List items
Items from the current list are shown below.
Blog
13 Nov 2024 : Templating in C #
Many years ago — probably some time around 2006 — I was working as a researcher at Liverpool John Moores University and we had an external speaker come to talk to our students about C++ coding.
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
For the methods we have a bunch of constructors and destructors:
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
If you look in the main() method in main.c you'll see an example of its use:
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
Next we define the default constructor and destructor, alongside respective new and delete methods.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
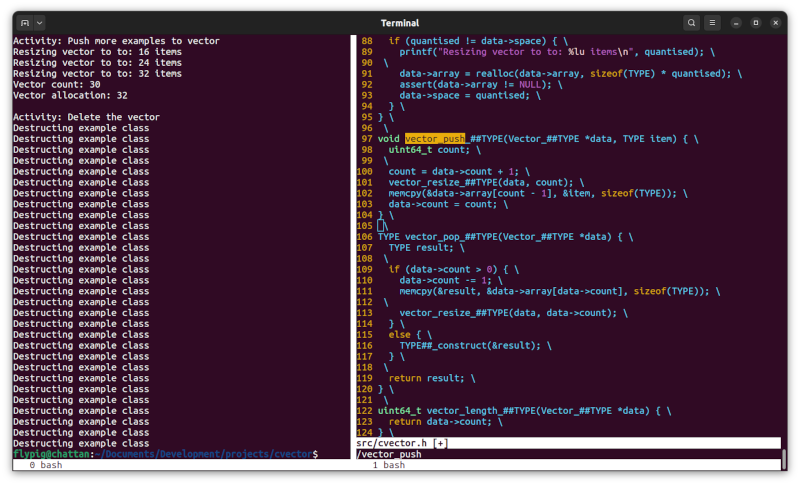
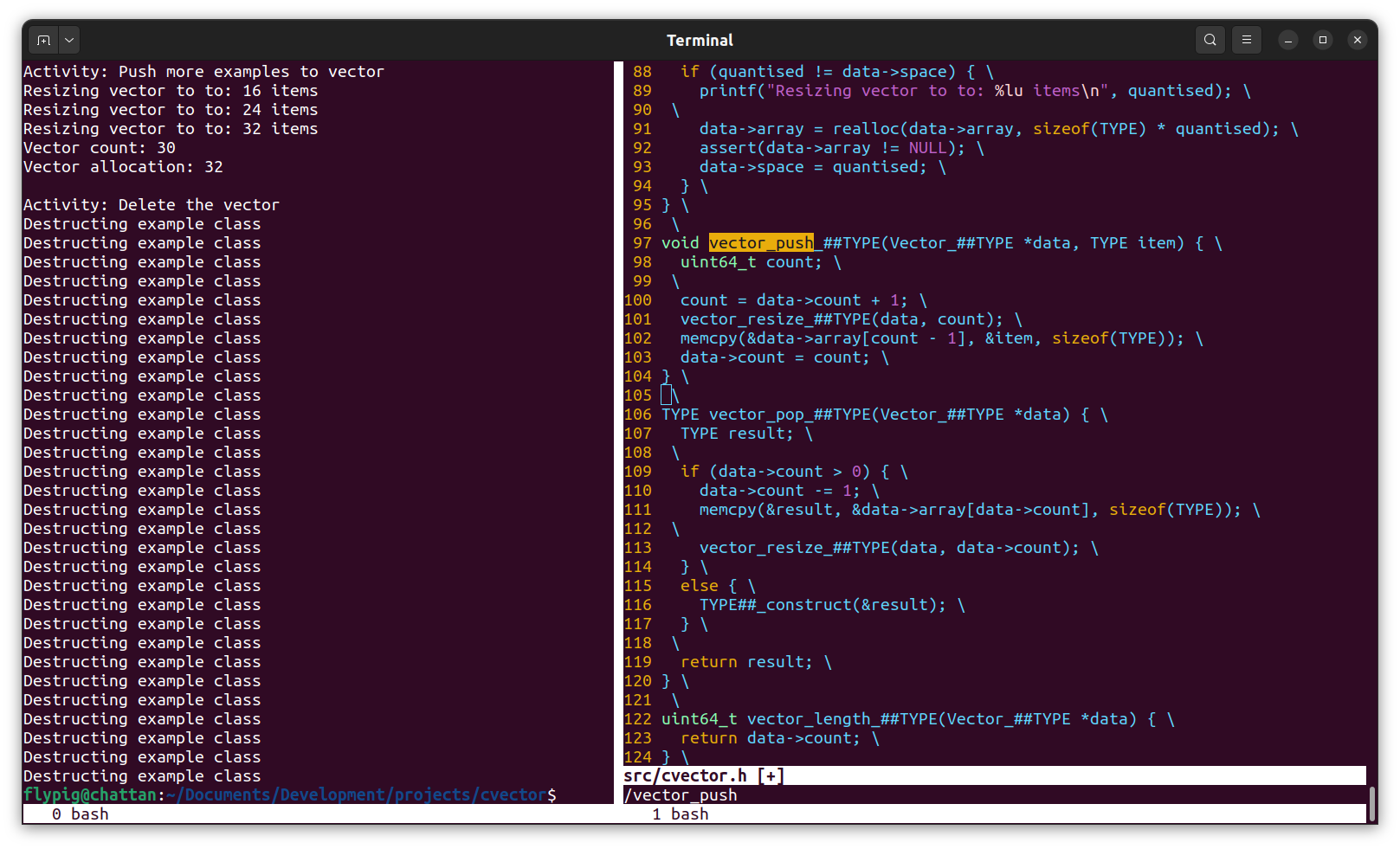
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
"I appreciate the simplicity of C++'s vector (for example). You probably can do something similar in C but won't it be more involved to get it working for all types for example?"
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
struct _Example {
uint64_t length;
char * string;
};
As you can see the class holds a length to indicate the length of the string and a dynamic array of char instances for the string data. You can imagine that this is a much simplified version of the standard library's string class.For the methods we have a bunch of constructors and destructors:
void Example_construct(Example *data); void Example_construct_init(Example *data, char const * const string); void Example_destruct(Example *data);Similar to C++ we have a default constructor and an "override" that accepts initialisation parameters. It's not an override at all of course because C doesn't support multiple functions using the same name. Instead we just name the two constructors differently, but with the same prefix. Under the hood this is what C++ is doing as well through name mangling, it's just hidden from the programmer.
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Example *example_new(); Example *example_new_init(char const * const string); Example *example_delete(Example *data);These two new methods do allocate memory for the object data, before calling the constructor. Contrariwise the delete method calls the destructor and then frees the allocated memory. I've not looked at the C++ source code for creation and deletion, but I imagine it does something similar.
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
void example_sprintf(Example *data, char const * format, ...); void example_debug_print(Example *data);If this were a proper string implementation we'd want a lot more functionality for accessing and manipulating the string. But this simple example is enough for our purposes.
If you look in the main() method in main.c you'll see an example of its use:
Example_construct_init(&example, "Hello World!"); example_debug_print(&example);Now as the name suggestions this is just an example class, but it already demonstrates the foundations of our class-based approach to C. Apart from the new methods every one of our functions accepts a pointer to an Example as its first parameter. This is the equivalent of the class object this in C++. Every class has a constructor and a destructor. Following the same conventions for all other struct implementations will make our C code safer and more robust, and will encourage increased separation between classes.
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
typedef struct _Vector Vector;Unlike for our Example class in this case we're keeping the actual implementation opaque because we don't have to know its size for use elsewhere.
Next we define the default constructor and destructor, alongside respective new and delete methods.
void vector_construct(Vector *data); Vector *vector_new(); void vector_destruct(Vector * data); Vector *vector_delete(Vector *data);Finally we have a bunch of class methods that are unique to this class and which provide all of the real functionality:
Example vector_get(Vector *data, uint64_t position); void vector_push(Vector *data, Example example); Example vector_pop(Vector *data); uint64_t vector_length(Vector *data); void vector_resize(Vector *data, uint64_t required); void vector_debug_print_space(Vector *data);We have a method for getting items from the vector using random access, a method for pushing items to the end of the vector; a method for popping items from the end of the vector and a method that returns the number of items in the vector. The resize method is for internal use (I shouldn't have included it in the header really) and a debug method for printing out some info about the contents of the vector.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
struct _Vector {
uint64_t space;
uint64_t count;
Example *array;
};
Here we store an array of Example elements. We use a pointer rather than an actual array because we want the size to be dynamic, but by giving it the Example type our stride will be sizeof(Example). We also store a count to represent the number of items in the vector and a space value which represents the size of the array.The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
void vector_push(Vector *data, Example example) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &example, sizeof(Example));
data->count = count;
}
The purpose of this method is to push an item to the end of the vector. We calculate the new space required, which is just the current space plus one (we're adding a single element to the end). We resize the array using vector_resize() to ensure we have the space for it. Then we copy the value from the passed Example structure into the memory that we now know is now available in the array. Finally we set the count of our array to the new, incremented, value.We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
- void example_construct(Example *data);
- void example_destruct(Example *data);
- Example *example_copy(Example const *data, Example *other);
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
typedef struct _Vector {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector;
By way of example for the methods, this is what our vector_push() becomes:
void vector_push(Vector *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
Eventually we'll put these into a macro and we'll need to generate different versions for every TYPE we want to use. But let's not get ahead of ourselves just yet.In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
typedef struct _Vector_##TYPE {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector_##TYPE;
Now our vector implementation for the Example type will use a struct called Vector_Example rather than just Vector. We can do the same thing for our methods as well, like this:
void vector_push_##TYPE(Vector_##TYPE *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize_##TYPE(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
So now our vector_push() method will actually take the name vector_push_Example(). If we were to create a vector that consumes a different type, say a Blob type, the names would become Vector_Blob and vector_push_Blog() respectively.We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
#define vector_push(TYPE) vector_push_##TYPENow, if we want to call the vector_push() method that we've defined for the Example type, we can call it like this:
vector_push(Example)(vector, example);The code with Example surrounded by parenthesis can be considered like the angle-bracket equivalent for templates in C++:
vector_push<Example>(vector, example);We just have to use parentheses rather than angle brackets because C has no concept of the angle brackets as used for templates. The compiler would think they were inequalities.
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
example_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
We need to fix the call to example_destruct() in the middle of that code so that it calls the destructor for the specific type held by the vector. We can do it like this:
void vector_destruct_##TYPE(Vector_##TYPE * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
TYPE##_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
So now, in the case of our vector holding Example objects this will now call Example_destruct() whereas for our vector holding Blob objects, this will call Blob_destruct(). Great!The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
void Example_construct(Example *data); void Example_destruct(Example *data);It's a bit ugly like this in my opinion, but pragmatically it's the right thing to do. For example, it ensures we can to support structs that share the same name apart from their capitalisation, just as we should.
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
#define VECTOR_TEMPLATE(TYPE) \
typedef struct _Vector_##TYPE { \
uint64_t space; \
uint64_t count; \
\
TYPE *array; \
} Vector_##TYPE; \
[...]
With all this in place, the only thing we now need to do is add a call to this macro at the top of our code to define the actual vector classes we want to use:
VECTOR_TEMPLATE(Example) VECTOR_TEMPLATE(Blob) [...]And that's it! We now have a fully type-safe templated vector class written in C that doesn't require any C++ magic.
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
#include <type_traits>
template <typename TYPE>
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
if constexpr (std::is_object_v<TYPE>) {
for (pos = 0; pos < data->count; ++pos) {
destruct(&data->array[pos]);
}
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
Sadly the C pre-processor simply isn't sophisticated enough to do anything like this. This also hints at other issues that we might experience with our C implementation. For example, everything works fine for vanilla types, but if we try to use pointers, or const pointers, or any datatype with a composite name, we're going to run in to trouble. There's a solution, which is to make a typedef and use that instead, but it's an extra layer of abstraction and work. Likewise, if we want to use a datatype that has no constructor or destructor (for example if it's a fundamental type) then we'll have to define an empty constructor and an empty destructor in order to allow the code to compile. We can set these as being inline so that the compiler can optimise them away, but again, it's extra work.Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?
Comments
Uncover Disqus comments