List items
Items from the current list are shown below.
Blog
All items from April 2020
25 Apr 2020 : The cold hard truth about my carbon footprint #
Understanding our impact on the environment has always been hard, and I've been lucky enough to live through several iterations of what being green means. At one point environmental impact was measured by the number of aerosols you used. Then it was based on how acidic you made the rain. Then it was the type of detergent you used. There were no doubt many in between that I've forgotten.
The latest metric is that of our carbon footprint: how much CO2 a person produces each year. It certainly has advantages over some of the others, for example by being measurable on a continuous scale, and by capturing a broader range of activities. But at the same time it doesn't capture every type of ecological damage. Someone with zero carbon footprint can still be destroying the ozone layer and poisoning the world's rivers with industrial waste.
Still, even if it's one of many metrics that captures our harm to the environment, it's still worth tracking it in the hope of reducing our overall impact.
With that in mind I recently calculated my carbon footprint using the aptly named "Carbon Footprint Calculator" provided by a company aptly named "Carbon Footprint Ltd.".
I actively try to reduce my carbon emissions, for example by using electricity from a renewable provider, and by walking, cycling or using public transport rather than driving. However I also have a rented flat in Finland (where I live and work), alongside a house in the UK (where my wife lives and works). Travelling between Cambridge and Tampere by boat and train is a three-day odyssey, compared to 11 hours by plane, so I fly much more than I should. Joanna and I don't really enjoy the carbon-footprint benefits of having two or more people living in a single home. Of course, the environmental consequences don't really care why the CO2 is being produced, only that it is, so we need to take an honest look at the output we're producing.
Here's a breakdown of our impact as determined by the calculator.
Given the effort we put in to reducing our footprint, this feels like a depressingly high total. The average for two people in our circumstances is 15.16 tonnes, but the worldwide average is 10.0 tonnes, and the target needed to combat climate change is 4.0 tonnes per year. So we are way off where we really need to be.
How could we get it down to an ecologically-safe level? Well the cold hard truth is that right now, we couldn't. Even if we took no more flights, converted our gas boiler to a renewable energy source and stopped commuting by car, that would still leave our joint carbon footprint at 6.39 tonnes for the year. Too much.
The danger is that we become nihilistic about it, so we need to set realistic goals and then just try to continue to bring it down over time. Joanna and I have been through and worked out what we think we can realistically achieve this year. The COVID-19 pandemic turns out to have some positives here, since we're not commuting or flying at all right now. We think we can realistically bring our combined carbon footprint down to 11.2 tonnes for 2020, and that's what we'll be aiming to do.
The reality is that reducing our CO2 to a sensible level is hard, and it's going to get harder. I'm hoping having something to aim for will help.
Comment
The latest metric is that of our carbon footprint: how much CO2 a person produces each year. It certainly has advantages over some of the others, for example by being measurable on a continuous scale, and by capturing a broader range of activities. But at the same time it doesn't capture every type of ecological damage. Someone with zero carbon footprint can still be destroying the ozone layer and poisoning the world's rivers with industrial waste.
Still, even if it's one of many metrics that captures our harm to the environment, it's still worth tracking it in the hope of reducing our overall impact.
With that in mind I recently calculated my carbon footprint using the aptly named "Carbon Footprint Calculator" provided by a company aptly named "Carbon Footprint Ltd.".
I actively try to reduce my carbon emissions, for example by using electricity from a renewable provider, and by walking, cycling or using public transport rather than driving. However I also have a rented flat in Finland (where I live and work), alongside a house in the UK (where my wife lives and works). Travelling between Cambridge and Tampere by boat and train is a three-day odyssey, compared to 11 hours by plane, so I fly much more than I should. Joanna and I don't really enjoy the carbon-footprint benefits of having two or more people living in a single home. Of course, the environmental consequences don't really care why the CO2 is being produced, only that it is, so we need to take an honest look at the output we're producing.
Here's a breakdown of our impact as determined by the calculator.
| Source | Details | CO2 output 2019 (t) | Goal for 2020 (t) |
|---|---|---|---|
| Electricity | 1 794 kWh | 0.50 | 0.25 |
| Natural gas | 6 433 kWh | 1.18 | 1.18 |
| Flights | 10 return HEL-LON | 5.76 | 3.46 |
| Car | 11 910 km | 1.45 | 0.97 |
| National rail | 1 930 km | 0.08 | 0.16 |
| International rail | 5 630 km | 0.02 | 0.04 |
| Taxi | 64 km | 0.01 | 0.02 |
| Food and drink | 1.69 | 1.69 | |
| Pharmaceuticals | 0.26 | 0.26 | |
| Clothing | 0.03 | 0.03 | |
| Paper-based products | 0.34 | 0.34 | |
| Computer usage | 1.30 | 1.30 | |
| Electrical | 0.12 | 0.12 | |
| Manufactured goods | 0.50 | 0.10 | |
| Hotels, restaurants | 0.51 | 0.51 | |
| Telecoms | 0.15 | 0.15 | |
| Finance | 0.24 | 0.24 | |
| Insurance | 0.19 | 0.19 | |
| Education | 0.05 | 0.05 | |
| Recreation | 0.09 | 0.09 | |
| Total | 14.47 | 11.14 |
Given the effort we put in to reducing our footprint, this feels like a depressingly high total. The average for two people in our circumstances is 15.16 tonnes, but the worldwide average is 10.0 tonnes, and the target needed to combat climate change is 4.0 tonnes per year. So we are way off where we really need to be.
How could we get it down to an ecologically-safe level? Well the cold hard truth is that right now, we couldn't. Even if we took no more flights, converted our gas boiler to a renewable energy source and stopped commuting by car, that would still leave our joint carbon footprint at 6.39 tonnes for the year. Too much.
The danger is that we become nihilistic about it, so we need to set realistic goals and then just try to continue to bring it down over time. Joanna and I have been through and worked out what we think we can realistically achieve this year. The COVID-19 pandemic turns out to have some positives here, since we're not commuting or flying at all right now. We think we can realistically bring our combined carbon footprint down to 11.2 tonnes for 2020, and that's what we'll be aiming to do.
The reality is that reducing our CO2 to a sensible level is hard, and it's going to get harder. I'm hoping having something to aim for will help.
13 Apr 2020 : How to build a privacy-respecting website #
Even before mobile phones got in on the act, the Web had already ushered in the age of mass corporate surveillance. Since then we've seen a bunch of legislation passed, such as the EU ePrivacy Directive and more recently the GDPR, aiming to give Web users some of their privacy back.
That's great, but you might imagine a responsible Web developer would be aiming to provide privacy for their users independent of the legal obligations. In this world of embedded javascipt, social widgets, mixed content and integrated third-party services, that can be easier said than done. So here's a few techniques a conscientious web developer can apply to increase the privacy of their users.
All of these techniques are things I've applied here on my site, with the result that I can be confident web users aren't being tracked when they browse it. If you want to see another example of a site that takes user privacy seriously, take a look at how Privacy International do it (and why).
1. "If you have a GDPR cookie banner, you're part of the problem, not part of the solution"
It's tempting to think that just because you have a click-through GDPR banner with the option of "functional cookies only" that you're good. But users have grown to hate the banners and click through instinctively without turning off the tracking. These banners often reduce users' trust in a site and the web as a whole. What's more, on a well designed site they're completely unnecessary (see 2). That's why you won't find a banner on this site.
2. Only set a cookie as a result of explicit user interaction
On this site I do use to cookies. One is set when you log in, the other if you successfully complete a CAPTCHA. If you don't do either of those things you don't get any cookies.
The site has some user-specific configuration options, such as changing the site style. I could have used a cookie to store those settings too (there's nothing wrong with that, it's what cookies were designed for), but I chose to add the options into the URL instead. However, if I had chosen to store the options in a cookie, I'd be sure only to set the cookie in the event the user actually switches away from the default.
In addition to these two cookies, I also use Disqus for comments, and this also sets cookies, as well as tracking the user. That's bad, but a necessary part of using the service. See section 5 below for how I've gone about addressing this.
3. Only serve material from a server you control
This is good for performance as well as privacy. This includes images, scripts, fonts, or anything else that's automatically downloaded as part of the page.
For example, many sites use Google Fonts, because it's such an excellent resource. But why does Google offer such a massive directory of free fonts? Well, I don't know if they do, but they could certainly use the server hits to better track users, and at the very least it allows them to collect usage data.
The good news is that all of the fonts have licences that allow you to copy them to your server and serve them from there. That's not encouraged by Google, but it's simple to do.
The same applies to scripts, such as jQuery and others. You can embed their copy, but if you want to offer improved privacy, serve it yourself.
Hosting all the content yourself will increase your bandwidth, but it'll also increase your users' privacy. On top of that it'll also provide a better and more consistent experience in terms of performance. Relying on a single server may sound counter-intuitive, but if your server isn't serving the content, all of the stuff around it is irrelevant already, so it's a single point of failure either way. And for your users, waiting for the very last font, image, or advert to download because it's on a random external server you don't control, even if it's done asynchronously, is no fun at all.
Your browser's developer tools are a great way to find out where all of the resources for your site are coming from. In Firefox or Chrome hit F12, select the Network tab, make sure the Disable cache option is selected, then press Ctrl-R to reload the page. You'll see something like this.
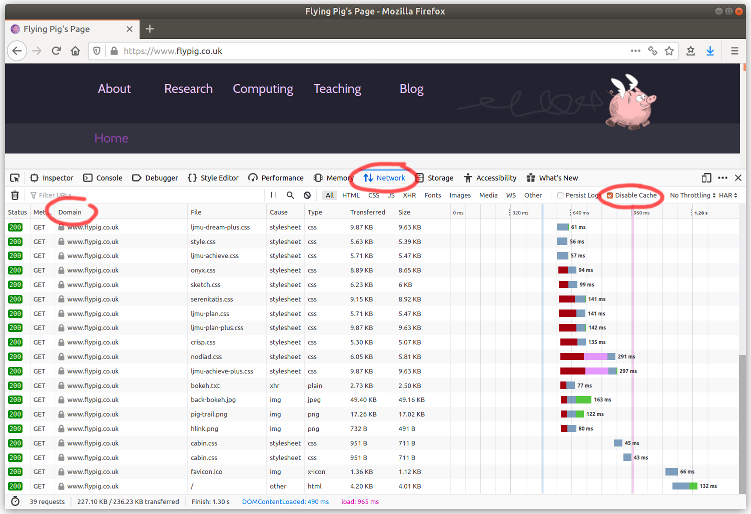
Check the Domain column and make sure it's all coming from your server. If not, make a copy of the resource on your server and update your site's code to serve it from there instead.
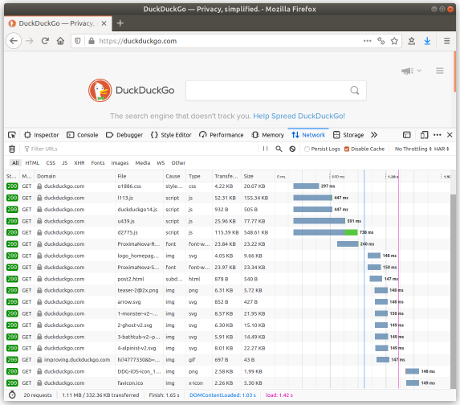
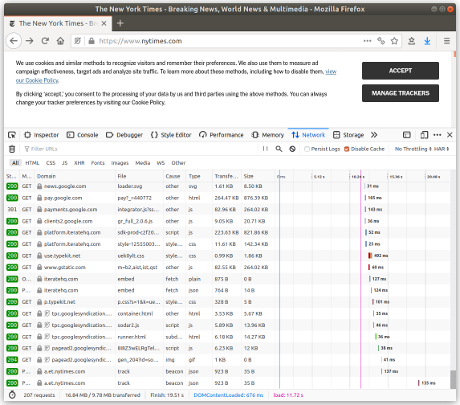
Spot the difference in the images below (click to enlarge) between a privacy-preserving site like DuckDuckGo and a site like the New York Times that doesn't care about its readers' privacy.
4. Don't use third party analytics services
The most commonly used, but also the most intrusive, is probably Google Analytics. So many sites use Google Analytics and it's particularly nefarious because it opens up the door for Google to effectively track web users across almost every page they visit, whether they're logged into a Google service or not.
You may still want analytics for your site of course (I don't use it on my site, but I can understand the value it brings). Even just using analytics from a smaller company provides your users with increased privacy by avoiding all their data going to a single sink. Alternatively, use a self-hosted analytics platform like matomo or OWA. This keeps all of your users' data under your control while still providing plenty of useful information and pretty graphs.
5. Don't embed third-party social widgets, buttons or badges
Services can be very eager to offer little snippets of code to embed into your website, which offer things like sharing buttons or event feeds. The features are often valued by users, but the code and images used are often trojan horses to allow tracking from your site. Often you can get exactly the same functionality without the tracking, and if you can't then 2 should apply: make sure they're not able to track unless the user explicitly makes use of them.
For non-dynamic sharing buttons often the only thing needed is to move any script and images on to your server (see 3). But this isn't always the case.
For example, on this site I use Disqus for comments. Disqus is a notorious tracker, but as a commenting system it offers some nice social features, so I'd rather not remove it. My solution has been to hide the Disqus comments behind an "Uncover Disqus comments" button. Until the user clicks on the button, there's no Disqus code running on the site and no way for Disqus to track them. This fulfils my requirement 2, but it's also not an unusual interaction for the user (for example Ars Technica and Engadget are both commercial sites that do the same).
When you embed Disqus on your site the company provides some code for you to use. On my site it used to look like this:
On page load this would automatically pull in the flypig.disqus.com/embed.js script, exposing the user to tracking. I've now changed it to the following.
The script is still loaded to show the comments, but now this will only happen after the user has clicked the Uncover Disqus comments button.
For a long time I had the same problem embedding a script for social sharing provided by AddToAny. Instead I now just provide a link directly out to https://www.addtoany.com/share. This works just as well by reading the referer header rather than using client-side javascript and prevents any tracking until the user explicitly clicks on the link.
There are many useful scripts, service and social capabilities that many web users expect sites to support. For a web developer they can be so convenient and so hard to avoid that it's often much easier to give in, add a GDPR banner to a site, and move on.
6. Don't embed third-party adverts
Right now the web seems to run on advertising, so this is clearly going to be the hardest part for many sites. I don't serve any advertising at all on my site, which makes things much easier. But it also means no monetisation, which probably isn't an option for many other sites.
It's still possible to offer targetted advertising without tracking: you just have to target based on the content of the page, rather than the profile of the user. That's how it's worked in the real world for centuries, so it's not such a crazy idea.
Actually finding an ad platform that will support this is entirely another matter though. The simple truth is that right now, if you want to include third party adverts on your site, you're almost certainly going to be invading your users' privacy.
There are apparent exceptions, such as Codefund which claims not to track users. I've not used them myself and they're restricted to sites aimed at the open source community, so won't be a viable option for most sites.
Compared to many others, my site is rather simple. Certainly that makes handling my readers' privacy easier than for a more complex site. Nevertheless I hope it's clear from the approaches described here that there often are alternatives to just going with the flow and imposing trackers on your users. With a bit of thought and effort, there are other ways.
Comment
That's great, but you might imagine a responsible Web developer would be aiming to provide privacy for their users independent of the legal obligations. In this world of embedded javascipt, social widgets, mixed content and integrated third-party services, that can be easier said than done. So here's a few techniques a conscientious web developer can apply to increase the privacy of their users.
All of these techniques are things I've applied here on my site, with the result that I can be confident web users aren't being tracked when they browse it. If you want to see another example of a site that takes user privacy seriously, take a look at how Privacy International do it (and why).
1. "If you have a GDPR cookie banner, you're part of the problem, not part of the solution"
It's tempting to think that just because you have a click-through GDPR banner with the option of "functional cookies only" that you're good. But users have grown to hate the banners and click through instinctively without turning off the tracking. These banners often reduce users' trust in a site and the web as a whole. What's more, on a well designed site they're completely unnecessary (see 2). That's why you won't find a banner on this site.
2. Only set a cookie as a result of explicit user interaction
On this site I do use to cookies. One is set when you log in, the other if you successfully complete a CAPTCHA. If you don't do either of those things you don't get any cookies.
The site has some user-specific configuration options, such as changing the site style. I could have used a cookie to store those settings too (there's nothing wrong with that, it's what cookies were designed for), but I chose to add the options into the URL instead. However, if I had chosen to store the options in a cookie, I'd be sure only to set the cookie in the event the user actually switches away from the default.
In addition to these two cookies, I also use Disqus for comments, and this also sets cookies, as well as tracking the user. That's bad, but a necessary part of using the service. See section 5 below for how I've gone about addressing this.
3. Only serve material from a server you control
This is good for performance as well as privacy. This includes images, scripts, fonts, or anything else that's automatically downloaded as part of the page.
For example, many sites use Google Fonts, because it's such an excellent resource. But why does Google offer such a massive directory of free fonts? Well, I don't know if they do, but they could certainly use the server hits to better track users, and at the very least it allows them to collect usage data.
The good news is that all of the fonts have licences that allow you to copy them to your server and serve them from there. That's not encouraged by Google, but it's simple to do.
The same applies to scripts, such as jQuery and others. You can embed their copy, but if you want to offer improved privacy, serve it yourself.
Hosting all the content yourself will increase your bandwidth, but it'll also increase your users' privacy. On top of that it'll also provide a better and more consistent experience in terms of performance. Relying on a single server may sound counter-intuitive, but if your server isn't serving the content, all of the stuff around it is irrelevant already, so it's a single point of failure either way. And for your users, waiting for the very last font, image, or advert to download because it's on a random external server you don't control, even if it's done asynchronously, is no fun at all.
Your browser's developer tools are a great way to find out where all of the resources for your site are coming from. In Firefox or Chrome hit F12, select the Network tab, make sure the Disable cache option is selected, then press Ctrl-R to reload the page. You'll see something like this.
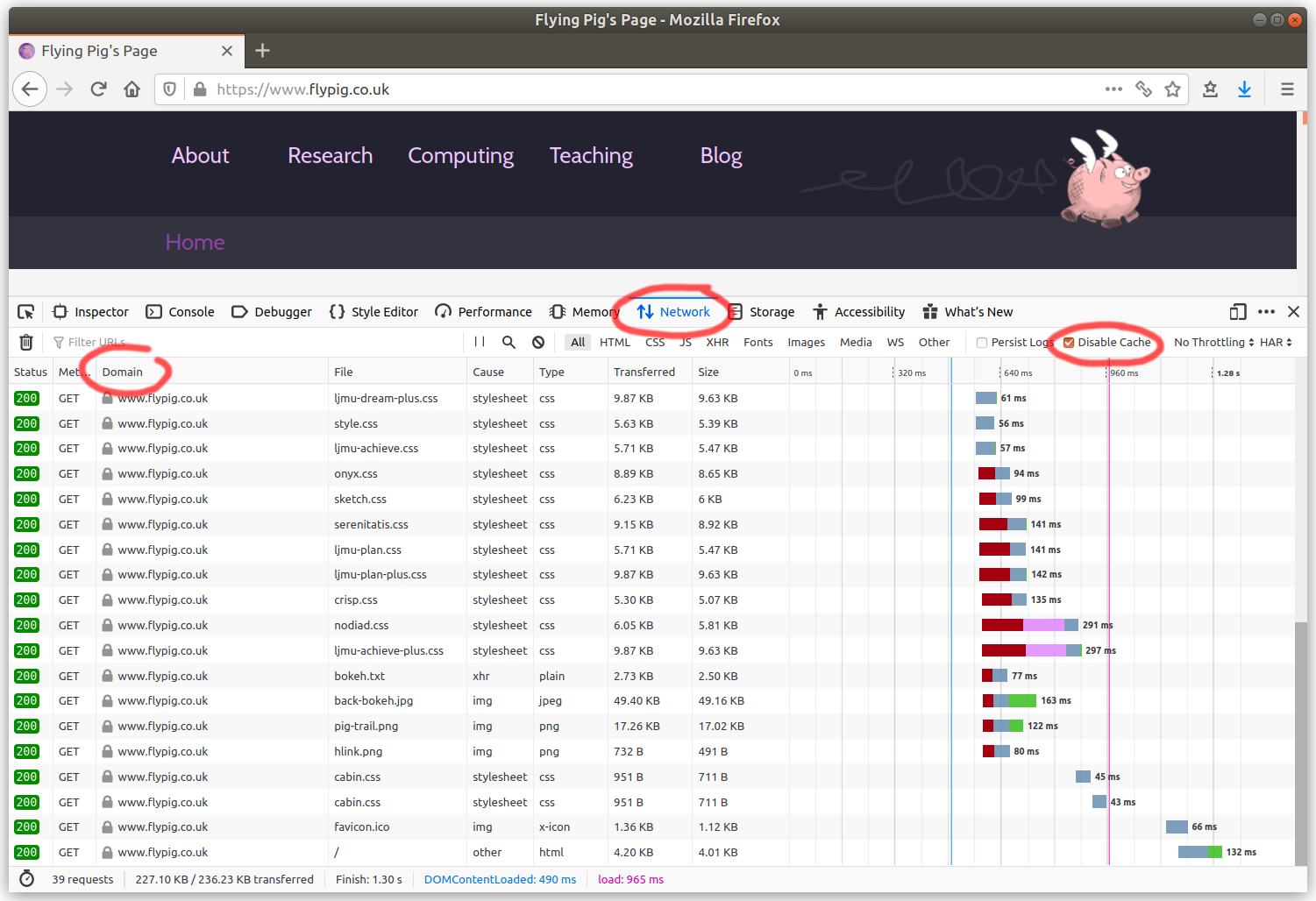
Check the Domain column and make sure it's all coming from your server. If not, make a copy of the resource on your server and update your site's code to serve it from there instead.
Spot the difference in the images below (click to enlarge) between a privacy-preserving site like DuckDuckGo and a site like the New York Times that doesn't care about its readers' privacy.
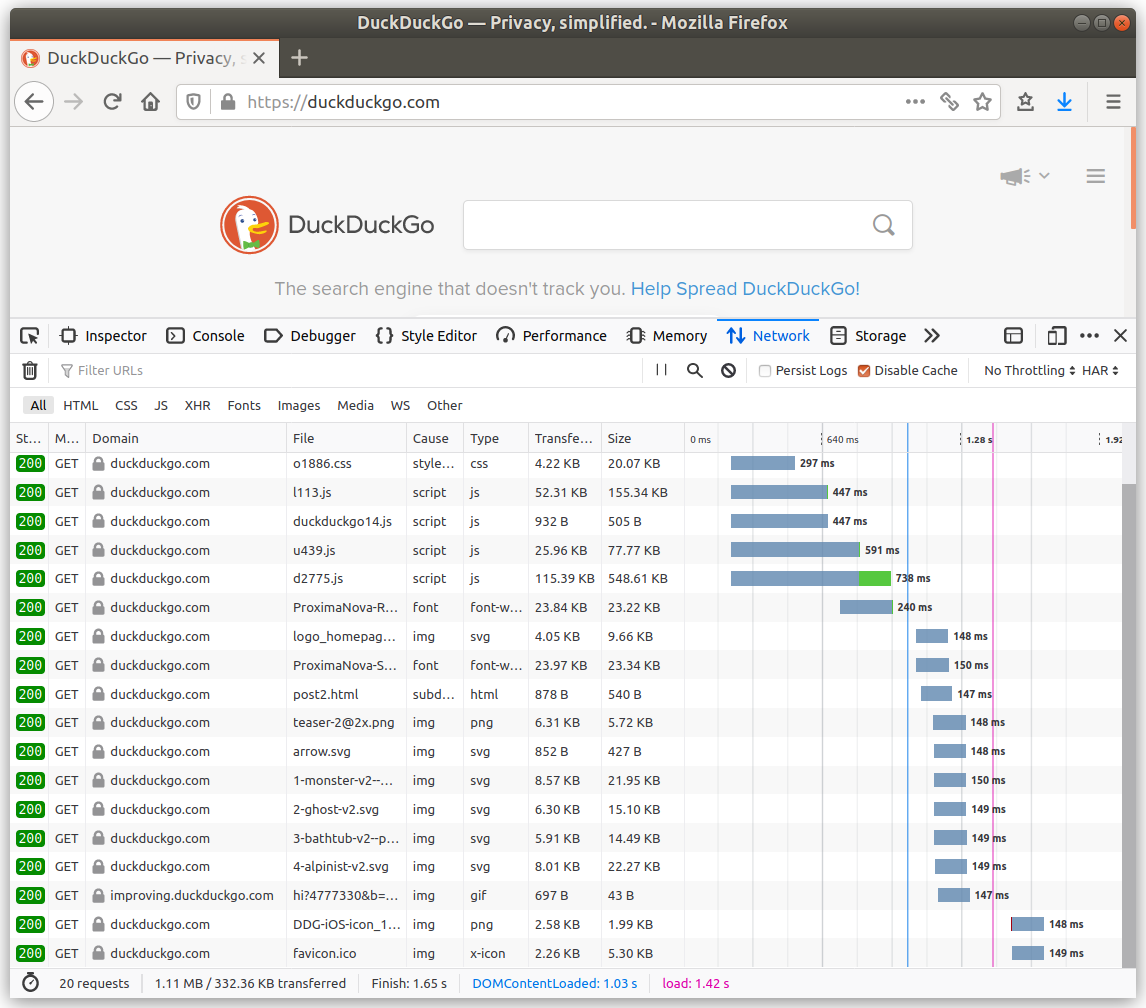
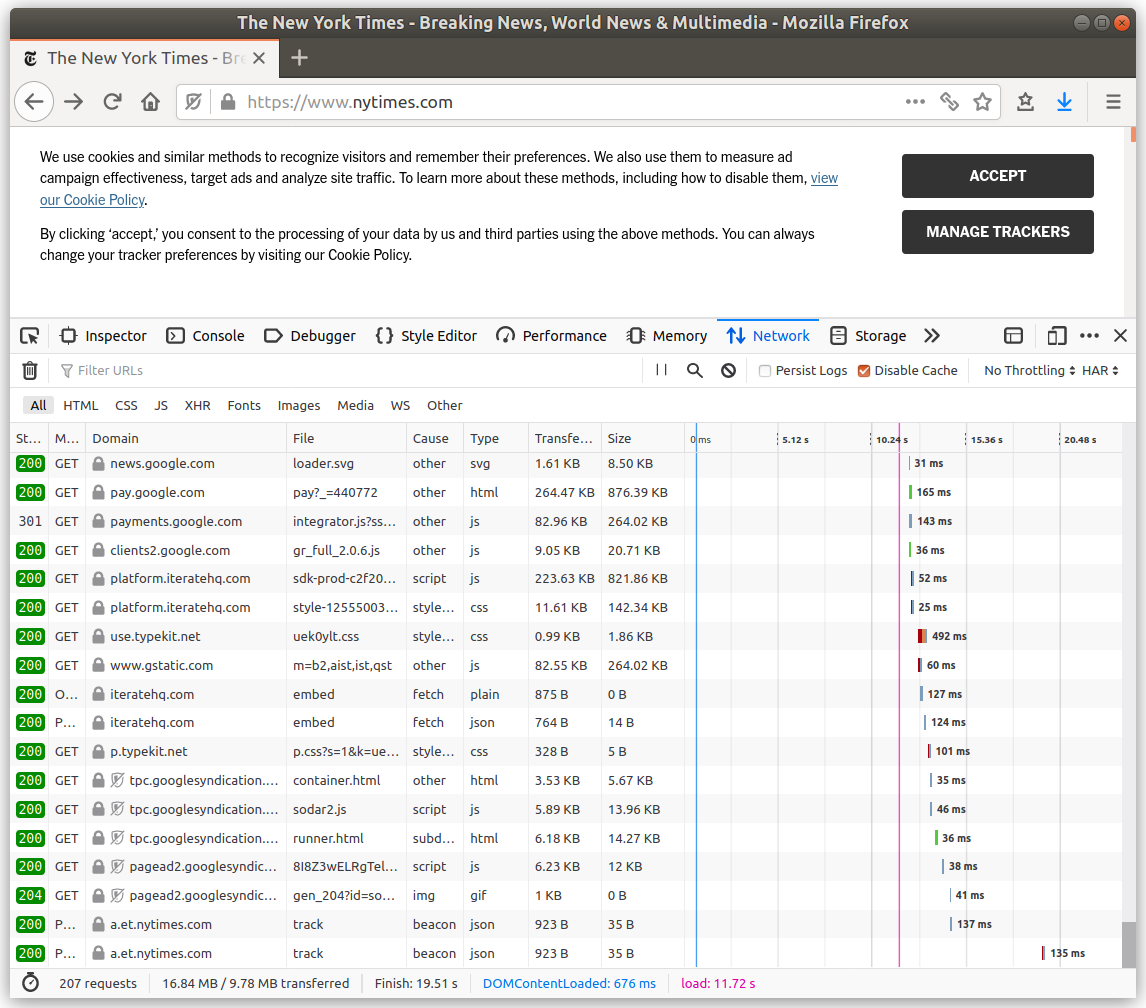
4. Don't use third party analytics services
The most commonly used, but also the most intrusive, is probably Google Analytics. So many sites use Google Analytics and it's particularly nefarious because it opens up the door for Google to effectively track web users across almost every page they visit, whether they're logged into a Google service or not.
You may still want analytics for your site of course (I don't use it on my site, but I can understand the value it brings). Even just using analytics from a smaller company provides your users with increased privacy by avoiding all their data going to a single sink. Alternatively, use a self-hosted analytics platform like matomo or OWA. This keeps all of your users' data under your control while still providing plenty of useful information and pretty graphs.
5. Don't embed third-party social widgets, buttons or badges
Services can be very eager to offer little snippets of code to embed into your website, which offer things like sharing buttons or event feeds. The features are often valued by users, but the code and images used are often trojan horses to allow tracking from your site. Often you can get exactly the same functionality without the tracking, and if you can't then 2 should apply: make sure they're not able to track unless the user explicitly makes use of them.
For non-dynamic sharing buttons often the only thing needed is to move any script and images on to your server (see 3). But this isn't always the case.
For example, on this site I use Disqus for comments. Disqus is a notorious tracker, but as a commenting system it offers some nice social features, so I'd rather not remove it. My solution has been to hide the Disqus comments behind an "Uncover Disqus comments" button. Until the user clicks on the button, there's no Disqus code running on the site and no way for Disqus to track them. This fulfils my requirement 2, but it's also not an unusual interaction for the user (for example Ars Technica and Engadget are both commercial sites that do the same).
When you embed Disqus on your site the company provides some code for you to use. On my site it used to look like this:
<div id="disqus_thread"></div> <script> var disqus_shortname = "flypig"; var disqus_identifier = "page=list&list=blog&list_id=692"; var disqus_url = "https://www.flypig.co.uk:443/?to=list&&list_id=692&list=blog"; (function() { // DON'T EDIT BELOW THIS LINE var dsq = document.createElement("script"); dsq.type = "text/javascript"; dsq.async = true; dsq.src = "https://" + disqus_shortname + ".disqus.com/embed.js"; (document.getElementsByTagName("head")[0] || document.getElementsByTagName("body")[0]).appendChild(dsq); })(); </script>
On page load this would automatically pull in the flypig.disqus.com/embed.js script, exposing the user to tracking. I've now changed it to the following.
<div id="disqus_thread"></div> <a id="show_comments" href="#disqus_thread" onClick="return show_comments()">Uncover Disqus comments</a> <script type="text/javascript"> var disqus_shortname = "flypig"; var disqus_identifier = "page=list&list=blog&list_id=692"; var disqus_url = "https://www.flypig.co.uk:443/?to=list&&list_id=692&list=blog"; function show_comments() { document.getElementById("show_comments").style.display = "none"; var dsq = document.createElement("script"); dsq.type = "text/javascript"; dsq.async = true; dsq.src = "https://" + disqus_shortname + ".disqus.com/embed.js"; (document.getElementsByTagName("head")[0] || document.getElementsByTagName("body")[0]).appendChild(dsq); return false; }; </script>
The script is still loaded to show the comments, but now this will only happen after the user has clicked the Uncover Disqus comments button.
For a long time I had the same problem embedding a script for social sharing provided by AddToAny. Instead I now just provide a link directly out to https://www.addtoany.com/share. This works just as well by reading the referer header rather than using client-side javascript and prevents any tracking until the user explicitly clicks on the link.
There are many useful scripts, service and social capabilities that many web users expect sites to support. For a web developer they can be so convenient and so hard to avoid that it's often much easier to give in, add a GDPR banner to a site, and move on.
6. Don't embed third-party adverts
Right now the web seems to run on advertising, so this is clearly going to be the hardest part for many sites. I don't serve any advertising at all on my site, which makes things much easier. But it also means no monetisation, which probably isn't an option for many other sites.
It's still possible to offer targetted advertising without tracking: you just have to target based on the content of the page, rather than the profile of the user. That's how it's worked in the real world for centuries, so it's not such a crazy idea.
Actually finding an ad platform that will support this is entirely another matter though. The simple truth is that right now, if you want to include third party adverts on your site, you're almost certainly going to be invading your users' privacy.
There are apparent exceptions, such as Codefund which claims not to track users. I've not used them myself and they're restricted to sites aimed at the open source community, so won't be a viable option for most sites.
Compared to many others, my site is rather simple. Certainly that makes handling my readers' privacy easier than for a more complex site. Nevertheless I hope it's clear from the approaches described here that there often are alternatives to just going with the flow and imposing trackers on your users. With a bit of thought and effort, there are other ways.
11 Apr 2020 : Google/Apple's “privacy-safe contact tracing“, a summary #
As I discussed yesterday, Google and Apple recently announced a joint privacy-preserving contact tracing API aimed at helping people find out whether they'd been in contact with someone who subsequently tested positive for COVID-19.
We've already relinquished so many rights in the fight against COVID-19, it's important that privacy isn't another one, not least because the benefit of contact tracing increases with the number of people who use it, and if it violates privacy it'll rightly put people off.
So I'm generally positive about the specification. It seems to be a fair attempt to provide privacy and functionality. Not only that, it's providing a benchmark for privacy that it would be easy for governments to fall short of if the spec weren't already available. Essentially, any government who now provides less privacy than this, is either incompetent, or has alterior motives.
But what does the spec actually say? Apple and Google have provided a decent high-level summary in the form of a slide deck, from which the image below is taken. They've also published a (non-final) technical specification. However, for me the summary is too high-level (it explains what the system does, but not how it works) and the technical specs are too low-level (there's too much detail to get a quick understanding). So this is my attempt at a middle-ground.

There are three parts to the system. There's the OS part, which is what the specification covers; there's an app provided by your regional health authority; and there's a server run by your regional health authority (or more likely, a company the health authority subcontracted to). They all act together to provide the contact tracing service.
This is a significant simplification of the protocol, but hopefully gives an idea of how it works. This is also my interpretation based on reading the specs, so liable to error. By all means criticise my summary, but please don't use this summary to criticise the original specification. If you want to do that, you should read the full specs.
Because of the way the specification is split between the OS and the app, the BLE beacons can be transmitted and received without the user having to install any app. It's only when the user tests positive and wants to notify their regional health authority, or when a user wants to be notified that they may have interacted with someone who tested positive, that they need to install the app. This is a nice feature as it means there's still a benefit even if users don't immediately install the app.
One of the big areas for privacy concern will be the behaviour of the apps provided by the regional health authorities. These have the ability to undermine the anonymity of the system, for example by uploading personal details alongside $k$, or by tracking the IP addresses as the upload takes place. I think these are valid concerns, especially given that governments are notorious data-hoarders, and that the system itself is unlikely to be built or run by a health authority. It would be a tragic missed opportunity if apps do undermine the privacy of the system in this way, but unfortunately it may also be difficult to know unless the sourcecode of the apps themselves is made available.
Comment
We've already relinquished so many rights in the fight against COVID-19, it's important that privacy isn't another one, not least because the benefit of contact tracing increases with the number of people who use it, and if it violates privacy it'll rightly put people off.
So I'm generally positive about the specification. It seems to be a fair attempt to provide privacy and functionality. Not only that, it's providing a benchmark for privacy that it would be easy for governments to fall short of if the spec weren't already available. Essentially, any government who now provides less privacy than this, is either incompetent, or has alterior motives.
But what does the spec actually say? Apple and Google have provided a decent high-level summary in the form of a slide deck, from which the image below is taken. They've also published a (non-final) technical specification. However, for me the summary is too high-level (it explains what the system does, but not how it works) and the technical specs are too low-level (there's too much detail to get a quick understanding). So this is my attempt at a middle-ground.
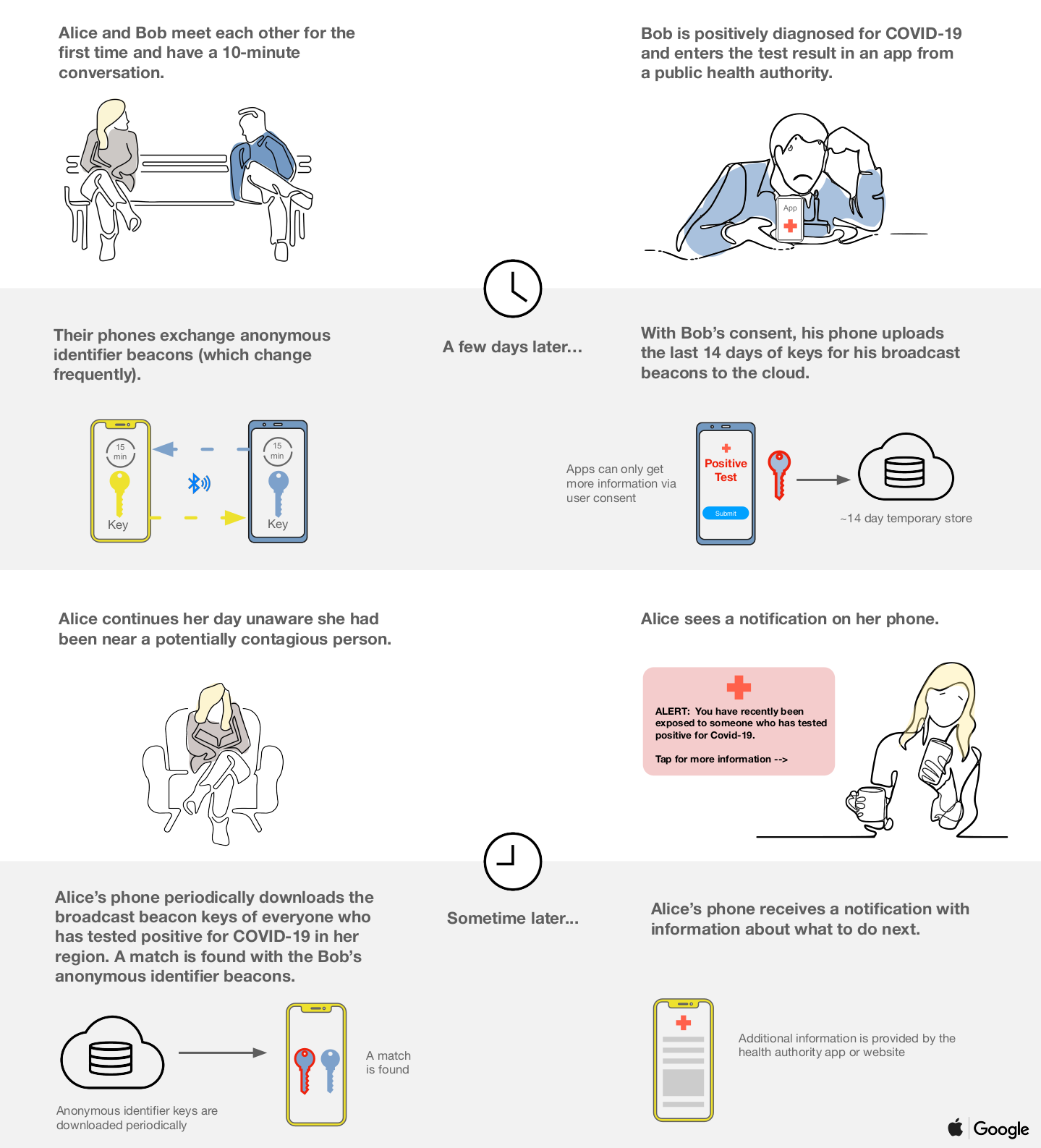
There are three parts to the system. There's the OS part, which is what the specification covers; there's an app provided by your regional health authority; and there's a server run by your regional health authority (or more likely, a company the health authority subcontracted to). They all act together to provide the contact tracing service.
- Each day the user's device generates a random secret $k$, which stays on the user's device for the time being.
- The device then broadcasts BLE beacons containing $h = H(k, c)$ where $H$ is a one-way hash function and $c$ is a counter. Since $k$ can't be derived from $h$, and since no pair of beacons $h_1, h_2$ can be associated with one another, the beacons can't in theory be used for tracking. This assumes that the BLE subsystem provides a level of tracking-protection, for example through MAC randomisation. Such protections don't always work, but at least in theory the contact-tracing feature doesn't make it any worse.
- The device also listens for any beacons sent out by other users and stores any it captures locally in a list $b_1, b_2, \ldots$.
- If a user tests positive for COVID-19 they are asked to notify the regional health authority through the app. This involves the app uploading their secret $k$ for the day to a central database run by the regional health authority (or their subcontractor). From what I can tell, neither Apple nor Google need to be involved in the running of this part of the system, or to have direct access to the database. Note that only $k$ is uploaded. Neither the individual beacons $h_1, h_2, \ldots$ sent, nor the beacons $b_1, b_2, \ldots$ received, need to be uploaded. This keeps data quantities down.
- Each day the user's phone also downloads a list $k_1, k_2, \ldots, k_m$ of secrets associated with people who tested positive. This is the list collated each day in the central database. These keys were randomly generated on the user's phone and so are pseudonymous.
- The user's phone then goes through the list and checks whether one of the $k_i$ is associated with someone they interacted with. It does this by re-calculating the beacons that were derived from this secret: $H(k_i, 1), H(k_i, 2), \ldots, H(k_i, m)$, and compares each against every beacon it collected the same day.
- If there's a match $H(k_i, j) = b_l$, then the user is alerted that they likely interacted with someone who has subsequently tested positive. Because the phone also now knows the counter $j$ used to generate the match, it can also provided a time for when the interaction occurred.
This is a significant simplification of the protocol, but hopefully gives an idea of how it works. This is also my interpretation based on reading the specs, so liable to error. By all means criticise my summary, but please don't use this summary to criticise the original specification. If you want to do that, you should read the full specs.
Because of the way the specification is split between the OS and the app, the BLE beacons can be transmitted and received without the user having to install any app. It's only when the user tests positive and wants to notify their regional health authority, or when a user wants to be notified that they may have interacted with someone who tested positive, that they need to install the app. This is a nice feature as it means there's still a benefit even if users don't immediately install the app.
One of the big areas for privacy concern will be the behaviour of the apps provided by the regional health authorities. These have the ability to undermine the anonymity of the system, for example by uploading personal details alongside $k$, or by tracking the IP addresses as the upload takes place. I think these are valid concerns, especially given that governments are notorious data-hoarders, and that the system itself is unlikely to be built or run by a health authority. It would be a tragic missed opportunity if apps do undermine the privacy of the system in this way, but unfortunately it may also be difficult to know unless the sourcecode of the apps themselves is made available.
10 Apr 2020 : Initial observations on the joint Google/Apple “privacy-safe contact tracing” specification #
Apple and Google today announced a joint protocol to support contact tracing using BLE. You can read their respective posts about it on the Apple Newsroom and Google blog.
The posts offer some context, but the real meat can be found in a series of specification documents. The specs provide enough information about how the system will work to allow a decent understanding, albeit with some caveats.
With so much potential for misuse, and given that mistrust could lead to some people choosing not to use the system, it's great that Google and Apple are apparently taking privacy and interoperability so seriously. But I'm a natural sceptic, so whenever a company claims to be taking privacy seriously, I like to apply a few tests.
The catch is that the API defined by the specs provides only half of a full implementation. Apple and Google are providing an API for generating and capturing BLE beacons. They don't say what should happen to those beacons once they've been captured. Presumably this is because they expect this part of the system to be implemented by a third-party, most likely a regional public health authority (or, even more likely, a company that a health authority has subcontracted to).
Again, this makes sense, since different regions may want to implement their own client and server software to do this. In fact, by delegating this part of the system, Google and Apple strengthen their claim that they're acting in good faith. They're essentially encouraging public health authorities and their subcontractors to live up to the same privacy standards.
Apart from the privacy issues, my other main interest is in having the same system work on operating systems other than iOS and Android. My specific interest is for Sailfish OS, but there are other smartphone operating systems that people use, and locking users of alternative operating systems out of something like this would be a terrible result both for the operating system and for all users.
Delegation of the server and app portions to health authorities unfortunately makes it highly unlikely that alternative operating systems will be able to hook into the system. For this to happen, the health authority servers would also need to provide a public API. Google and Apple leave this part completely open, and the likelihood that health authorities will provide an API is unfortunately very slim.
I'd urge any organisation planning to develop the client software and servers for a fully working system to prove me wrong. Otherwise alternative operating system users like me could be left unable to access the benefits of the system. This reduces its utility for those users to nill, but it also reduces the effectiveness of the system for all users, independent of which operating system they use, because it increases the false negative rate.
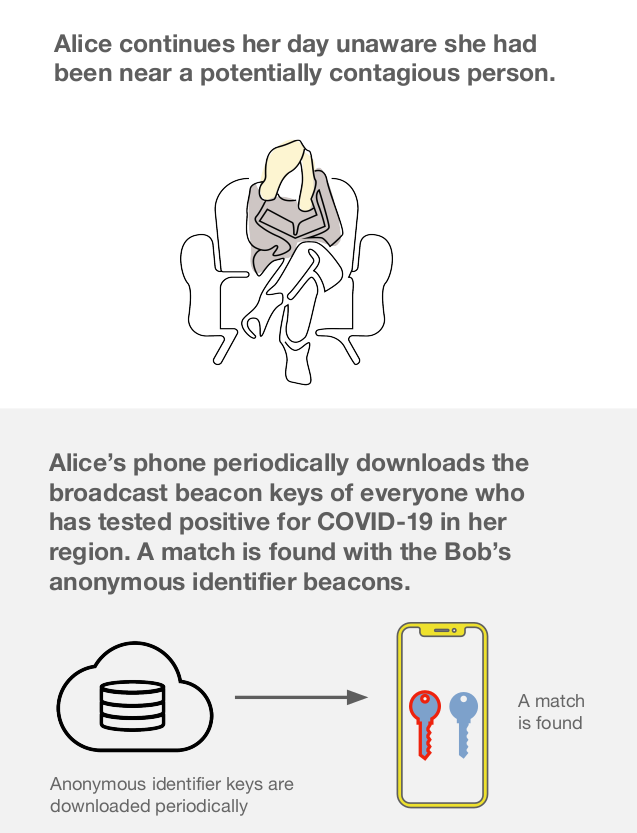
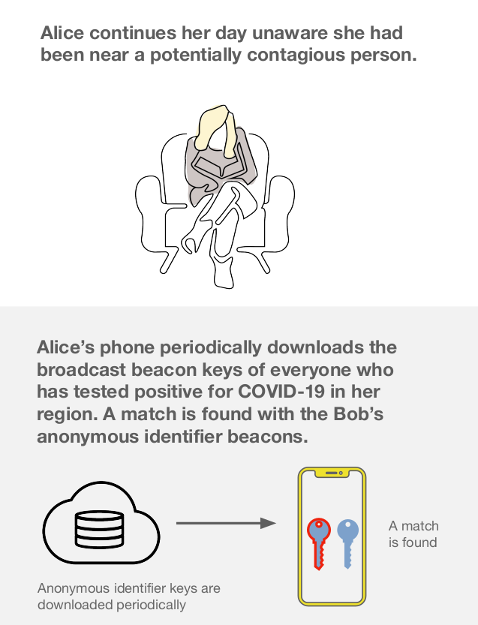
There's one other aspect of the specification that intrigues me. In the overview slide deck it states that "Alice’s phone periodically downloads the broadcast beacon keys of everyone who has tested positive for COVID-19 in her region." (my emphasis). This implies some form of region-locking that's not covered by the spec. Presumably this is because the servers will be run by regional health authorities and so the user will install an app that applies to their particular region. There are many reasons why this is a good idea, not least because otherwise the amount of data a user would have to download to their device each day would be prohibitive. But there is a downside too. It essentially means that users travelling across regions won't be protected. If they interact with someone from a different region who tests positive, this interaction won't be flagged up by the system.
The spec is still very new and no doubt more details will emerge over the coming days and weeks. I'll be interested to see how it pans out, and also interested to see whether this can be implemented on devices like my Sailfish OS phone.
 Comment
Comment
Apple and Google today announced a joint protocol to support contact tracing using BLE. You can read their respective posts about it on the Apple Newsroom and Google blog.
The posts offer some context, but the real meat can be found in a series of specification documents. The specs provide enough information about how the system will work to allow a decent understanding, albeit with some caveats.
With so much potential for misuse, and given that mistrust could lead to some people choosing not to use the system, it's great that Google and Apple are apparently taking privacy and interoperability so seriously. But I'm a natural sceptic, so whenever a company claims to be taking privacy seriously, I like to apply a few tests.
- Are the specs and implementation details (ideally sourcecode) freely and openly available?
- Is interoperability with other software and devices supported.
- Based on the information available, is there a more privacy-preserving approach that the company could have gone with, but chose not to?
The catch is that the API defined by the specs provides only half of a full implementation. Apple and Google are providing an API for generating and capturing BLE beacons. They don't say what should happen to those beacons once they've been captured. Presumably this is because they expect this part of the system to be implemented by a third-party, most likely a regional public health authority (or, even more likely, a company that a health authority has subcontracted to).
Again, this makes sense, since different regions may want to implement their own client and server software to do this. In fact, by delegating this part of the system, Google and Apple strengthen their claim that they're acting in good faith. They're essentially encouraging public health authorities and their subcontractors to live up to the same privacy standards.
Apart from the privacy issues, my other main interest is in having the same system work on operating systems other than iOS and Android. My specific interest is for Sailfish OS, but there are other smartphone operating systems that people use, and locking users of alternative operating systems out of something like this would be a terrible result both for the operating system and for all users.
Delegation of the server and app portions to health authorities unfortunately makes it highly unlikely that alternative operating systems will be able to hook into the system. For this to happen, the health authority servers would also need to provide a public API. Google and Apple leave this part completely open, and the likelihood that health authorities will provide an API is unfortunately very slim.
I'd urge any organisation planning to develop the client software and servers for a fully working system to prove me wrong. Otherwise alternative operating system users like me could be left unable to access the benefits of the system. This reduces its utility for those users to nill, but it also reduces the effectiveness of the system for all users, independent of which operating system they use, because it increases the false negative rate.
There's one other aspect of the specification that intrigues me. In the overview slide deck it states that "Alice’s phone periodically downloads the broadcast beacon keys of everyone who has tested positive for COVID-19 in her region." (my emphasis). This implies some form of region-locking that's not covered by the spec. Presumably this is because the servers will be run by regional health authorities and so the user will install an app that applies to their particular region. There are many reasons why this is a good idea, not least because otherwise the amount of data a user would have to download to their device each day would be prohibitive. But there is a downside too. It essentially means that users travelling across regions won't be protected. If they interact with someone from a different region who tests positive, this interaction won't be flagged up by the system.
The spec is still very new and no doubt more details will emerge over the coming days and weeks. I'll be interested to see how it pans out, and also interested to see whether this can be implemented on devices like my Sailfish OS phone.