List items
Items from the current list are shown below.
Blog
All items from November 2024
26 Nov 2024 : A Brief Embedded Browser Expo #
The question of whether Gecko is the most appropriate browser for use on Sailfish OS is a perennial one. Back in the days of Maemo, with a user interface built using Gtk, Gecko may have seemed like a natural choice. But with the shift to Qt on the N9 and with Sailfish OS sticking to Qt ever since, it's natural to ask whether something like WebKit might not be a better fit.
Indeed, for many years WebKit was also an integral part of Sailfish OS, providing the embeddable QtWebKit widget that many other apps used as a way of rendering Web content. It wasn't until Sailfish OS 4.2.0 that this was officially replaced by the Gecko-based WebView API.
The coexistence of multiple engines within the operating system isn't the only reason many people felt WebKit would make a better alternative to Gecko. Another is the fact that WebKit, and subsequently Blink, has become the defacto standard for embedded applications. In contrast, although Mozilla were pushing embedded support back when Maemo was being developed, it's since dropped official embedded support entirely.
So in this post I'm going to take a look at embedded browsers. What does it mean for a browser to be embedded, what APIs are supported by the most widely used embedded toolkits, and might it be true that Sailfish OS would be better off using Blink? In fact, I'll be leaving this last question for a future post, but my hope is that the discussion in this post will serve as useful groundwork.
Let's start by figuring out what an embedded browser actually is. In my mind there are two main definitions, each embracing a slightly different set of characteristics.
If you frame it right though, these two definitions can feel similar. Here's how the Web Platform for Embedded team describe it:
So minimal, encapsulated, targeted. Maybe something you don't even realise is a browser.
And what does this mean in practice? That might be a little hard to pin down, but for me it's all about the API. What API does the browser expose for use by other applications and systems? If it provides bare-bones render output, but with enough hooks to build a complete browser on top of (at a minimum) then you've got yourself an effective embedded browser.
In the past Gecko provided exactly this in the form of the EmbedLIte API and the XULRunner Development Kit. The former provides a set of APIs that allow Gecko to be embedded in other applications. The latter allows the Gecko build process to be harnessed in order to output all of the libraries and artefacts needed (such as the libxul.so library and the omni.ja resource archive) to integrate Gecko into another application.
Sadly Mozilla dropped support for both of these back in 2016, when it was decided the core Firefox browser needed to be prioritised over an embedding offering. Mozilla has made plenty of questionable decisions over the years and given the rise in use of WebKit and Chrome as embedded browsers, you might think this was one of them. But despite the lack of investment in the API, it's not been removed entirely, to Mozilla's credit. It is, in fact, still possible to access the EmbedLite APIs and to generate the XULRunner artefacts and get a very effective embedded browser.
We'll come back to the EmbedLite approach to embedding later. But in order to understand it better, I believe it's also helpful to understand the context. I therefore plan to look at three different embedded browser frameworks. These are CEF (the Chromium Embedded Framework), Qt WebEngine and then finally we'll return to Gecko by considering the Gecko WebView.
Looking through the documentation I was surprised at how similar these three frameworks appear to be. But trying them out I was quickly divested of this misapprehension. They do offer similar functionality, but turn out to be quite different to use in practice.
Before we get in to the API details, let's first consider what a minimal embedded browser external interface might look like.
Let's now turn to the three individual embedding frameworks to see how they approach all this.
And that's exactly how CEF brings value. It takes the Chromium internals (Blink, V8, etc.) and wraps them with the basic windowing scaffolding needed to get a browser working across multiple platforms (Linux, Windows, macOS). It then adds in a streamlined interface for controlling the most important features needed for embedding (settings, browser controls, JavaScript injection, message passing).
Having worked through the documentation and tutorials, the CEF project assumes a slightly different workflow from what I'd typically expect. Qt WebEngine and Gecko WebView are both provided as widgets that integrate with the graphical user interface (GUI) toolkit (which in these cases is Qt). On the other hand, CEF is intended for use with multiple different widget toolkits (Gtk, Qt, etc.). As a developer you're supposed to clone the cef-project repository with the CEF example code — which is complex and extensive — and build your application on top of that. As is explained in the documentation, the first thing a developer needs to do is to:
The documentation assumes you're starting from scratch; it's not clear to me how you're supposed to proceed if you want to retrofit CEF into an existing application. It looks like it may not be straightforward.
Nevertheless, assuming you're starting from scratch, CEF provides a solid base to build on, since you'll start with an application that already builds, runs and displays Web content. You can then immediately see how the main classes needed for controlling the browser are used.
There are many such classes, but I've picked out three that I think are especially important for understanding what's going on. As soon as you look into one of these classes you'll find references to other classes. You may need to look into these too if you want to fully understand what's going on; with each such step I found myself getting pulled a little further into the rabbit hole.
First the CefBrowserHost class. This class is pretty key as it handles the lifespan of the browser; it's described in the source as being "used to represent the browser process aspects of a browser". Here's a flavour of what the class looks like. I've cut a lot out for the sake of brevity, but you can check out the class header if you want to see everything.
Here's the interface for the CefBrowser object the lifecycle of which is being managed (you'll find the full class header in the same file):
Once we have this root CefFrame object we can then ask for a particular page to be loaded into the frame using the LoadURL() method:
So now we've seen enough of the API to initialise things and to then load up a particular URL into a particular view. But CefFrame offers us a lot more than just that. In particular it offers up two other pieces of functionality critical for embedded browser use: it allows us to execute code within the frame and it allows us to send messages between the application and the frame.
Why are these two things so critical? In order for the content shown by the browser to feel fully integrated into the application, the application must have a means to interact with it. These two capabilities are precisely what we need to do this.
Understanding CEF requires a lot more than these three classes, but this is a supposed to be a survey, not a tutorial. Still, it would be nice to know what it's like to use these classes in practice. To that end, I've put together a simple example CEF application that makes use of some of this functionality.
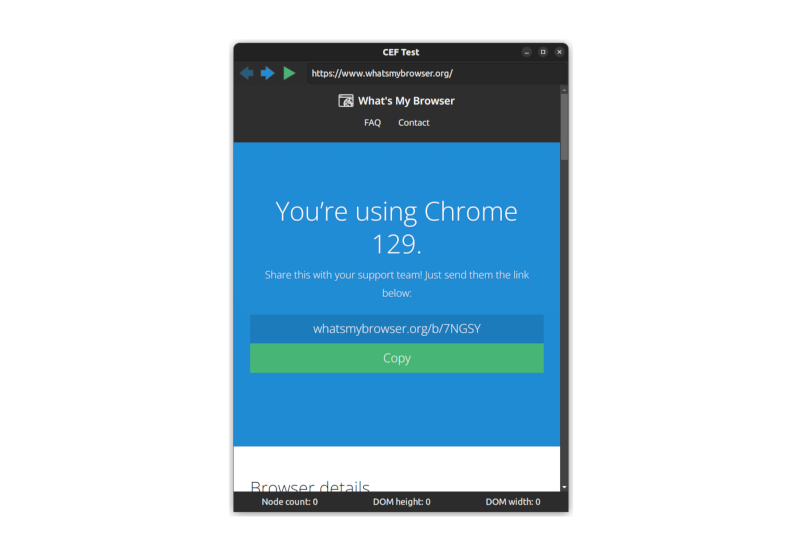
The application itself is simple and useless, but designed to capture functionality that might be repurposed for better use in other situations. The app displays a single window containing various widgets built using the native toolkit (in the case of our CEF example, these are Gtk widgets). The browser view is embedded between these widgets to demonstrate that it could potentially be embedded anywhere on the page.
The native widgets allow some limited control over the browser content: a URL bar, forwards and backwards. There's also an "execute JavaScript" button. This is the more interesting functionality. When the user presses this a small piece of JavaScript will be executed in the DOM context of the page being rendered.
Here's the JavaScript to be executed:
There is one peculiar aspect to this code though: having completed the walk and returned from collect_node_stats() the code then converts the results into a JSON string and passes the result into a function called dom_walk(). But this function doesn't exist. Huh?!
We'll come back to this.
The values that are calculated aren't really important, what is important is that we can return these values at the end and display them in the native user interface code. This highlights not only how an application can have its own code executed in the browser context, but also how the browser can communicate back information to the application. With these, we can make our browser and application feel seamlessly integrated, rather than appear as two different apps that happen to be sharing some screen real-estate.
Let's now delve in to some code and consider how our three classes are being used. We'll then move on to how the communication between app and browser is achieved.
To get the CEF example working I followed the advice in the documentation and made a fork of the cef-project repository. I then downloaded the binary install of the cef project, inside which is an example application called cefclient. I made my own copy of this inside my cef-project fork, hooked it into the CMake build files and started making changes to it.
There's a lot of code there which may look a bit overwhelming but bear in mind that the vast majority of this code is boilerplate taken directly from the example. Writing this all from scratch would have been... time consuming.
Most of the changes I did make were to the file. This handles the browser lifecycle as described above using an instance of the CefBrowserHost class.
We can see this in the RootWindowGtk::CreateRootWindow() method which is responsible for setting up the contents of the main application window. In there you'll see lots of calls for creating and arranging Gtk widgets (I love Gtk, but admittedly it can be a tad verbose). Further down in this same method we see the call to CefBrowserHost::CreateBrowser() that brings the browser component to life.
In the case of CEF the browser isn't actually a component. We tell the browser where in our window to render and it goes ahead and renders, so we actually create an empty widget and then update the browser content bounds every time the size or position of this widget changes.
This contrasts with the Qt WebEngine and Gecko WebView approach, where the embedded browser is provided as an actual widget and, consequently, the bounds are updated automatically as the widget updates. Here with CEF we have to do all this ourselves.
It's not hard to do, and it brings extra control for greater flexibility, but it also hints at why so much boilerplate code is needed.
The browser lives on until the app calls CefBrowserHost::CloseBrowser() in the event that the actual Gtk window containing it is deleted.
We already talked about the native controls in the window and the fact that we can enter a URL, as well as being able to navigate forwards and backwards through the browser history. For this functionality we use the CefBrowser object.
We can see this at work in the same file. Did I mention that this file is where most of the action happens? That's because this is the file that handles the Gtk window and all of the interactions with it.
When creating the window we set up a generic RootWindowGtk::NotifyButtonClicked() callback to handle interactions with the native Gtk widgets. Inside this we find some code to get our CefBrowser instance and call one of the navigation functions on it. The choice of which to call depends on the button that was pressed by the user:
The format is similar, but when clicked it extracts the main frame from the browser in the form of a CefFrame instance and calls the CefFrame::ExecuteJavaScript() method on this instead. Like this:
There are similar methods available for the Qt WebEngine and Gecko WebView as well. As we'll see, what makes the CEF version different is that it doesn't block the user interface thread during execution and doesn't return a value. But as we discussed above, we want to return a value, because otherwise how are we going to display the number of nodes, tree height and tree breadth in the user interface?
This is where that mysterious dom_walk() method that I mentioned earlier comes in. We're going to create this method on the C++ side so that when the JavaScript code calls it, it'll execute some C++ code rather than some JavaScript code.
We do this by extending the CefV8Handler class and overriding its CefV8Handler::Execute() method with the following code:
In JavaScript functions are just like any other value, so to get our new function into the DOM context all we need to do is create a CefV8Value object, which is the C++ name for a JavaScript value, and pass it in to the global context for the browser. We do this when the JavaScript context is created like so:
So now we've gone full circle: the user interface thread executes some JavaScript code on the render thread in the view's DOM context. This then calls a C++ method also on the render thread, which sends a message to the user interface thread, which updates the widgets to show the result.
All of the individual steps make sense in their own way, but it is, if I'm honest, a bit convoluted. I can fully understand that message passing is needed between the different threads, but it would have been nice to be able to send the message directly from the JavaScript. Although there are constraints that apply here for security reasons, the Qt WebEngine and Gecko WebView equivalents both abstract these steps away from the developer, which makes life a lot easier.
With all of this hooked up, pressing the execute JavaScript button now has the desired effect.
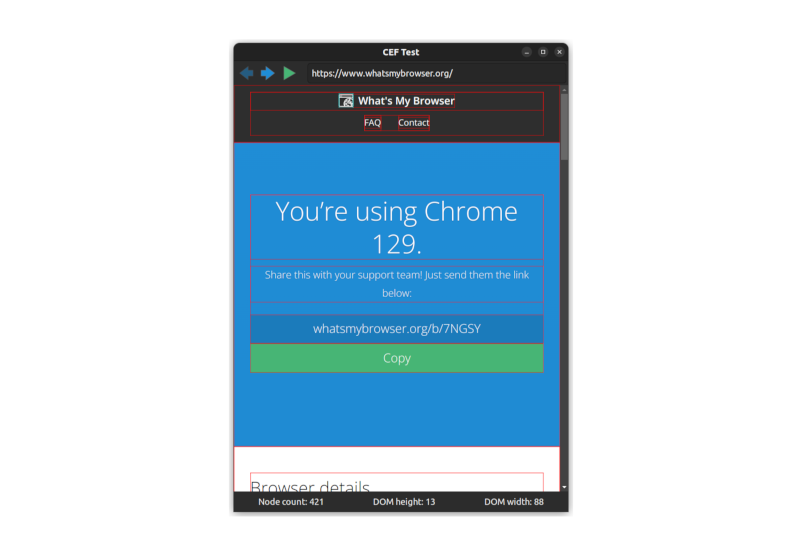
The CEF project works hard to make Blink accessible as an embedded browser, but there's still plenty of complexity to contend with. Given just the few pieces we've covered here — lifecycle, navigation, JavaScript execution and message passing — you'll likely be able to do the majority of things you might want with an embedded browser. Crucially, you can integrate the browser component seamlessly with the rest of your application.
It's powerful stuff, but it's also true to say that the other approaches I tried out managed to hide this complexity a little better. The main reason for this would seem to be because CEF doesn't target any particular widget toolkit. It can, in theory, be integrated with any toolkit, whether it be on Linux, Windows or macOS.
While that flexibility comes at a cost in terms of complexity, that hasn't stopped CEF becoming popular. It's widely used by both open source and commercial software, including the Steam client and Spotify desktop app.
In the next section we'll look at the Qt WebEngine, which provides an alternative way to embed the Blink rendering engine into your application.
Although both uses Blink, there are other important differences between the two. First, Qt WebEngine is tied to Qt. That means that all of the classes we'll look at bar one will inherit from QObject and the main user interface class will inherit from QWidget (which itself is a descendant of QObject).
While Qt is largely written in C++ and targets C++ applications, we'll also make use of QML for our example code. This will make the presentation easier, but in practice we could achieve exactly the same results using pure C++. We'd just end up with a bit more code.
So, with all that in mind, let's get to it.
The fact that Qt WebEngine exclusively targets Qt applications does make things a little simpler, both for the Qt WebEngine implementation and for our use of it. Consequently we can focus on just two classes. In practice there are many more classes that make up the API, but many of these have quite specific uses (such as interacting with items in the navigation history, or handling HTTPS certificates). All useful stuff for sure, but our aim here is just to give a flavour.
The two classes we're going to look at are QWebEnginePage and QWebEngineView. Here's an abridged version of the former:
According to the Qt documentation, the QWebEnginePage class...
That's reflected in the methods and member variables I've pulled out here. The title, url and load status of the page are all exposed by this class and it also allows us to search the page. The reference to actions in the documentation relates to the triggerAction() method. There are numerous types of WebAction that can be passed in to this. Things like Forward, Back, Reload, Copy, SavePage and so on.
You'll also notice there's a runJavaScript() method. If you've already read through the section on CEF you should have a pretty good idea about how we're planning to make use of this, but we'll talk in more detail about that later.
The other key class is QWebEngineView. This inherits from QWidget, which means we can actually embed this object in our window. It's the class that actually gets added to the user interface. It's therefore also the route through which we can interact with the QWebEnginePage page object that it holds.
There are also convenience slots for navigation (a slot is just a method that can be either called directly, or connected up to one of the signals I mentioned earlier).
And with these few classes we have what we need to create ourselves an example application. I've created something equivalent to our CEF example application described in the previous section, called WebEngineTest; all of the code for it is available on GitHub, but I'm also going to walk us through the most important parts here.
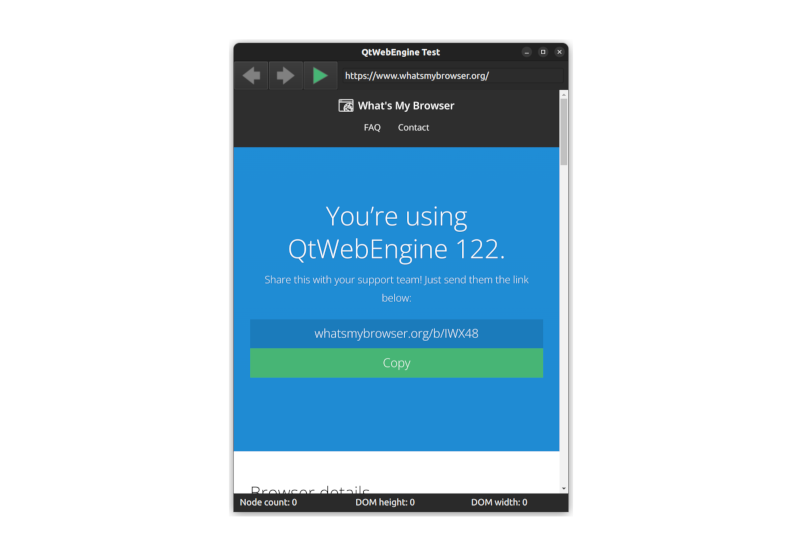
If you looked at the sprawling CEF code, you may be surprised to see how simple the Qt WebEngine equivalent is. The majority of what we need is encapsulated in this short snipped of QML code copied from the Main.qml file.
We'll take a look at the NavBar and InfoBar shortly, but let's first concentrate on the WebEngineView. It has a width set to match the width of the page and a height set to match the page height minus the size of the other widgets. We set the initial page to load and set JavaScript to be enabled, like so:
Then there's the getInfo() method that executes the following:
The method takes the JavaScript script to execute — as a string — for its first parameter and a callback that's called on completion of execution for the second parameter. Internally this is actually doing something very similar to the CEF code we saw above: it passes the code to the V8 JavaScript engine to execute inside the DOM, then waits on a message to return with the results of the call.
In our callback we simply copy the returned data into the infobar.dominfo variable, which is used to populate the widgets along the bottom of the screen.
It all looks very clean and simple. But there is some machinery needed in the background to make it all hang together. First, you may have noticed that for our script we simply pass in a domwalk variable. We set this up in the main.cpp file (which is the entrypoint of our application). There you'll see some code that looks like this:
Next up, let's take a look at the NavBar.qml file. QML automatically creates a widget named NavBar based on the name of the file, which we saw in use above as part of the main page.
Finally for the toolbar, the third button simply calls the getInfo() method that we created as part of the definition of our WebEngineView widget above. We already know what this does, but just to recap, this will execute the domwalk JavaScript inside the DOM context and store the result in the infobar.dominfo variable.
The NavButton component type used here is just a simple wrapper around the QML Button QML.
Now let's look at the code in the InfoBar.qml file:
And it works too. Clicking the execute JavaScript button will paint the elements of the page with a red border and display the stats in the infobar, just as happened with our CEF example:
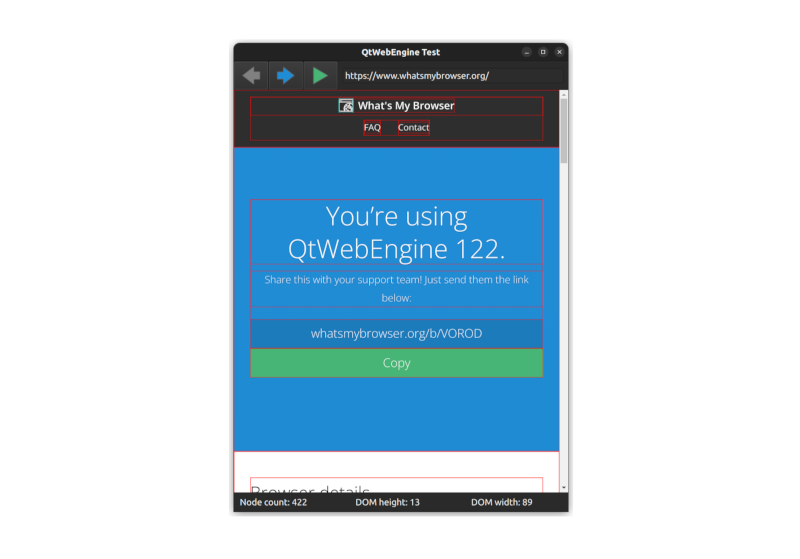
When I first started using QML this automatic updating of the fields felt counter-intuitive. In most programming languages if an expression includes a variable, the value at the point of assignment is used and the expression isn't reevaluated if the variable changes value. In QML if a variable is defined using a colon : (as opposed to an equals =) symbol, it will be bound to the variables in the expression and updated if they change. This is what's happening here: when the dominfo variable is updated, all of its dependent bound variables will be updated too. All made possible using the magical signals from earlier.
Other user interface frameworks (Svelte springs to mind) have this feature as well; when used effectively it can make for super-simple and clean code.
There's just one last piece of the puzzle, which is the domwalk code itself. I'm not going to list it here, because it's practically identical to the code we used for the CEF example, which is listed above. The only difference is the way we return the result back at the end. You can check out the DomWalk.js source file if you'd like to compare.
And that's it. This is far simpler than the code needed for CEF, although admittedly the CEF code all made perfect sense. Unlike CEF, Qt WebEngine is only intended for use with Qt. This fact, combined with the somewhat less verbose syntax of QML compared to C++, is what makes the Qt version so much more concise.
In both cases the underlying Web rendering and JavaScript execution engines are the same: Blink and V8 respectively. It's only the way the Chromium API is exposed that differs.
Let's now move on to the Sailfish WebView, which has a similar interface to Qt WebEngine but uses a different engine in the background.
Although the Sailfish WebView may therefore not be so useful outside of Sailfish OS, it's Sailfish OS that drives my interest in mobile browsers. So from my point of view it's very natural for me to include it here.
Since it's built using Qt and is exposed as a QML widget, the Sailfish WebView has many similarities with Qt WebEngine. In fact the Qt WebEngine API is itself a successor of the Qt WebView API, which was previously available on Sailfish OS and which the Sailfish WebView was developed as a replacement for.
So expect similarities. However there's also one crucial difference between the two: whereas the Qt WebEngine is built using Blink and V8, the Sailfish WebView is built using Gecko and SpiderMonkey. So in the background they're making use of completely different Web rendering engines.
Like the other two examples, all of the code is available on GitHub. The repository structure is a little different, mostly because Sailfish OS has its own build engine that's designed for generating RPM packages. Although the directory structured differs, for the parts that interest us you'll find all of the same source files across both the WebEngineTest and harbour-webviewtest.
Looking first at the Main.qml file there are only a few differences between this and the equivalent file in the WebEngineTest repository.
The DomWalk.js code is also practically identical. One difference is that we don't use structuredClone() because the engine version is slightly older. We use a trick of converting to JSON and back instead to achieve the same result. This JavaScript is loaded in the main.cpp file in the same way as for WebEngineTest.
The NavBar.qml and InfoBar.qml files are to all intents and purposes identical, so I won't copy the code out here.
And that's it. Once again, it's a pretty clean and simple implementation. It demonstrates execution of JavaScript within the DOM that's able to manipulate elements and read data from them. It also shows data being passed back from Gecko to the native app that wraps it.
Although the Sailfish WebView is uses Gecko, from the point of view of the developer and the end user there's no real difference between the API offered by Qt WebEngine and that offered by the Sailfish WebView.
For Sailfish OS users it's natural to ask whether it makes sense to continue using Gecko, rather than switching to Blink. I'm hoping this investigation will help provide an answer, but right now I just want to reflect on the fact there's very little difference from the perspective of the API consumer.
While CEF and Qt WebEngine both share the same rendering backend, their APIs are quite different, at least when it comes to the specifics. But in fact, the functionalities exposed by both are similar.
The Sailfish WebView on the other hand uses completely different engines — Gecko and SpiderMonkey — and yet, in spite of this the WebView API is really very similar to the Qt WebEngine API.
So as a developer, why choose one of them over the other? When it comes to the WebEngine and the WebView the answer is happily straightforward: since they support different, non-overlapping platforms, if you're using Sailfish OS consider using the WebView; if you're not it's the WebEngine you should look at.
To wrap things up, lets consider the core functionalities the APIs provide. Although each has its own quirks, fundamentally they offer something similar:
At the start I said I'd consider whether Gecko is still appropriate for use by Sailfish OS for its embedded browser. This is an important question that we're now closer to having a clearer answer to. I'll take a look at this in more detail in a future post.
Comment
Indeed, for many years WebKit was also an integral part of Sailfish OS, providing the embeddable QtWebKit widget that many other apps used as a way of rendering Web content. It wasn't until Sailfish OS 4.2.0 that this was officially replaced by the Gecko-based WebView API.
The coexistence of multiple engines within the operating system isn't the only reason many people felt WebKit would make a better alternative to Gecko. Another is the fact that WebKit, and subsequently Blink, has become the defacto standard for embedded applications. In contrast, although Mozilla were pushing embedded support back when Maemo was being developed, it's since dropped official embedded support entirely.
So in this post I'm going to take a look at embedded browsers. What does it mean for a browser to be embedded, what APIs are supported by the most widely used embedded toolkits, and might it be true that Sailfish OS would be better off using Blink? In fact, I'll be leaving this last question for a future post, but my hope is that the discussion in this post will serve as useful groundwork.
Let's start by figuring out what an embedded browser actually is. In my mind there are two main definitions, each embracing a slightly different set of characteristics.
- A browser that runs on an embedded device.
- A browser that can be embedded in another application.
If you frame it right though, these two definitions can feel similar. Here's how the Web Platform for Embedded team describe it:
For many of us, a browser is an application like the one you’re probably using now. You click an icon on your graphical operating system (OS), navigate somewhere with a URL bar, search, and so on. You have bookmarks and tabs that you can drag around, and lots of other features.
In contrast, an embedded browser is contained within another application or is built for a specific purpose and runs in an embedded system, and the application controlling the embedded browser does not provide all the typical features of browsers running in desktops.
In contrast, an embedded browser is contained within another application or is built for a specific purpose and runs in an embedded system, and the application controlling the embedded browser does not provide all the typical features of browsers running in desktops.
So minimal, encapsulated, targeted. Maybe something you don't even realise is a browser.
And what does this mean in practice? That might be a little hard to pin down, but for me it's all about the API. What API does the browser expose for use by other applications and systems? If it provides bare-bones render output, but with enough hooks to build a complete browser on top of (at a minimum) then you've got yourself an effective embedded browser.
In the past Gecko provided exactly this in the form of the EmbedLIte API and the XULRunner Development Kit. The former provides a set of APIs that allow Gecko to be embedded in other applications. The latter allows the Gecko build process to be harnessed in order to output all of the libraries and artefacts needed (such as the libxul.so library and the omni.ja resource archive) to integrate Gecko into another application.
Sadly Mozilla dropped support for both of these back in 2016, when it was decided the core Firefox browser needed to be prioritised over an embedding offering. Mozilla has made plenty of questionable decisions over the years and given the rise in use of WebKit and Chrome as embedded browsers, you might think this was one of them. But despite the lack of investment in the API, it's not been removed entirely, to Mozilla's credit. It is, in fact, still possible to access the EmbedLite APIs and to generate the XULRunner artefacts and get a very effective embedded browser.
We'll come back to the EmbedLite approach to embedding later. But in order to understand it better, I believe it's also helpful to understand the context. I therefore plan to look at three different embedded browser frameworks. These are CEF (the Chromium Embedded Framework), Qt WebEngine and then finally we'll return to Gecko by considering the Gecko WebView.
Looking through the documentation I was surprised at how similar these three frameworks appear to be. But trying them out I was quickly divested of this misapprehension. They do offer similar functionality, but turn out to be quite different to use in practice.
Before we get in to the API details, let's first consider what a minimal embedded browser external interface might look like.
- Settings controller. An API, likely exposed as a class, to control browser settings such as cache and profile location, scaling, user agent string, privacy settings and so on. Browsers typically offer numerous configuration options and some of these such as profile location are especially important for the embedded case.
- JavaScript execution. Apps that embed a browser often have particular use-cases in mind. The ability to execute JavaScript is important for allowing interaction between the rendered Web content and the rest of the application (see also message passing interface).
- Web controls. There are a bunch of controls that are needed as a bare minimum for controlling browser content. Load URL; navigate forwards; navigate backwards; that kind of thing. An app that embeds a browser may choose to handle these controls itself, potentially hiding them from the user entirely, but at the very least the app has to be able to access these controls programmatically from its own code.
- Separate view widgets. The browser is an engine and often an app will want multiple views all of which make use of it, each rendering different content. An embedding framework should allow an app to embed multiple views, each making use of the same engine underneath.
- Message passing interface. The app and the browser need a way to communicate with one another. Browsers already work by broadcasting messages between different components, so there should be a way for the embedder to send and receive these messages as well. A common use case will involve the embedder injecting some JavaScript, with communication handled by message passing between the app and the JavaScript. The app can then act on the messages sent from inside the browser engine by the JavaScript.
- Populate a settings structure for the browser to capture the settings in an object.
- Instantiate a bunch of singleton browser classes. These will be for central management of the browser components.
- Pass in the settings object to these central browser components.
- Embed one or more browser widget into the user interface to create browser views.
- Inject some JavaScript into the browser views. This JavaScript listens for messages from the app, interacts with the browser content and sends messages back.
- Open the window containing the browser widget for the user.
- Interact with the JavaScript and browser engine by passing messages via the message passing interface.
- When the user closes the window, shut down the views.
Let's now turn to the three individual embedding frameworks to see how they approach all this.
CEF
Let's start by considering the CEF API as documented. I actually began by looking at the Blink source code, but it turns out this isn't set up well for easy integration into other projects. I should caveat this: the underlying structure may be carefully arranged to support it, but the Blink project itself doesn't seem to prioritise streamlining the process of embedding. For example it exposes the entire internal API with no simplified embedding wrapper and I didn't find good official documentation on the topic.And that's exactly how CEF brings value. It takes the Chromium internals (Blink, V8, etc.) and wraps them with the basic windowing scaffolding needed to get a browser working across multiple platforms (Linux, Windows, macOS). It then adds in a streamlined interface for controlling the most important features needed for embedding (settings, browser controls, JavaScript injection, message passing).
Having worked through the documentation and tutorials, the CEF project assumes a slightly different workflow from what I'd typically expect. Qt WebEngine and Gecko WebView are both provided as widgets that integrate with the graphical user interface (GUI) toolkit (which in these cases is Qt). On the other hand, CEF is intended for use with multiple different widget toolkits (Gtk, Qt, etc.). As a developer you're supposed to clone the cef-project repository with the CEF example code — which is complex and extensive — and build your application on top of that. As is explained in the documentation, the first thing a developer needs to do is to:
Fork the cef-project repository using Bitbucket and Git to store the source code for your own CEF-based project.
The documentation assumes you're starting from scratch; it's not clear to me how you're supposed to proceed if you want to retrofit CEF into an existing application. It looks like it may not be straightforward.
Nevertheless, assuming you're starting from scratch, CEF provides a solid base to build on, since you'll start with an application that already builds, runs and displays Web content. You can then immediately see how the main classes needed for controlling the browser are used.
There are many such classes, but I've picked out three that I think are especially important for understanding what's going on. As soon as you look into one of these classes you'll find references to other classes. You may need to look into these too if you want to fully understand what's going on; with each such step I found myself getting pulled a little further into the rabbit hole.
First the CefBrowserHost class. This class is pretty key as it handles the lifespan of the browser; it's described in the source as being "used to represent the browser process aspects of a browser". Here's a flavour of what the class looks like. I've cut a lot out for the sake of brevity, but you can check out the class header if you want to see everything.
class CefBrowserHost : public CefBaseRefCounted {
public:
static bool CreateBrowser(const CefWindowInfo& windowInfo,
CefRefPtr<CefClient> client,
const CefString& url,
const CefBrowserSettings& settings,
CefRefPtr<CefDictionaryValue> extra_info,
CefRefPtr<CefRequestContext> request_context);
CefRefPtr<CefBrowser> GetBrowser();
void CloseBrowser(bool force_close);
[...]
void StartDownload(const CefString& url);
void PrintToPDF(const CefString& path,
const CefPdfPrintSettings& settings,
CefRefPtr<CefPdfPrintCallback> callback);
void Find(const CefString& searchText,
bool forward,
bool matchCase,
bool findNext);
void StopFinding(bool clearSelection);
bool IsFullscreen();
void ExitFullscreen(bool will_cause_resize);
[...]
};
As a developer you call CreateBrowser() to start up your browser, which you can then access using GetBrowser(). Once you're done you can destroy it using CloseBrowser(). All of these are accessed via this CefBrowserHost interface. As you can see, there are also a bunch of browser-wide functionalities (search, fullscreen mode, printing, etc.) that are also managed through CefBrowserHost.Here's the interface for the CefBrowser object the lifecycle of which is being managed (you'll find the full class header in the same file):
class CefBrowser : public CefBaseRefCounted {
public:
bool CanGoBack();
void GoBack();
bool CanGoForward();
void GoForward();
bool IsLoading();
void Reload();
void StopLoad();
bool HasDocument();
CefRefPtr<CefFrame> GetMainFrame();
[...]
};
Things are starting to look a lot more familiar now, with methods to perform Web navigation and the like. Notice however that we still haven't reached the interface for loading a specific URL yet. For that we need a CefFrame which the source code describes as being "used to represent a frame in the browser window.". A page can be made up of multiple such frames, but there's always a root frame which we can extract from the browser using the GetMainFrame() method you see above.Once we have this root CefFrame object we can then ask for a particular page to be loaded into the frame using the LoadURL() method:
class CefFrame : public CefBaseRefCounted {
public:
CefRefPtr<CefBrowser> GetBrowser();
void LoadURL(const CefString& url);
CefString GetURL();
CefString GetName();
void Cut();
void Copy();
void Paste();
void ExecuteJavaScript(const CefString& code,
const CefString& script_url,
int start_line);
void SendProcessMessage(CefProcessId target_process,
CefRefPtr<CefProcessMessage> message);
[...]
};
The full definition of CefFrame can be seen in the cef_frame.h header file.So now we've seen enough of the API to initialise things and to then load up a particular URL into a particular view. But CefFrame offers us a lot more than just that. In particular it offers up two other pieces of functionality critical for embedded browser use: it allows us to execute code within the frame and it allows us to send messages between the application and the frame.
Why are these two things so critical? In order for the content shown by the browser to feel fully integrated into the application, the application must have a means to interact with it. These two capabilities are precisely what we need to do this.
Understanding CEF requires a lot more than these three classes, but this is a supposed to be a survey, not a tutorial. Still, it would be nice to know what it's like to use these classes in practice. To that end, I've put together a simple example CEF application that makes use of some of this functionality.
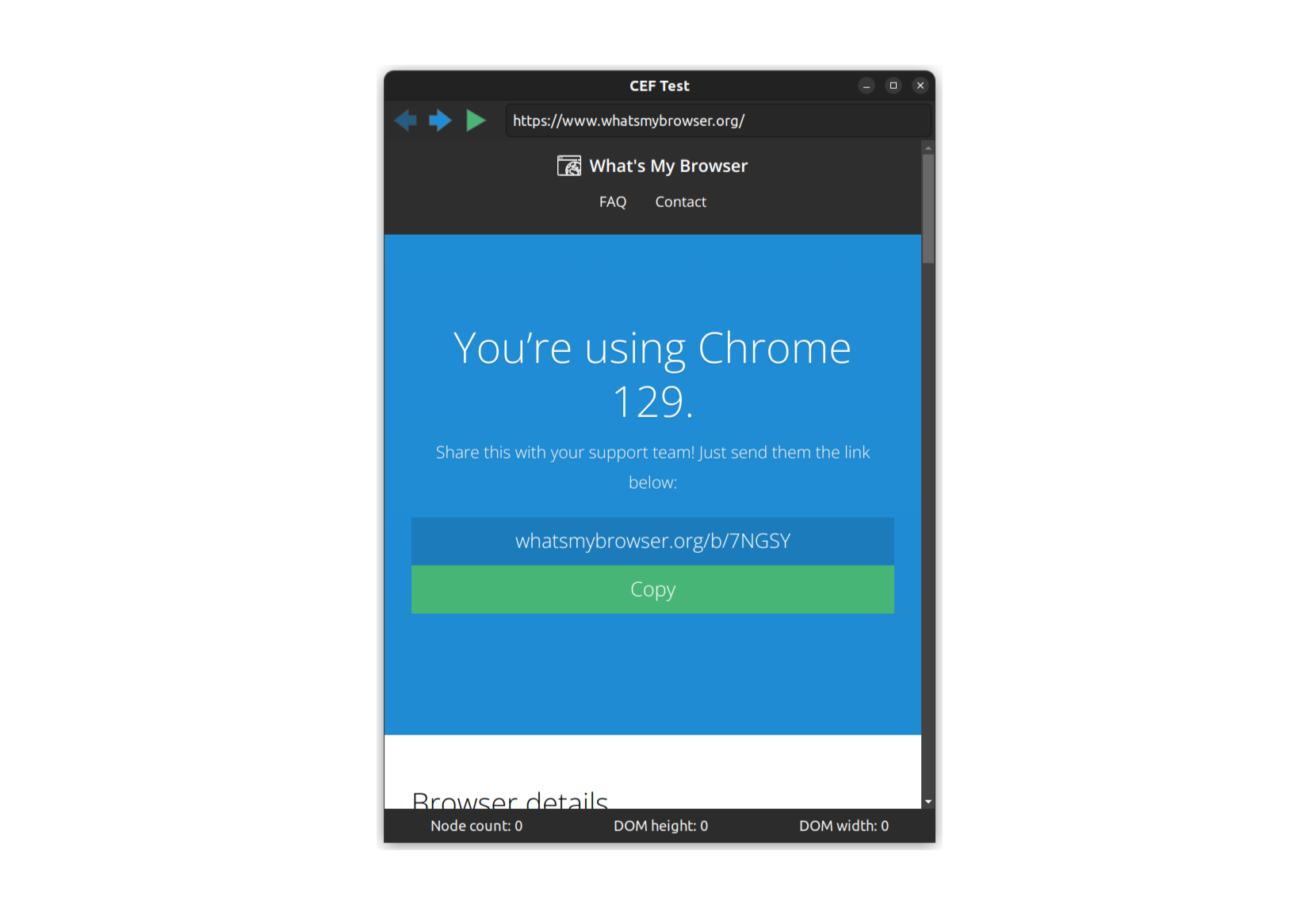
The application itself is simple and useless, but designed to capture functionality that might be repurposed for better use in other situations. The app displays a single window containing various widgets built using the native toolkit (in the case of our CEF example, these are Gtk widgets). The browser view is embedded between these widgets to demonstrate that it could potentially be embedded anywhere on the page.
The native widgets allow some limited control over the browser content: a URL bar, forwards and backwards. There's also an "execute JavaScript" button. This is the more interesting functionality. When the user presses this a small piece of JavaScript will be executed in the DOM context of the page being rendered.
Here's the JavaScript to be executed:
function collect_node_stats(global_context, local_context, node) {
// Update the context
local_context.depth += 1;
local_context.breadth.push(node.childNodes.length);
global_context.nodes += 1;
global_context.maxdepth = Math.max(local_context.depth,
global_context.maxdepth);
// Recurse into child nodes
for (child of node.childNodes) {
child_context = structuredClone(local_context);
child_context.breadth = local_context.breadth.slice(0, local_context.depth
+ 1);
child_context = collect_node_stats(global_context, child_context, child);
// Recalculate the child breadths
for (let i = local_context.depth + 1; i < child_context.breadth.length;
++i) {
local_context.breadth[i] = (local_context.breadth[i]||0) +
child_context.breadth[i];
}
}
// Paint the DOM red
if (node.style) {
node.style.boxShadow = "inset 0px 0px 1px 0.5px red";
}
// Move back up the tree
local_context.depth -= 1;
return local_context;
}
function node_stats() {
// Data available to all nodes
let global_context = {
"nodes": 0,
"maxdepth": 0,
"maxbreadth": 0
}
// Data that's local to the node and shared with the parent
let local_context = {
"depth": 0,
"breadth": [1]
}
// Off we go
local_context = collect_node_stats(global_context, local_context, document);
global_context.maxbreadth = Math.max.apply(null, local_context.breadth);
return global_context;
}
// Return the results (only strings allowed)
// See: DomWalkHandler::Execute() defined in renderer/client_renderer.cc
dom_walk(JSON.stringify(node_stats()))
I'm including all of it here because it's not too long, but there's no need to go through this line-by-line. All it does is walk the page DOM tree, giving each item in the DOM a red border and collecting some statistics as it goes. As it goes along it collects information that allows us to calculate the number of nodes, the maximum height of the DOM tree and the maximum breadth of the DOM tree.There is one peculiar aspect to this code though: having completed the walk and returned from collect_node_stats() the code then converts the results into a JSON string and passes the result into a function called dom_walk(). But this function doesn't exist. Huh?!
We'll come back to this.
The values that are calculated aren't really important, what is important is that we can return these values at the end and display them in the native user interface code. This highlights not only how an application can have its own code executed in the browser context, but also how the browser can communicate back information to the application. With these, we can make our browser and application feel seamlessly integrated, rather than appear as two different apps that happen to be sharing some screen real-estate.
Let's now delve in to some code and consider how our three classes are being used. We'll then move on to how the communication between app and browser is achieved.
To get the CEF example working I followed the advice in the documentation and made a fork of the cef-project repository. I then downloaded the binary install of the cef project, inside which is an example application called cefclient. I made my own copy of this inside my cef-project fork, hooked it into the CMake build files and started making changes to it.
There's a lot of code there which may look a bit overwhelming but bear in mind that the vast majority of this code is boilerplate taken directly from the example. Writing this all from scratch would have been... time consuming.
Most of the changes I did make were to the file. This handles the browser lifecycle as described above using an instance of the CefBrowserHost class.
We can see this in the RootWindowGtk::CreateRootWindow() method which is responsible for setting up the contents of the main application window. In there you'll see lots of calls for creating and arranging Gtk widgets (I love Gtk, but admittedly it can be a tad verbose). Further down in this same method we see the call to CefBrowserHost::CreateBrowser() that brings the browser component to life.
In the case of CEF the browser isn't actually a component. We tell the browser where in our window to render and it goes ahead and renders, so we actually create an empty widget and then update the browser content bounds every time the size or position of this widget changes.
This contrasts with the Qt WebEngine and Gecko WebView approach, where the embedded browser is provided as an actual widget and, consequently, the bounds are updated automatically as the widget updates. Here with CEF we have to do all this ourselves.
It's not hard to do, and it brings extra control for greater flexibility, but it also hints at why so much boilerplate code is needed.
The browser lives on until the app calls CefBrowserHost::CloseBrowser() in the event that the actual Gtk window containing it is deleted.
We already talked about the native controls in the window and the fact that we can enter a URL, as well as being able to navigate forwards and backwards through the browser history. For this functionality we use the CefBrowser object.
We can see this at work in the same file. Did I mention that this file is where most of the action happens? That's because this is the file that handles the Gtk window and all of the interactions with it.
When creating the window we set up a generic RootWindowGtk::NotifyButtonClicked() callback to handle interactions with the native Gtk widgets. Inside this we find some code to get our CefBrowser instance and call one of the navigation functions on it. The choice of which to call depends on the button that was pressed by the user:
CefRefPtr<CefBrowser> browser = GetBrowser();
if (!browser.get()) {
return;
}
switch (id) {
case IDC_NAV_BACK:
browser->GoBack();
break;
case IDC_NAV_FORWARD:
browser->GoForward();
[...]
Earlier we mentioned that we also have this special execute JavaScript button. I've hooked this up slightly differently, so that it has its own callback for when clicked.The format is similar, but when clicked it extracts the main frame from the browser in the form of a CefFrame instance and calls the CefFrame::ExecuteJavaScript() method on this instead. Like this:
void RootWindowGtk::DomWalkButtonClicked(GtkButton* button,
RootWindowGtk* self) {
CefRefPtr<CefBrowser> browser = self->GetBrowser();
if (browser.get()) {
CefRefPtr<CefFrame> frame = browser->GetMainFrame();
frame->ExecuteJavaScript(self->dom_walk_js_, "", 0);
}
}
The dom_walk_js_ member is just a string buffer containing the contents of our JavaScript file (which I load at app start up). As the method name implies, calling ExecuteJavaScript() will immediately execute the provided JavaScript code in the view's DOM context, starting execution from the line provided.There are similar methods available for the Qt WebEngine and Gecko WebView as well. As we'll see, what makes the CEF version different is that it doesn't block the user interface thread during execution and doesn't return a value. But as we discussed above, we want to return a value, because otherwise how are we going to display the number of nodes, tree height and tree breadth in the user interface?
This is where that mysterious dom_walk() method that I mentioned earlier comes in. We're going to create this method on the C++ side so that when the JavaScript code calls it, it'll execute some C++ code rather than some JavaScript code.
We do this by extending the CefV8Handler class and overriding its CefV8Handler::Execute() method with the following code:
bool DomWalkHandler::Execute(const CefString& name,
CefRefPtr<CefV8Value> object,
const CefV8ValueList& arguments,
CefRefPtr<CefV8Value>& retval,
CefString& exception) {
if (!arguments.empty()) {
// Create the message object.
CefRefPtr<CefProcessMessage> msg = CefProcessMessage::Create(
"dom_walk");
// Retrieve the argument list object.
CefRefPtr<CefListValue> args = msg->GetArgumentList();
// Populate the argument values.
args->SetString(0, arguments[0]->GetStringValue());
// Send the process message to the main frame in the render process.
// Use PID_BROWSER instead when sending a message to the browser process.
browser->GetMainFrame()->SendProcessMessage(PID_BROWSER, msg);
}
return true;
}
This code is going to execute on the render thread, so we still need to get our result to the user interface thread. I say "thread", but it could even be a different process. So this is where the SendProcessMessage() call at the end of this code snippet comes in. The purpose of this is to create a message with a payload made up of the arguments passed in to the dom_walk() method (which, if you'll recall, is a stringified JSON structure). We then send this as a message to the browser process.In JavaScript functions are just like any other value, so to get our new function into the DOM context all we need to do is create a CefV8Value object, which is the C++ name for a JavaScript value, and pass it in to the global context for the browser. We do this when the JavaScript context is created like so:
void OnContextCreated(CefRefPtr<ClientAppRenderer> app,
CefRefPtr<CefBrowser> browser,
CefRefPtr<CefFrame> frame,
CefRefPtr<CefV8Context> context) override {
message_router_->OnContextCreated(browser, frame, context);
if (!dom_walk_handler) {
dom_walk_handler = new DomWalkHandler(browser);
}
CefRefPtr<CefV8Context> v8_context = frame->GetV8Context();
if (v8_context.get() && v8_context->Enter()) {
CefRefPtr<CefV8Value> global = v8_context->GetGlobal();
CefRefPtr<CefV8Value> dom_walk = CefV8Value::CreateFunction(
"dom_walk", dom_walk_handler);
global->SetValue("dom_walk", dom_walk,
V8_PROPERTY_ATTRIBUTE_READONLY);
CefV8ValueList args;
dom_walk->ExecuteFunction(global, args);
v8_context->Exit();
}
}
Finally in our browser thread we set up a message handler to listen for when the dom_walk message is received from the render thread.
if (message_name == "dom_walk") {
if (delegate_) {
delegate_->OnSetDomWalkResult(message->GetArgumentList()->GetString(0));
}
}
Back in our root_window_gtk.cc file is the implementation of OnSetDomWalkResult() which takes the string passed to it, parses it and displays the content in our info bar at the bottom of the window:
void RootWindowGtk::OnSetDomWalkResult(const std::string& result) {
CefRefPtr<CefValue> parsed = CefParseJSON(result,
JSON_PARSER_ALLOW_TRAILING_COMMAS);
int nodes = parsed->GetDictionary()->GetInt("nodes");
int maxdepth = parsed->GetDictionary()->GetInt("maxdepth");
int maxbreadth = parsed->GetDictionary()->GetInt("maxbreadth");
gchar* nodes_str = g_strdup_printf("Node count: %d", nodes);
gtk_label_set_text(GTK_LABEL(count_label_), nodes_str);
g_free(nodes_str);
gchar* maxdepth_str = g_strdup_printf("DOM height: %d", maxdepth);
gtk_label_set_text(GTK_LABEL(height_label_), maxdepth_str);
g_free(maxdepth_str);
gchar* maxbreadth_str = g_strdup_printf("DOM width: %d",
maxbreadth);
gtk_label_set_text(GTK_LABEL(width_label_), maxbreadth_str);
g_free(maxbreadth_str);
}
As you can see, most of this final piece of the puzzle is just calling the Gtk code needed to update the user interface.So now we've gone full circle: the user interface thread executes some JavaScript code on the render thread in the view's DOM context. This then calls a C++ method also on the render thread, which sends a message to the user interface thread, which updates the widgets to show the result.
All of the individual steps make sense in their own way, but it is, if I'm honest, a bit convoluted. I can fully understand that message passing is needed between the different threads, but it would have been nice to be able to send the message directly from the JavaScript. Although there are constraints that apply here for security reasons, the Qt WebEngine and Gecko WebView equivalents both abstract these steps away from the developer, which makes life a lot easier.
With all of this hooked up, pressing the execute JavaScript button now has the desired effect.
The CEF project works hard to make Blink accessible as an embedded browser, but there's still plenty of complexity to contend with. Given just the few pieces we've covered here — lifecycle, navigation, JavaScript execution and message passing — you'll likely be able to do the majority of things you might want with an embedded browser. Crucially, you can integrate the browser component seamlessly with the rest of your application.
It's powerful stuff, but it's also true to say that the other approaches I tried out managed to hide this complexity a little better. The main reason for this would seem to be because CEF doesn't target any particular widget toolkit. It can, in theory, be integrated with any toolkit, whether it be on Linux, Windows or macOS.
While that flexibility comes at a cost in terms of complexity, that hasn't stopped CEF becoming popular. It's widely used by both open source and commercial software, including the Steam client and Spotify desktop app.
In the next section we'll look at the Qt WebEngine, which provides an alternative way to embed the Blink rendering engine into your application.
Qt WebEngine
In the last section we looked at CEF for embedding Blink into an application with minimal restrictions on the choice of GUI framework. We'll follow a similar approach as we investigate Qt WebEngine: first looking at the API, then seeing how we can apply it in practice.Although both uses Blink, there are other important differences between the two. First, Qt WebEngine is tied to Qt. That means that all of the classes we'll look at bar one will inherit from QObject and the main user interface class will inherit from QWidget (which itself is a descendant of QObject).
While Qt is largely written in C++ and targets C++ applications, we'll also make use of QML for our example code. This will make the presentation easier, but in practice we could achieve exactly the same results using pure C++. We'd just end up with a bit more code.
So, with all that in mind, let's get to it.
The fact that Qt WebEngine exclusively targets Qt applications does make things a little simpler, both for the Qt WebEngine implementation and for our use of it. Consequently we can focus on just two classes. In practice there are many more classes that make up the API, but many of these have quite specific uses (such as interacting with items in the navigation history, or handling HTTPS certificates). All useful stuff for sure, but our aim here is just to give a flavour.
The two classes we're going to look at are QWebEnginePage and QWebEngineView. Here's an abridged version of the former:
class QWebEnginePage : public QObject
{
Q_PROPERTY(QUrl requestedUrl...)
Q_PROPERTY(qreal zoomFactor...)
Q_PROPERTY(QString title..)
Q_PROPERTY(QUrl url READ...)
Q_PROPERTY(bool loading...)
[...]
public:
explicit QWebEnginePage(QObject *parent);
virtual void triggerAction(WebAction action, bool checked);
void findText(const QString &subString, FindFlags options,
const std::function<void(const QWebEngineFindTextResult &)>
&resultCallback));
void load(const QUrl &url);
void download(const QUrl &url, const QString &filename);
void runJavaScript(const QString &scriptSource,
const std::function<void(const QVariant &)> &resultCallback);
void fullScreenRequested(QWebEngineFullScreenRequest fullScreenRequest);
[...]
};
If you're not familiar with Qt those Q_PROPERTY macros at the top of the class may be a bit confusing. These introduce scaffolding for setters and getters of a named class variable. The developer still has to define and implement the setter and getter methods in the class. However properties come with a signal method which other methods can connect to. When the value of a property changes, the connected method is called, allowing for immediate reactions to be coded in whenever the property updates.According to the Qt documentation, the QWebEnginePage class...
holds the contents of an HTML document, the history of navigated links, and actions.
That's reflected in the methods and member variables I've pulled out here. The title, url and load status of the page are all exposed by this class and it also allows us to search the page. The reference to actions in the documentation relates to the triggerAction() method. There are numerous types of WebAction that can be passed in to this. Things like Forward, Back, Reload, Copy, SavePage and so on.
You'll also notice there's a runJavaScript() method. If you've already read through the section on CEF you should have a pretty good idea about how we're planning to make use of this, but we'll talk in more detail about that later.
The other key class is QWebEngineView. This inherits from QWidget, which means we can actually embed this object in our window. It's the class that actually gets added to the user interface. It's therefore also the route through which we can interact with the QWebEnginePage page object that it holds.
class QWebEngineView : public QWidget
{
Q_PROPERTY(QString title...)
Q_PROPERTY(QUrl url...)
Q_PROPERTY(QString selectedText...)
Q_PROPERTY(bool hasSelection...)
Q_PROPERTY(qreal zoomFactor...)
[...]
public:
explicit QWebEngineView(QWidget *parent);
QWebEnginePage *page() const;
void setPage(QWebEnginePage *page);
void load(const QUrl &url);
void findText(const QString &subString, FindFlags options,
const std::function<void(const QWebEngineFindTextResult &)>
&resultCallback);
QWebEngineSettings *settings() const;
void printToPdf(const QString &filePath, const QPageLayout &layout,
const QPageRanges &ranges);
[...]
public slots:
void stop();
void back();
void forward();
void reload();
[...]
};
Notice the interface includes a setter and getter for the QWebEnginePage object. Some of the page functionality is duplicated (for convenience as far as I can tell). We can also get access to the QWebEngineSettings object through this view, which allows us to configure similar browser settings to those we might find on the settings page of an actual browser.There are also convenience slots for navigation (a slot is just a method that can be either called directly, or connected up to one of the signals I mentioned earlier).
And with these few classes we have what we need to create ourselves an example application. I've created something equivalent to our CEF example application described in the previous section, called WebEngineTest; all of the code for it is available on GitHub, but I'm also going to walk us through the most important parts here.
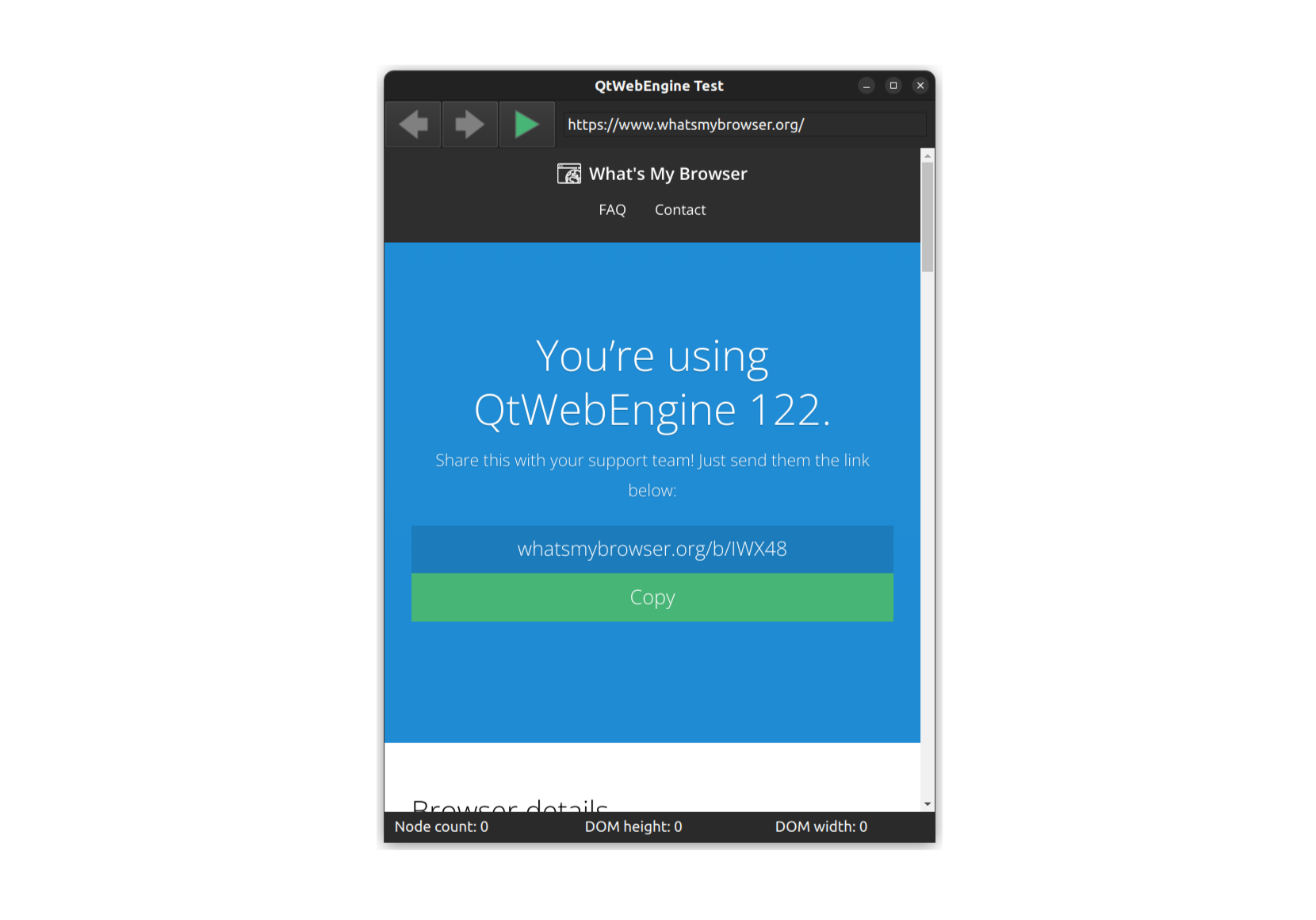
If you looked at the sprawling CEF code, you may be surprised to see how simple the Qt WebEngine equivalent is. The majority of what we need is encapsulated in this short snipped of QML code copied from the Main.qml file.
Column {
anchors.fill: parent
NavBar {
id: toolbar
webview: webview
width: parent.width
}
WebEngineView {
id: webview
width: parent.width
height: parent.height - toolbar.height - infobar.height
url: "https://www.whatsmybrowser.org"
onUrlChanged: toolbar.urltext.text = url
settings.javascriptEnabled: true
function getInfo() {
runJavaScript(domwalk, function(result) {
infobar.dominfo = JSON.parse(result);
});
}
}
InfoBar {
id: infobar
}
}
This column fills the entire application window and essentially makes up the complete user interface for our application. The column contains three rows. At the top and bottom are a NavBar widget and an InfoBar widget respectively. Nestled between the two is a WebEngineView component, which is an instance of the class with the same name that we described above.We'll take a look at the NavBar and InfoBar shortly, but let's first concentrate on the WebEngineView. It has a width set to match the width of the page and a height set to match the page height minus the size of the other widgets. We set the initial page to load and set JavaScript to be enabled, like so:
settings.javascriptEnabled: trueAs it happens JavaScript is enabled by default, so this line is redundant. It's there as a demonstration of how we can interact with the elements inside the QWebEngineSettings component we saw above.
Then there's the getInfo() method that executes the following:
runJavaScript(domwalk, function(result) {
infobar.dominfo = JSON.parse(result);
});
These three lines of code are performing all of the complex message passing steps that we described at length for the CEF example. We call runJavaScript() which is provided by the QML interface as a shortcut to the method from QWebEnginePage.The method takes the JavaScript script to execute — as a string — for its first parameter and a callback that's called on completion of execution for the second parameter. Internally this is actually doing something very similar to the CEF code we saw above: it passes the code to the V8 JavaScript engine to execute inside the DOM, then waits on a message to return with the results of the call.
In our callback we simply copy the returned data into the infobar.dominfo variable, which is used to populate the widgets along the bottom of the screen.
It all looks very clean and simple. But there is some machinery needed in the background to make it all hang together. First, you may have noticed that for our script we simply pass in a domwalk variable. We set this up in the main.cpp file (which is the entrypoint of our application). There you'll see some code that looks like this:
QString domwalk;
QFile file(":/js/DomWalk.js");
if (file.open(QIODevice::ReadOnly)) {
domwalk = file.readAll();
file.close();
}
engine.rootContext()->setContextProperty("domwalk", domwalk);
This is C++ code that simply loads the file from disk, stores it in the domwalk string and then adds the domwalk variable to the QML context. Doing this essentially makes domwalk globally accessible in all the QML code. If we were writing a larger more complex application we might approach this differently, but it's fine here for the purposes of demonstration.Next up, let's take a look at the NavBar.qml file. QML automatically creates a widget named NavBar based on the name of the file, which we saw in use above as part of the main page.
Row {
height: 48
property WebEngineView webview
property alias urltext: urltext
NavButton {
icon.source: "../icons/back.png"
onClicked: webview.goBack()
enabled: webview.canGoBack
}
NavButton {
icon.source: "../icons/forward.png"
onClicked: webview.goForward()
enabled: webview.canGoForward
}
NavButton {
icon.source: "../icons/execute.png"
onClicked: webview.getInfo()
}
Item {
width: 8
height: parent.height
}
TextField {
id: urltext
y: (parent.height - height) / 2
text: webview.url
width: parent.width - (parent.height * 3.6) - 16
color: palette.windowText
onAccepted: webview.url = text
}
}
As we can see, the toolbar is a row of five widgets. Three buttons, a spacer and the URL text field. The first two buttons simply call the goBack() and goForward() methods on our QWebEngineView class. The only other thing of note is that we also enable or disable the buttons based on the status of the canGoBack and canGoForward properties. This is where the signals we discussed earlier come in: when these variables change, they will output signals which are bound to these properties so that the change is propagated throughout the user interface. That's a Qt thing and it works really nicely for user interface development.Finally for the toolbar, the third button simply calls the getInfo() method that we created as part of the definition of our WebEngineView widget above. We already know what this does, but just to recap, this will execute the domwalk JavaScript inside the DOM context and store the result in the infobar.dominfo variable.
The NavButton component type used here is just a simple wrapper around the QML Button QML.
Now let's look at the code in the InfoBar.qml file:
Row {
height: 32
anchors.horizontalCenter: parent.horizontalCenter
property var dominfo: {
"nodes": 0,
"maxdepth": 0,
"maxbreadth": 0
}
InfoText {
text: qsTr("Node count: %1").arg(dominfo.nodes)
}
InfoText {
text: qsTr("DOM height: %1").arg(dominfo.maxdepth)
}
InfoText {
text: qsTr("DOM width: %1").arg(dominfo.maxbreadth)
}
}
The overall structure here is similar: it's a row of widgets, in this case three of them, each a text label. The InfoText component is another simple wrapper, this time around a QML Text widget. As you can see the details shown in each text label are pulled in from the dominfo variable. Recall that when the domwalk JavaScript code completes execution, the callback will store the resulting structure into the dominfo variable we see here. This will cause the nodes, maxdepth and maxbreadth fields to be updated, which will in turn cause the labels to be updated as well.And it works too. Clicking the execute JavaScript button will paint the elements of the page with a red border and display the stats in the infobar, just as happened with our CEF example:
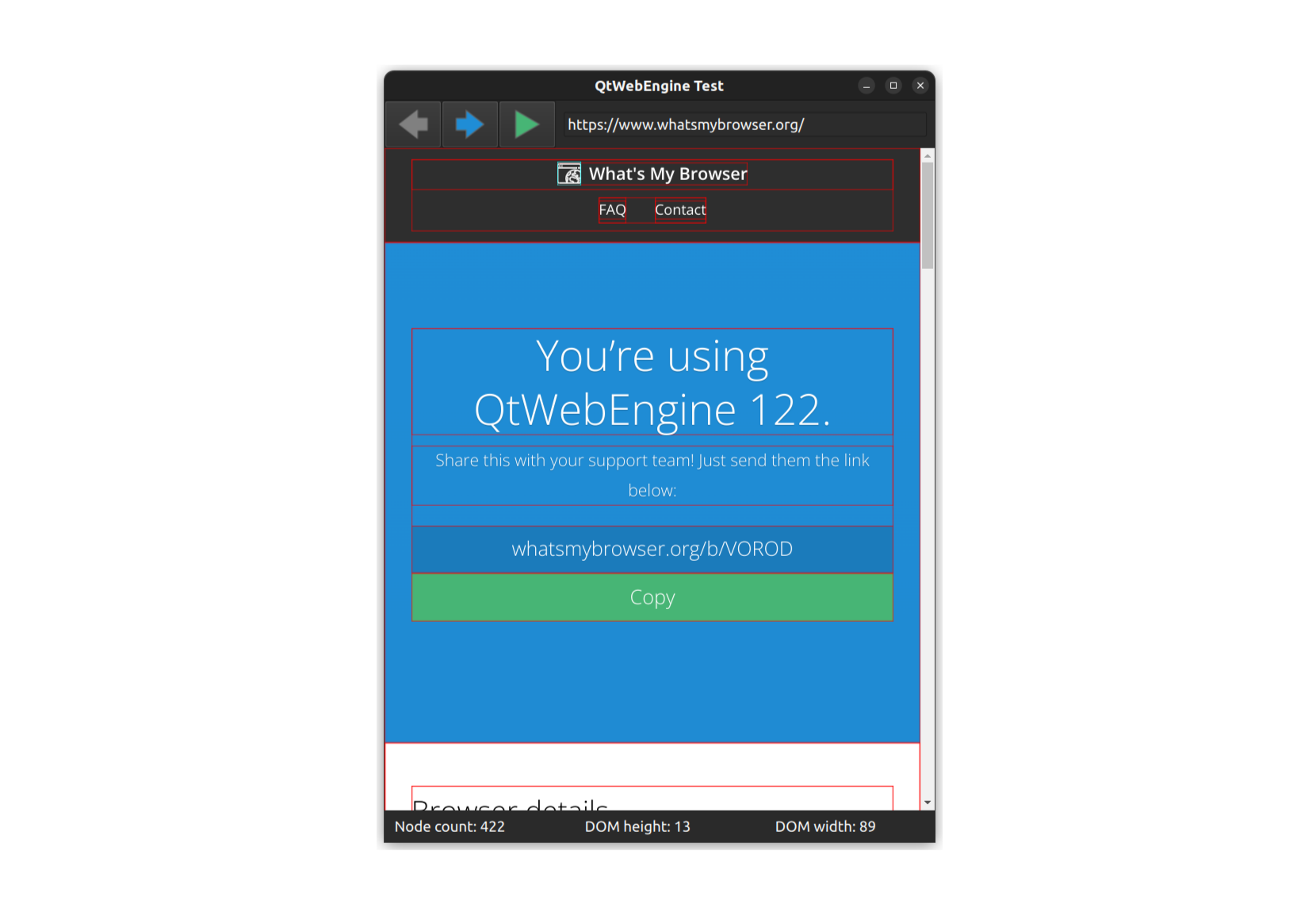
When I first started using QML this automatic updating of the fields felt counter-intuitive. In most programming languages if an expression includes a variable, the value at the point of assignment is used and the expression isn't reevaluated if the variable changes value. In QML if a variable is defined using a colon : (as opposed to an equals =) symbol, it will be bound to the variables in the expression and updated if they change. This is what's happening here: when the dominfo variable is updated, all of its dependent bound variables will be updated too. All made possible using the magical signals from earlier.
Other user interface frameworks (Svelte springs to mind) have this feature as well; when used effectively it can make for super-simple and clean code.
There's just one last piece of the puzzle, which is the domwalk code itself. I'm not going to list it here, because it's practically identical to the code we used for the CEF example, which is listed above. The only difference is the way we return the result back at the end. You can check out the DomWalk.js source file if you'd like to compare.
And that's it. This is far simpler than the code needed for CEF, although admittedly the CEF code all made perfect sense. Unlike CEF, Qt WebEngine is only intended for use with Qt. This fact, combined with the somewhat less verbose syntax of QML compared to C++, is what makes the Qt version so much more concise.
In both cases the underlying Web rendering and JavaScript execution engines are the same: Blink and V8 respectively. It's only the way the Chromium API is exposed that differs.
Let's now move on to the Sailfish WebView, which has a similar interface to Qt WebEngine but uses a different engine in the background.
Sailfish WebView
The Sailfish WebView differs from our previous two examples in some important respects. First and foremost it's designed for use on Sailfish OS, a mobile Linux-based operating system. The Sailfish WebView won't run on other Linux distributions, mainly because Sailfish OS uses a bespoke user interface toolkit called Silica, which is built on top of Qt, but which is specifically targeted at mobile use.Although the Sailfish WebView may therefore not be so useful outside of Sailfish OS, it's Sailfish OS that drives my interest in mobile browsers. So from my point of view it's very natural for me to include it here.
Since it's built using Qt and is exposed as a QML widget, the Sailfish WebView has many similarities with Qt WebEngine. In fact the Qt WebEngine API is itself a successor of the Qt WebView API, which was previously available on Sailfish OS and which the Sailfish WebView was developed as a replacement for.
So expect similarities. However there's also one crucial difference between the two: whereas the Qt WebEngine is built using Blink and V8, the Sailfish WebView is built using Gecko and SpiderMonkey. So in the background they're making use of completely different Web rendering engines.
Like the other two examples, all of the code is available on GitHub. The repository structure is a little different, mostly because Sailfish OS has its own build engine that's designed for generating RPM packages. Although the directory structured differs, for the parts that interest us you'll find all of the same source files across both the WebEngineTest and harbour-webviewtest.
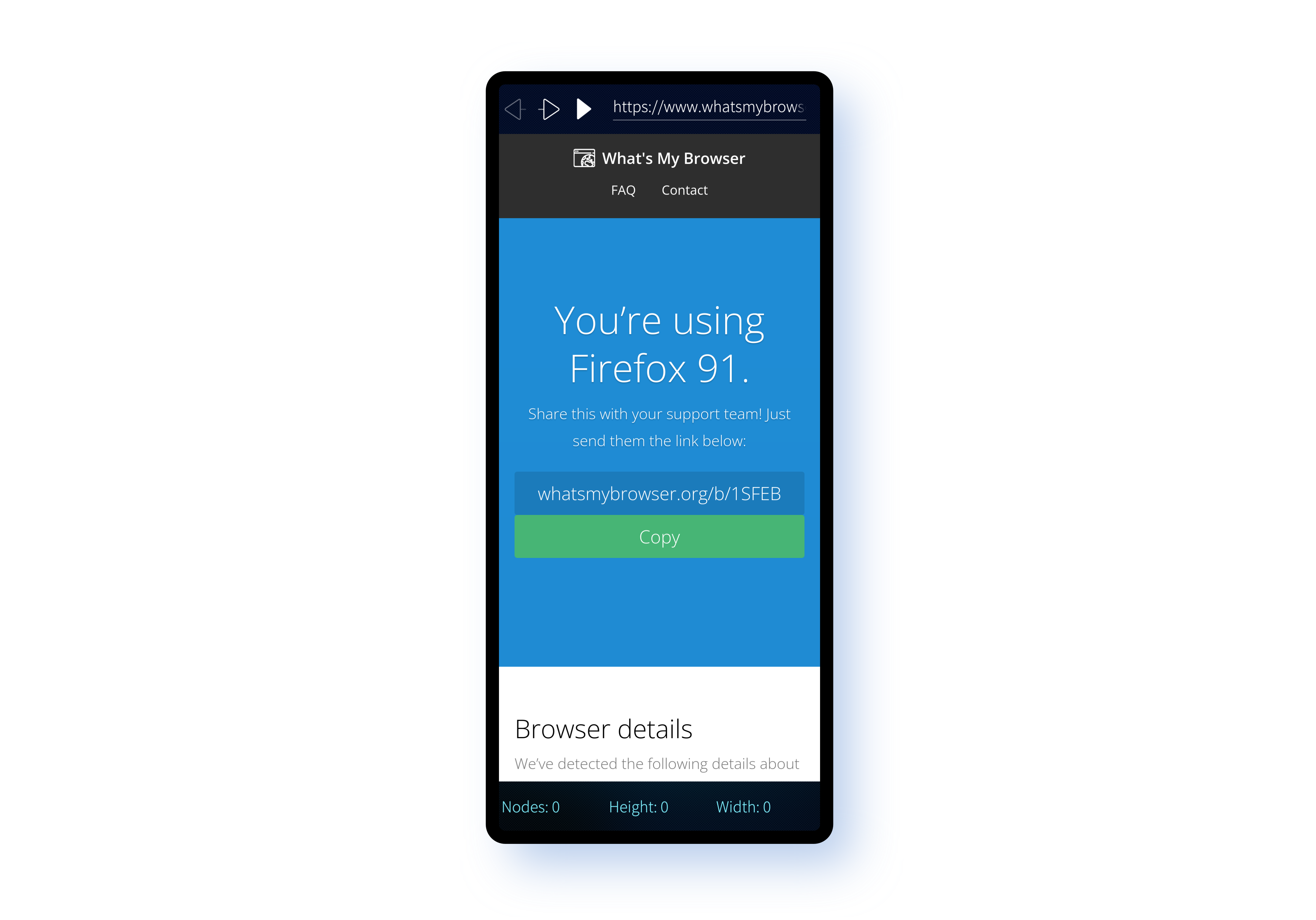
Looking first at the Main.qml file there are only a few differences between this and the equivalent file in the WebEngineTest repository.
Column {
anchors.fill: parent
NavBar {
id: toolbar
webview: webview
width: parent.width
}
WebView {
id: webview
width: parent.width
height: parent.height - (2 * Theme.iconSizeLarge)
url: "https://www.whatsmybrowser.org/"
onUrlChanged: toolbar.urltext.text = url
Component.onCompleted: {
WebEngineSettings.javascriptEnabled = true
}
function getInfo() {
runJavaScript(domwalk, function(result) {
infobar.dominfo = JSON.parse(result);
});
}
}
InfoBar {
id: infobar
width: parent.width
}
}
The main difference is the way the settings are accessed and set. Whereas the settings property could be accessed directly as a WebEngineView property, here we have to access the settings through the WebEngineSettings singleton object. Otherwise this initial page is the same and the approach to calling JavaScript in the DOM is also identical.The DomWalk.js code is also practically identical. One difference is that we don't use structuredClone() because the engine version is slightly older. We use a trick of converting to JSON and back instead to achieve the same result. This JavaScript is loaded in the main.cpp file in the same way as for WebEngineTest.
The NavBar.qml and InfoBar.qml files are to all intents and purposes identical, so I won't copy the code out here.
And that's it. Once again, it's a pretty clean and simple implementation. It demonstrates execution of JavaScript within the DOM that's able to manipulate elements and read data from them. It also shows data being passed back from Gecko to the native app that wraps it.
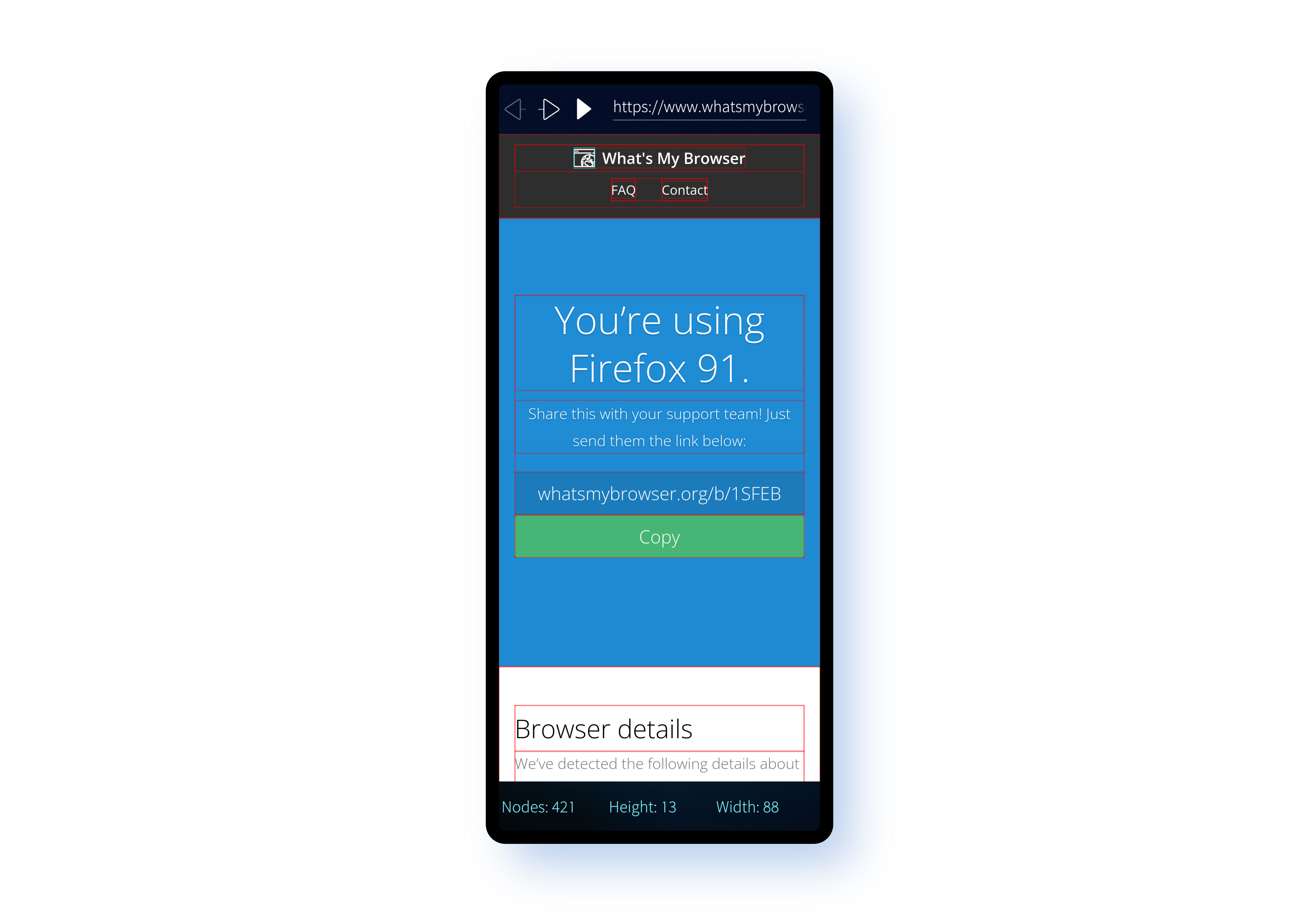
Although the Sailfish WebView is uses Gecko, from the point of view of the developer and the end user there's no real difference between the API offered by Qt WebEngine and that offered by the Sailfish WebView.
For Sailfish OS users it's natural to ask whether it makes sense to continue using Gecko, rather than switching to Blink. I'm hoping this investigation will help provide an answer, but right now I just want to reflect on the fact there's very little difference from the perspective of the API consumer.
Wrap-up
We've seen three different embedding APIs. CEF uses Chromium and in particular Blink and V8 for its rendering and JavaScript engines respectively. CEF isn't aimed at any particular platform or user interface toolkit and consequently writing an application that uses it requires considerably more boilerplate than the Qt WebEngine or Sailfish OS WebView approaches. The latter two both build on the Qt toolkit and it wouldn't make sense to use them with something like Gtk.While CEF and Qt WebEngine both share the same rendering backend, their APIs are quite different, at least when it comes to the specifics. But in fact, the functionalities exposed by both are similar.
The Sailfish WebView on the other hand uses completely different engines — Gecko and SpiderMonkey — and yet, in spite of this the WebView API is really very similar to the Qt WebEngine API.
So as a developer, why choose one of them over the other? When it comes to the WebEngine and the WebView the answer is happily straightforward: since they support different, non-overlapping platforms, if you're using Sailfish OS consider using the WebView; if you're not it's the WebEngine you should look at.
To wrap things up, lets consider the core functionalities the APIs provide. Although each has its own quirks, fundamentally they offer something similar:
- Rendering of Web content. As an embedded browser, the content can be rendered in a window in amongst the other widgets of your application.
- Navigation. The usual Web navigation functionalities can be controlled programmatically. This includes setting the URL, moving through the history and so on
- Settings. The browser settings can be set and controlled programmatically.
- Access to other browser features. This includes profiles, password management, pop-up controls, downloading content and so on. All of these are also accessible via the API.
- JavaScript execution. JavaScript can be executed in the DOM and in different contexts, including with privileged access to all of the engine's functionalities.
- Message passing. Messages can be sent from the managing application to the renderer and in the other direction, allowing fine-grained integration of the two
At the start I said I'd consider whether Gecko is still appropriate for use by Sailfish OS for its embedded browser. This is an important question that we're now closer to having a clearer answer to. I'll take a look at this in more detail in a future post.
13 Nov 2024 : Templating in C #
Many years ago — probably some time around 2006 — I was working as a researcher at Liverpool John Moores University and we had an external speaker come to talk to our students about C++ coding.
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
For the methods we have a bunch of constructors and destructors:
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
If you look in the main() method in main.c you'll see an example of its use:
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
Next we define the default constructor and destructor, alongside respective new and delete methods.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
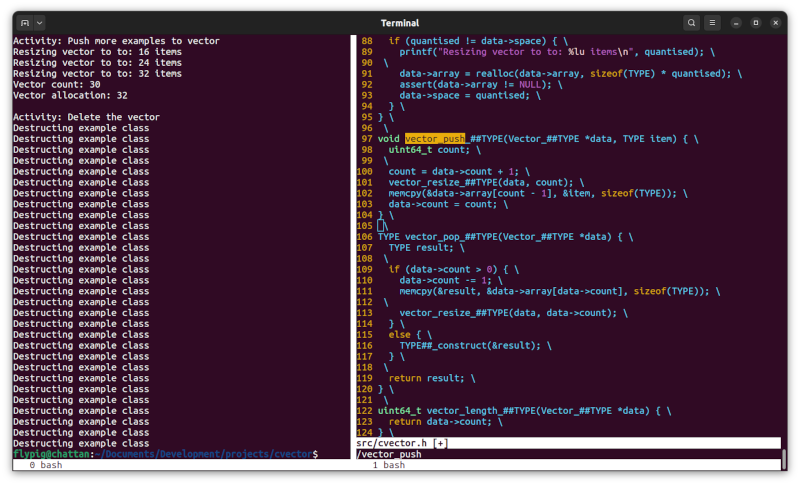
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?
Comment
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
"I appreciate the simplicity of C++'s vector (for example). You probably can do something similar in C but won't it be more involved to get it working for all types for example?"
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
struct _Example {
uint64_t length;
char * string;
};
As you can see the class holds a length to indicate the length of the string and a dynamic array of char instances for the string data. You can imagine that this is a much simplified version of the standard library's string class.For the methods we have a bunch of constructors and destructors:
void Example_construct(Example *data); void Example_construct_init(Example *data, char const * const string); void Example_destruct(Example *data);Similar to C++ we have a default constructor and an "override" that accepts initialisation parameters. It's not an override at all of course because C doesn't support multiple functions using the same name. Instead we just name the two constructors differently, but with the same prefix. Under the hood this is what C++ is doing as well through name mangling, it's just hidden from the programmer.
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Example *example_new(); Example *example_new_init(char const * const string); Example *example_delete(Example *data);These two new methods do allocate memory for the object data, before calling the constructor. Contrariwise the delete method calls the destructor and then frees the allocated memory. I've not looked at the C++ source code for creation and deletion, but I imagine it does something similar.
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
void example_sprintf(Example *data, char const * format, ...); void example_debug_print(Example *data);If this were a proper string implementation we'd want a lot more functionality for accessing and manipulating the string. But this simple example is enough for our purposes.
If you look in the main() method in main.c you'll see an example of its use:
Example_construct_init(&example, "Hello World!"); example_debug_print(&example);Now as the name suggestions this is just an example class, but it already demonstrates the foundations of our class-based approach to C. Apart from the new methods every one of our functions accepts a pointer to an Example as its first parameter. This is the equivalent of the class object this in C++. Every class has a constructor and a destructor. Following the same conventions for all other struct implementations will make our C code safer and more robust, and will encourage increased separation between classes.
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
typedef struct _Vector Vector;Unlike for our Example class in this case we're keeping the actual implementation opaque because we don't have to know its size for use elsewhere.
Next we define the default constructor and destructor, alongside respective new and delete methods.
void vector_construct(Vector *data); Vector *vector_new(); void vector_destruct(Vector * data); Vector *vector_delete(Vector *data);Finally we have a bunch of class methods that are unique to this class and which provide all of the real functionality:
Example vector_get(Vector *data, uint64_t position); void vector_push(Vector *data, Example example); Example vector_pop(Vector *data); uint64_t vector_length(Vector *data); void vector_resize(Vector *data, uint64_t required); void vector_debug_print_space(Vector *data);We have a method for getting items from the vector using random access, a method for pushing items to the end of the vector; a method for popping items from the end of the vector and a method that returns the number of items in the vector. The resize method is for internal use (I shouldn't have included it in the header really) and a debug method for printing out some info about the contents of the vector.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
struct _Vector {
uint64_t space;
uint64_t count;
Example *array;
};
Here we store an array of Example elements. We use a pointer rather than an actual array because we want the size to be dynamic, but by giving it the Example type our stride will be sizeof(Example). We also store a count to represent the number of items in the vector and a space value which represents the size of the array.The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
void vector_push(Vector *data, Example example) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &example, sizeof(Example));
data->count = count;
}
The purpose of this method is to push an item to the end of the vector. We calculate the new space required, which is just the current space plus one (we're adding a single element to the end). We resize the array using vector_resize() to ensure we have the space for it. Then we copy the value from the passed Example structure into the memory that we now know is now available in the array. Finally we set the count of our array to the new, incremented, value.We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
- void example_construct(Example *data);
- void example_destruct(Example *data);
- Example *example_copy(Example const *data, Example *other);
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
typedef struct _Vector {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector;
By way of example for the methods, this is what our vector_push() becomes:
void vector_push(Vector *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
Eventually we'll put these into a macro and we'll need to generate different versions for every TYPE we want to use. But let's not get ahead of ourselves just yet.In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
typedef struct _Vector_##TYPE {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector_##TYPE;
Now our vector implementation for the Example type will use a struct called Vector_Example rather than just Vector. We can do the same thing for our methods as well, like this:
void vector_push_##TYPE(Vector_##TYPE *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize_##TYPE(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
So now our vector_push() method will actually take the name vector_push_Example(). If we were to create a vector that consumes a different type, say a Blob type, the names would become Vector_Blob and vector_push_Blog() respectively.We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
#define vector_push(TYPE) vector_push_##TYPENow, if we want to call the vector_push() method that we've defined for the Example type, we can call it like this:
vector_push(Example)(vector, example);The code with Example surrounded by parenthesis can be considered like the angle-bracket equivalent for templates in C++:
vector_push<Example>(vector, example);We just have to use parentheses rather than angle brackets because C has no concept of the angle brackets as used for templates. The compiler would think they were inequalities.
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
example_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
We need to fix the call to example_destruct() in the middle of that code so that it calls the destructor for the specific type held by the vector. We can do it like this:
void vector_destruct_##TYPE(Vector_##TYPE * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
TYPE##_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
So now, in the case of our vector holding Example objects this will now call Example_destruct() whereas for our vector holding Blob objects, this will call Blob_destruct(). Great!The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
void Example_construct(Example *data); void Example_destruct(Example *data);It's a bit ugly like this in my opinion, but pragmatically it's the right thing to do. For example, it ensures we can to support structs that share the same name apart from their capitalisation, just as we should.
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
#define VECTOR_TEMPLATE(TYPE) \
typedef struct _Vector_##TYPE { \
uint64_t space; \
uint64_t count; \
\
TYPE *array; \
} Vector_##TYPE; \
[...]
With all this in place, the only thing we now need to do is add a call to this macro at the top of our code to define the actual vector classes we want to use:
VECTOR_TEMPLATE(Example) VECTOR_TEMPLATE(Blob) [...]And that's it! We now have a fully type-safe templated vector class written in C that doesn't require any C++ magic.
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
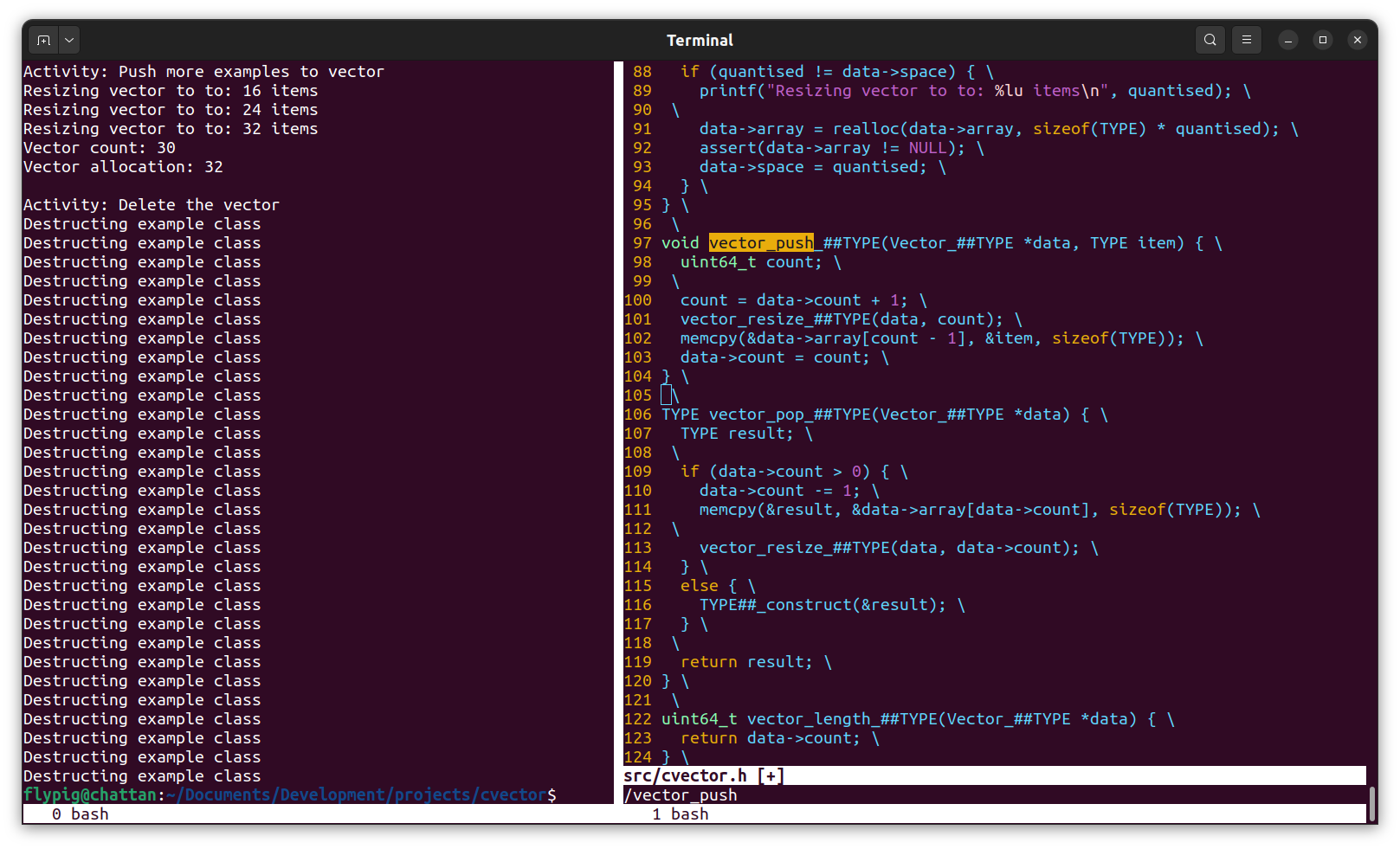
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
#include <type_traits>
template <typename TYPE>
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
if constexpr (std::is_object_v<TYPE>) {
for (pos = 0; pos < data->count; ++pos) {
destruct(&data->array[pos]);
}
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
Sadly the C pre-processor simply isn't sophisticated enough to do anything like this. This also hints at other issues that we might experience with our C implementation. For example, everything works fine for vanilla types, but if we try to use pointers, or const pointers, or any datatype with a composite name, we're going to run in to trouble. There's a solution, which is to make a typedef and use that instead, but it's an extra layer of abstraction and work. Likewise, if we want to use a datatype that has no constructor or destructor (for example if it's a fundamental type) then we'll have to define an empty constructor and an empty destructor in order to allow the code to compile. We can set these as being inline so that the compiler can optimise them away, but again, it's extra work.Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?