List items
Items from the current list are shown below.
Blog
Many websites are made up of some core stateless functionality tied to a database where all the state lives. The functionality may make changes to the database state, but all of the tricky issues related to concurrency and consistency (for example, in case two users simultaneous cause the database to be updated) are left to the database to deal with. That allows the stateless part to be partitioned off and run only when the user is actually requesting a page, making it easily scalable.
In this scenario, having a full-time monolithic server (or bank of servers) handling the website requests is overkill. Creating a new server instance for each request is potentially much more cost efficient and scalable. Each request to the site triggers a new function to be called that runs the code needed to generate a webpage (e.g. filling out a template with details for the user and view), updating the database if necessary. Once that’s done, the server is deleted and the only thing left is the database. An important benefit is that, if there are no requests coming in, there’s no server time to pay for. This is the idea behind ‘serverless’ architectures. Actually, there are lots of servers involved (receiving and actioning HTTP requests, running the database, managing the cluster) but they’re hidden and costs are handled by transaction rather than by uptime.
AWS Lambda is one of the services Amazon provides to allow this kind of serverless set up. Creating ‘Lambda functions’ (named after the Lambda calculus, but really they’re just functions) that run on various triggers, like a web request, has been made as easy as pie. Connecting these functions to an RDS database has also been made really easy. But there’s a fly in the ointment.
To get the Lambda function communicating with the RDS instance, it’s common practice to set them both up inside the same Virtual Private Cloud. This isn’t strictly necessary: it’s possible to have the database exposed on a public IP and have the Lambda function communicate with it that way. However, the obvious downside to doing it like this is that the database is exposed to the world, making it a hacking and denial-of-service target. If both the Lambda function and database are in a VPC, then assuming everything is suitably configured, the database will be effectively protected from external attack.
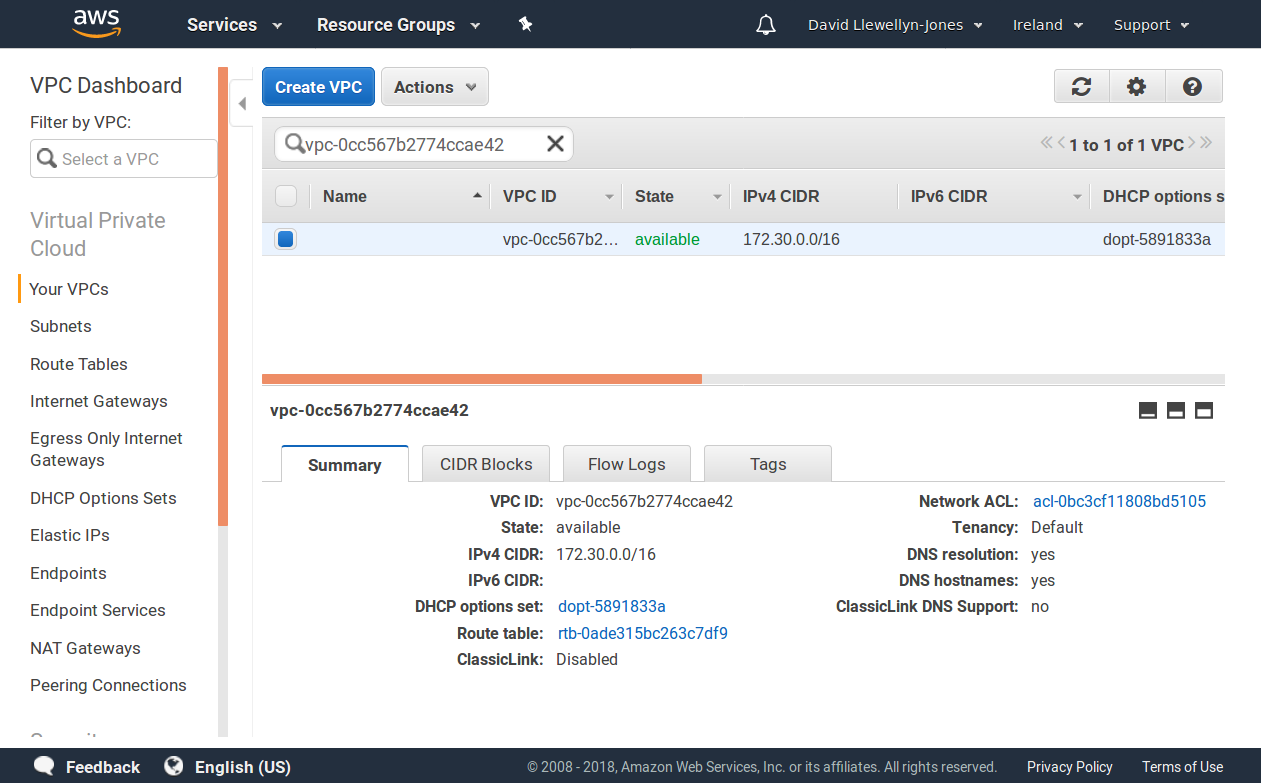
The beauty of this arrangement is that the Lamdba functions will still respond to the GET and POST requests for accessing the site, because these are triggered by API Gateway events rather than direct connections to the functions. It’s a nice arrangement.
However, with the Lambda function inside the VPC, just like the database, it has no public IP address. This means that by default it can’t make any outgoing connections to public IP addresses. This doesn’t necessarily matter: a website access will trigger an event, the Lambda function fires up, communicates with the database, hands over a response which is sent back to the user. The API gateway deals with the interface between the request/response and Lambda function interface.
The problem comes if the Lambda function needs to access an external resource for some other reasons. For example, it might want to send an email out to the user, which requires it to communicate with an SMTP server. Websites don’t often need to send out emails, but on the occasions they do it tends to be to ensure there’s a second communication channel, so it can’t be handled client-side. For example, when a user registers on a site it’s usual for the site to send an email with a link the user must click to complete the registration. If the user forgets their password, it’s common practice for a site to send a password reset link by email. Increasingly sites like Slack are even using emails as an alternative to using passwords.
A Lambda function inside a VPC can’t access an external SMTP server, so it can’t send out emails. One solution is to have the RDS and the Lambda function on the public Internet, but this introduces the attack surface problem mentioned above. The other solution, the one that’s commonly recommended, is to set up a NAT Gateway to allow the Lambda function to make outgoing connections to the SMTP server.
Technically this is fine: the Lambda function and RDS remain protected behind the NAT because they’re not externally addressable, but the Lambda function can still make the outgoing connection it needs to send out emails. But there’s a dark side to this. Amazon is quite happy to set up a NAT to allow all this to happen, but it’ll charge for it by the hour as if it’s a continuously allocated instance. The benefits of running a serverless site go straight out the window, because now you’ve essentially got a continuously running, continuously charged, EC2 server running just to support the NAT. D’oh.
Happily there is a solution. It’s a cludge, but it does the trick. And the trick is to use S3 as a file-based gateway between a Lambda function that’s inside a VPC, and a Lambda function that’s outside a VPC. If the Lambda function inside the VPC wants to send an email, it creates a file inside a dedicated S3 bucket. At the same time we run a Lambda function outside the VPC, triggered by a file creation event attached to the bucket. The external Lambda function reads in the newly created file to collect the parameters needed for the email (recipient, subject and body), and then interacts with an SMTP server to send it out. Because this second Lambda function is outside the VPC it has no problem contacting the external SMTP server directly.
So what’s so magical about S3 that means it can be accessed by both Lambda functions, when nothing else can? The answer is that we can create a VPC endpoint for S3, meaning that it can be accessed from inside the VPC, without affecting the ability to access it from outside the VPC. Amazon have made special provisions to support this. You’d have thought they could do something similar with SES, their Simple Email Service, as well and fix the whole issue like that. But it’s not currently possible to set SES up as a VPC endpoint, so in the meantime we’re stuck using S3 as a poor-man’s messaging interface.
The code needed to get all this up-and-running is minimal, and even the configuration of the various things required to fit it all together isn’t particularly onerous. So let’s give it a go.
Creating an AWS Lambda S3 email bridge
As we’ve discussed, the vagaries of AWS mean it’s hard to send out emails from a Lambda function that’s trapped inside a VPC alongside its RDS instance. Let’s look at how it’s possible to use S3 as a bridge between two Lambda functions, allowing one function inside the VPC to communicate with a function outside the VPC, so that we can send some emails.At the heart of it all is an S3 bucket, so we need to set that up first. We’ll create a dedicated bucket for the purpose called ‘yfp-email-bridge’. You can call it whatever you want, but you’ll need to switch out ‘yfp-email-bridge’ in the instructions below for whatever name you choose.
Create the bucket using the Amazon S3 dashboard and create a folder inside it called email. You don’t need to do anything clever with permissions, and in fact we want everything to remain private, otherwise we introduce the potential for an evil snooper to read the emails that we’re sending.
Here’s my S3 bucket set up with the email folder viewed through the AWS console.
Now let’s create our email sending Lambda function. We’re using Python 3.6 for this, but you can rewrite it for another language if that makes you happy.
So, open the AWS Lambda console and create a new function. You can call it whatever you like, but I’ve chosen send_email_uploaded_to_s3_bridge (which in retrospect is a bit of a mouthful, but there’s no way to rename a function after you’ve created it so I’m sticking with that). Set the runtime to Python 3.6. You can either use an existing role, or create a new one with S3 read and write permissions.
Now add an S3 trigger for when an object is created, associated with the bucket you created, for files with a prefix of email/ and a suffix of .json. That’s because we’re only interested in JSON format files that end up in the ‘email’ folder. You can see how I’ve set this up using the AWS console below.

When the trigger fires, a JSON string is sent to the Lambda function with contents much like the following. Look closely and you’ll see this contains not only details of the bucket where the file was uploaded, but also the filename of the file uploaded.
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "eu-west-1",
"eventTime": "2018-08-20T00:06:19.227Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "A224SDAA064V4C"
},
"requestParameters": {
"sourceIPAddress": "XX.XX.XX.XX"
},
"responseElements": {
"x-amz-request-id": "D76E8765EFAB3C1",
"x-amz-id-2": "KISiidNG9NdKJE9D9Ak9kJD846hfii0="
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "67fe8911-76ae-4e67-7e41-11f5ea793bc9",
"bucket": {
"name": "yfp-email-bridge",
"ownerIdentity": {
"principalId": "9JWEJ038UEHE99"
},
"arn": "arn:aws:s3:::yfp-email-bridge"
},
"object": {
"key": "email/email.json",
"size": 83,
"eTag": "58934f00e01a75bc305872",
"sequencer": "0054388a73681"
}
}
}
]
}
Now we need to add some code to be executed on this trigger. The code is handed the JSON shown above, so it will need to extract the data from it, load in the appropriate file from S3 that the JSON references, extract the contents of the file, send out an email based on the contents, and then finally delete the original JSON file. It sounds complex but is actually pretty trivial in Python. The code I use for this is the following. You can paste this directly in as your function code too, just remember to update the sender variable to the email address you want to send from.
import os, smtplib, boto3, json
from email.mime.text import MIMEText
s3_client = boto3.client('s3')
def send_email(data):
sender = 'test@test.com'
recipient = data['to']
msg = MIMEText(data['body'])
msg['Subject'] = data['subject']
msg['From'] = sender
msg['To'] = recipient
result = json.dumps({'error': False, 'result': ''})
try:
with smtplib.SMTP(host=os.environ['SMTP_SERVER'], port=os.environ['SMTP_PORT']) as smtp:
smtp.set_debuglevel(0)
smtp.starttls()
smtp.login(os.environ['SMTP_USERNAME'], os.environ['SMTP_PASSWORD'])
smtp.sendmail(sender, [recipient, sender], msg.as_string())
except smtplib.SMTPException as e:
result = json.dumps({'error': True, 'result': str(e)})
return result
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
size = record['s3']['object']['size']
# Ignore files over a certain size
if size < (12 * 1024):
obj = s3_client.get_object(Bucket=bucket, Key=key)
data = json.loads(obj['Body'].read().decode('utf-8'))
send_email(data)
# Delete the file
print("Deleting file {bucket}:{key}".format(bucket=bucket, key=key))
s3_client.delete_object(Bucket=bucket, Key=key)
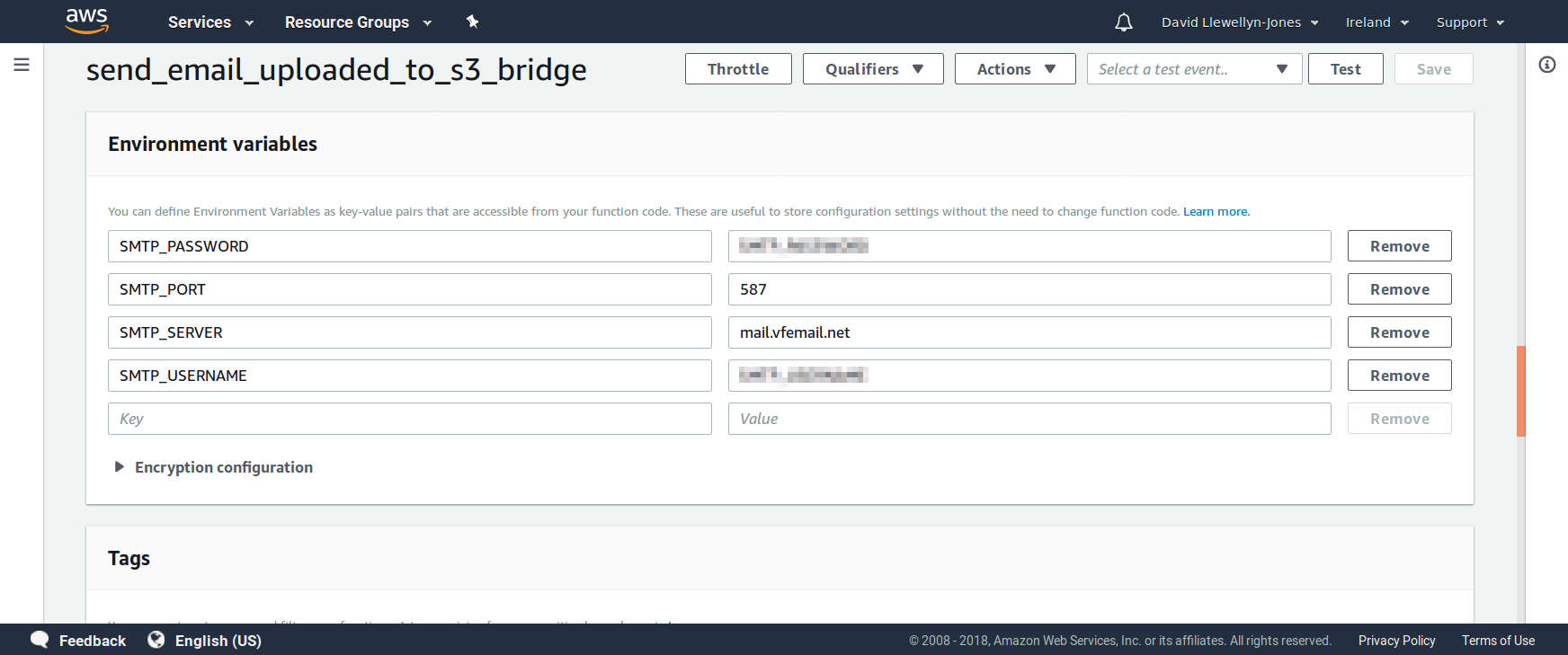
This assumes that the following environment variables have been defined:
SMTP_SERVER SMTP_PORT SMTP_USERNAME SMTP_PASSWORD
The purpose of these should be self-explanatory, and you’ll need to set their values to something appropriate to match the SMTP server you plan to use. As long as you know what values to use, filling them on the page when creating your Lambda function should be straightforward, as you can see in the screenshot below.
Now save the Lambda function configuration. We’ve completed half the work, and so this is a great time to test whether things are working
Comments
Uncover Disqus comments