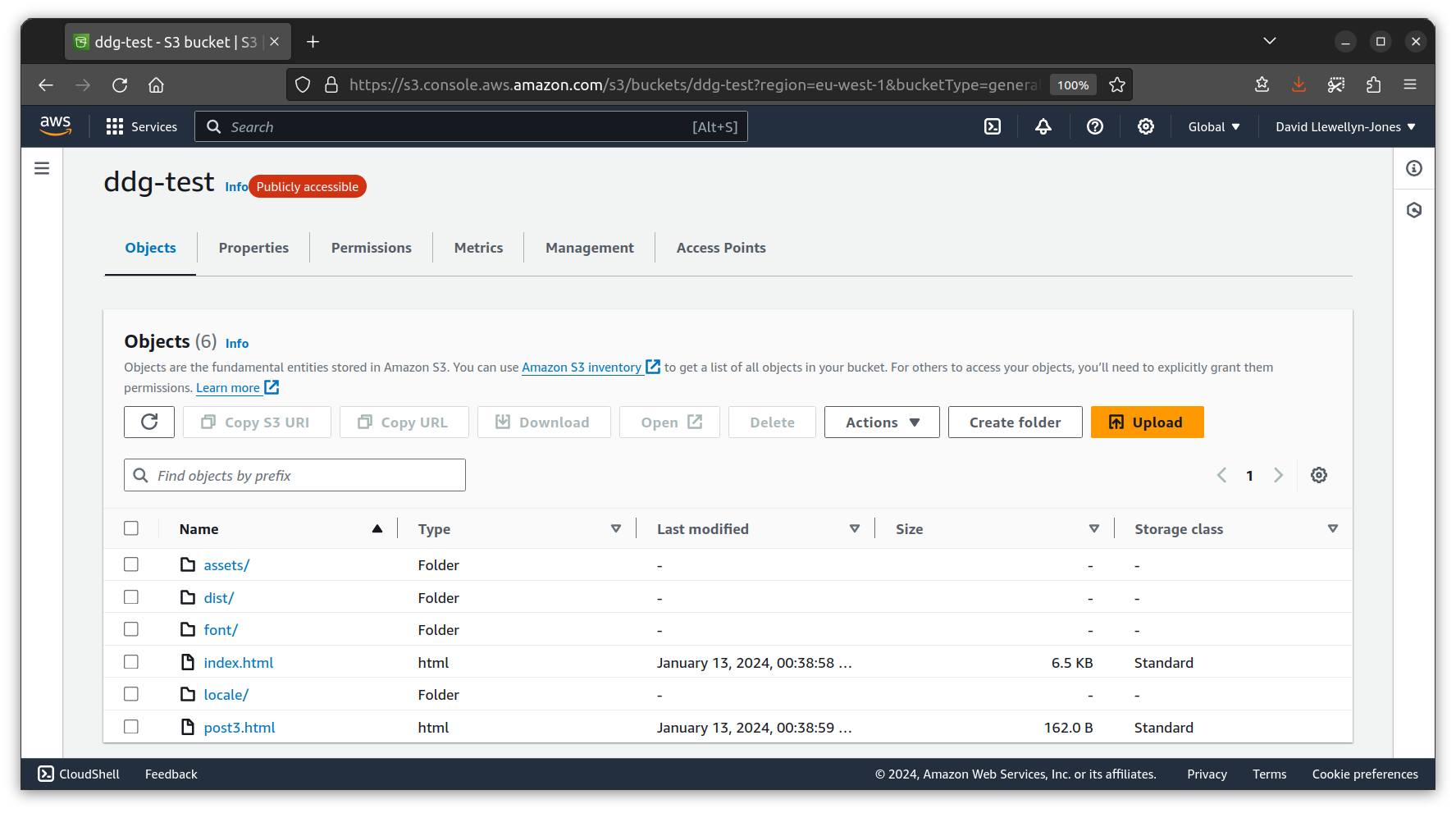
Testing the site using desktop Firefox shows a much better result than before. It's not perfect: there are still some missing images, but the copy I made to the bucket is the mobile version, so that's to be expected. Nevertheless it makes for a pretty reasonable facsimile of the real DuckDuckGo site.

But what about if I try it on mobile?
Using ESR 78 it's uncannily similar to the real DuckDuckGo site. Even the menu on the left hand side works. Search suggestions and search itself are of course both broken, but again this is entirely to be expected since these features require dynamic aspects of the site which can't be replicated using an S3 bucket.
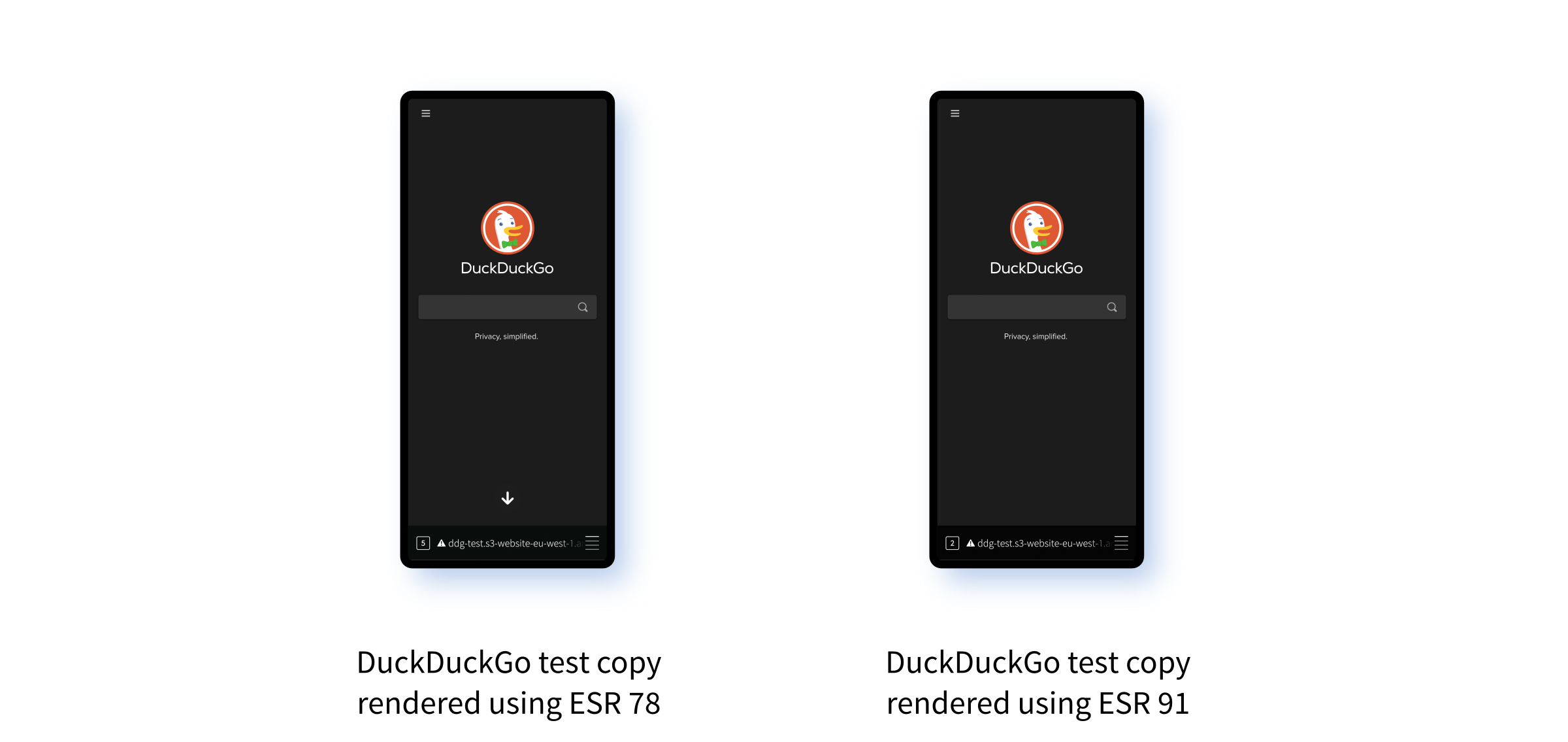
But the real test is ESR 91. When I try it there... I also get a good rendition of the DuckDuckGo site. This is both good and bad. If it had failed to render that would have been ideal, because then I'd immediately have a comparison to work with. But the fact that it works well means I can now compare it with the real version of the site and try to figure out what's different.
It's also worth noting that the results aren't the same. On ESR 78 I can scroll down to view all the "bathroomguy" images telling me how great the site is. On ESR 91 the rendered down arrow is missing and I'm not able to scroll, as you can see in the screenshots if you peer closely.
So, what's the difference? That'll be my task for tomorrow!
This lends more weight to the claim that the problem here DuckDuckGo serving different pages rather than the ESR 91 renderer or JavaScript engine choking on something. I have a plan for how to test this categorically tomorrow.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
Comments
Uncover Disqus comments