List items
Items from the current list are shown below.
Blog
All items from November 2019
26 Nov 2019 : Graphs of Waste, Part 3: A Continuously Differentiable Histogram Approach #
In part one we looked at how graphs can be a great tool for expressing the generalities in specific datasets, but how even seemingly minor changes in the choice of graphing technique can result in a graph that tells an inaccurate story.
In part two we found out we could draw a continuous line graph that captured several useful properties that are usually associated with histograms, notably that the area under the line graph is the same as it would be for a histogram between the measurement points along the $x$-axis.
But what if we want to go a step further and draw a smooth line, rather than one made up of straight edges? Rather than just a continuous line, can we present the same data with a continuously differentiable line? Can we do this and still respect this 'area under the graph' property?
It turns out, the answer is "yes"! And we can do it in a similar way. First we send the curve through each of the same points at the boundary of each column, then we adjust the height of the midpoint to account for any changes caused by the curvature of the graph.
There are many, many, ways to draw nice curves, but one that frequently comes up in computing is the Bézier curve. It has several nice properties, in that it's nicely controllable, and depending on the order of the curve, we can control to any depth of derivative we choose. We'll use second-degree Bézier curves, meaning that we'll be able to have a continuous line and a continuous first derivative. This should keep things nice and smooth.
Bézier curves are defined parametrically, meaning that rather than having a function that takes an $x$ input and produces a $y$ output, as is the common Cartesian case, instead it takes a parameter input $t$ that falls between 0 and 1, and outputs both the $x$ and $y$ values. In order to avoid getting confused with the variables we used in part two, we're going to use $u$ and $v$ instead of $x$ and $y$ respectively.
Here's the formula for a second-order Bézier curve.
$$
\begin{pmatrix} u \\ v \end{pmatrix} = (1 - t)^3 \begin{pmatrix} u_0 \\ v_0 \end{pmatrix} + 3(1 - t)^2 t \begin{pmatrix} u_1 \\ v_1 \end{pmatrix} + 3 (1 - t) t^2 \begin{pmatrix} u_2 \\ v_2 \end{pmatrix} + t^3 \begin{pmatrix} u_3 \\ v_3 \end{pmatrix} .
$$
Where $\begin{pmatrix} u_0 \\ v_0 \end{pmatrix}$, $\begin{pmatrix} u_3 \\ v_3 \end{pmatrix}$ are the start and end points of the curve respectively, and $\begin{pmatrix} u _1\\ v_1 \end{pmatrix}$, $\begin{pmatrix} u_2 \\ v_2 \end{pmatrix}$ are control points that we position in order to get our desired curve.
The fact a Bézier curve is parametric is a problem for us, because it makes it considerably more difficult to integrate under the graph. If we want to know the area under the curve, we're going to have to integrate it, so we need a way to turn the parameterised curve into a Cartesian form.
Luckily we can cheat.
If we set $\begin{pmatrix} u_1 \\ v_1 \end{pmatrix}$ and $\begin{pmatrix} u_2 \\ v_2 \end{pmatrix}$ to be $\frac{1}{3}$ and $\frac{2}{3}$ of the way along the curve respectively, then things get considerably easier. In other words, set
\begin{align*}
u_1 & = u_0 + \frac{1}{3} (u_3 - u_0) \\
& = \frac{2}{3} u_0 + \frac{1}{3} u_3 \\
\end{align*}
and
\begin{align*}
u_2 & = u_0 + \frac{2}{3} (u_3 - u_0) \\
& = \frac{1}{3} u_0 + \frac{2}{3} u_3 .
\end{align*}
Substituting this into our Bézier curve equation from earlier we get
\begin{align*}
u & = (1 - t)^3 u_0 + 3 (1 - t)^2 t \times \left( \frac{2}{3} u_0 + \frac{1}{3} u_3 \right) + 3 (1 - t) t^2 \times \left( \frac{1}{3} u_0 + \frac{2}{3} u_3 \right) + t^3 u_3 \\
& = u_0 + t (u_3 - u_0) .
\end{align*}
When we choose our $u_1$ and $u_2$ like this, we can perform the substitution
$$
\psi(t) = u_0 + t(u_3 - u_0)
$$
in order to switch between $t$ and $u$. This will make the integral much easier to solve. We note that $\psi$ is a bijection and so invertible as long as $u_3 \not= u_0$. We can therefore define the inverse:
$$
t = \psi^{-1} (u) = \frac{u - u_0}{u_3 - u_0} \\
$$
It will also be helpful to do a bit of groundwork. We find the values at the boundary as
\begin{align*}
\psi^{-1} (u_0) & = 0, \\
\psi^{-1} (u_3) & = 1, \\
\end{align*}
and we also define the following for convenience.
$$
V(u) = v(\psi^{-1} (u)) .
$$
We'll use these in the calculation of the integral under the Bézier curve, which goes as follows.
$$
\int_{u_0}^{u_3} V(u) \mathrm{d}u
$$
Using the substitution rule we get
\begin{align*}
\int_{\psi^{-1}(u_0)}^{\psi^{-1}(u_3)} & V(\psi(t)) \psi'(t)\mathrm{d}t = \int_{t = 0}^{t = 1} v(\psi^{-1}(\psi(t))) (u_3 - u_0) \mathrm{d}t \\
& = (u_3 - u_0) \int_{0}^{1} v(t) \mathrm{d}t . \\
& = (u_3 - u_0) \int_{0}^{1} (1 - t)^3 v_0 + 3 (1 - t)^2 t v_1 + 3 (1 - t) t^2 v_2 + t^3 v_3 \mathrm{d}t \\
& = (u_3 - u_0) \int_{0}^{1} (1 - 3t + 3t^2 - t^3) v_0 + 3 (t - 2t^2 + t^3) v_1 + 3 (t^2 - t^3) v_2 + t^3 v_3 \mathrm{d}t \\
& = \frac{1}{4} (u_3 - u_0) (v_0 + v_1 + v_2 + v_3) .
\end{align*}
We'll bank this calculation and come back to it. Let's now consider how we can wrap the Bézier curve over the points in our graph to make a nice curve. For each column we're going to end up with something like this.

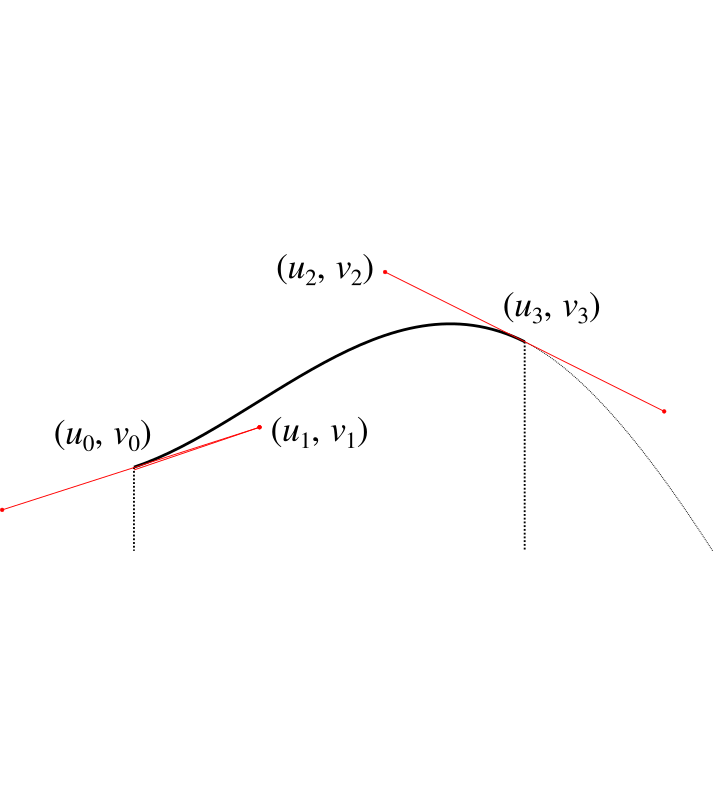
Now as before, we don't have control over $u_0$, $v_0$ because it affects the adjoining curve. We also don't have control over $u_1$ and $u_2$ because as just described, we have these set to allow us to perform the integration. We also must have $u_3$ set as $u_3 = u_0 + w / 2$ so that it's half way along the column.
Our initial assumption wil be that $v_3 = h$, but this is the value we're going to manipulate (i.e. raising or lowering the central point) in order to get the area we need. We shouldn't need to adjust it by much.
That just leaves $v_1$ and $v_2$. We need to choose these to give us a sensible and smooth curve, which introduces some additonal constraints. We'll set the gradient at the point $u_0$ to be the gradient $g_1$ of the line that connects the heights of the centrepoints of the two adjacent columns:
$$
g_1 = \frac{y - y_L}{x - x_L}
$$
where $x, y$ are the same points we discussed in part two, and $x_L, y_L$ are the same points for the column to the left. We'll also use $x_R, y_R$ to refer to the points for the column on the right, giving us:
$$
g_2 = \frac{y_R - y}{x_R - x} .
$$
Using our value for $g_1$ we then have
$$
v_1 = v_0 + g_1 (u_1 - u_0) .
$$
For the gradient $g$ at the centre of the column, we set this to be the gradient of the line between $y_1$ and $y_2$:
$$
g = \frac{y_2 - y_1}{x_2 - x_1} .
$$
We then have that
$$
v_2 = v_3 + g (u_2 - u_3) .
$$
From these we can calculate the area under the curve using the result from our integration calculation earlier, by simply substiuting the values in. After simplifying the result, we get the following.
$$
A_1' = \frac{1}{8}(x_2 - x_1) \left( 2y' + \frac{13}{6} y_1 - \frac{1}{6} y_2 + \frac{1}{6} g_1 (x_2 - x_1) \right)
$$
where $y'$ is the height of the central point which we'll adjust in order to get the area we need. This looks nasty, but it'll get simpler. We can perform the same calculation for the right hand side to get
$$
A_2' = \frac{1}{8}(x_2 - x_1) \left( 2y' + \frac{13}{6} y_2 - \frac{1}{6} y_1 - \frac{1}{6} g_2 (x_2 - x_1) \right) .
$$
Adding the two to give the total area $A' = A_1' + A_2'$ allows us to do a bunch of simplification, giving us
$$
A' = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + y' \right) + \frac{w^2}{48} (g_1 - g_2) .
$$
If we now compare this to the $A$ we calculated for the straight line graph in part two, subtracting one from the other gives us that
$$
y' = y + \frac{w}{24} (g_2 - g_1) .
$$
This tells us how much we have to adjust $y$ by to compensate for the area change caused by the curvature of the Bézier curves.
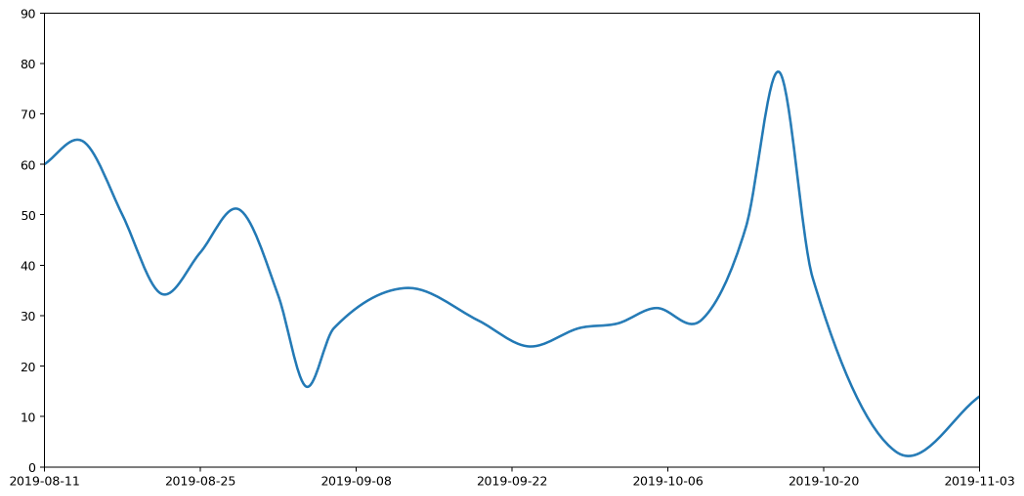
What does this give us in practice? Here's the new smoothed graph based on the same data as before.
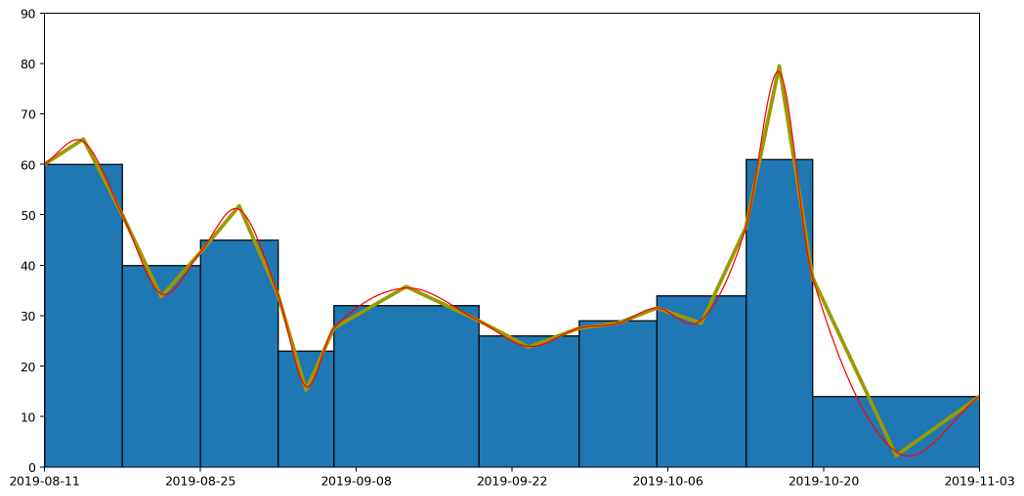
Let's overlay the three approaches — histogram, straight line and curved graphs — to see how they all compare. The important thing to note is that the area under each of the columns — bounded above by the flat line, the straight line and the curve respectively — are all the same.
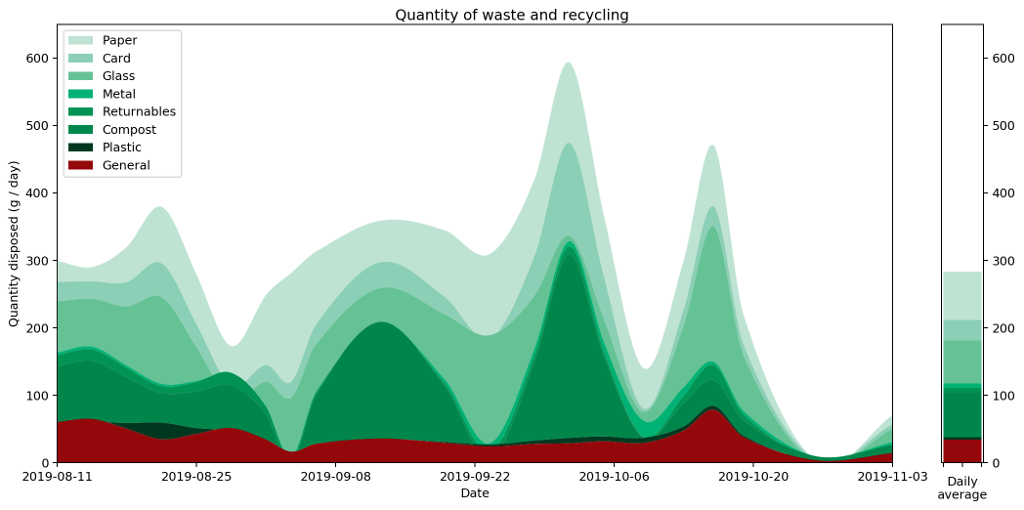
Because of the neat way Bézier curves retain their area properties, we can even stack them nicely, similarly to how we stacked our histogram in part one, to get the following representation of the full set of data.
Putting all of this together, we now have a pretty straightforward way to present area-under-the-graph histograms of continuous data in a way that captures that continuity. I call this graph a "histocurve". A histocurve can give a clearer picture of the overall general trends of the data. For example, each of the strata in the histocurve remains unbroken, compared to the strata in a classic histogram which is liable to get broken at the boundary between every pair of columns.
That's all great, but it's certainly not perfect. In the fourth and final part of this series which I hope to get out on the 3rd December, I'll briefly discuss the pitfalls of histocurves, some of their negative properties, and things I'd love to fix but don't know how.
Comment
In part two we found out we could draw a continuous line graph that captured several useful properties that are usually associated with histograms, notably that the area under the line graph is the same as it would be for a histogram between the measurement points along the $x$-axis.
But what if we want to go a step further and draw a smooth line, rather than one made up of straight edges? Rather than just a continuous line, can we present the same data with a continuously differentiable line? Can we do this and still respect this 'area under the graph' property?
It turns out, the answer is "yes"! And we can do it in a similar way. First we send the curve through each of the same points at the boundary of each column, then we adjust the height of the midpoint to account for any changes caused by the curvature of the graph.
There are many, many, ways to draw nice curves, but one that frequently comes up in computing is the Bézier curve. It has several nice properties, in that it's nicely controllable, and depending on the order of the curve, we can control to any depth of derivative we choose. We'll use second-degree Bézier curves, meaning that we'll be able to have a continuous line and a continuous first derivative. This should keep things nice and smooth.
Bézier curves are defined parametrically, meaning that rather than having a function that takes an $x$ input and produces a $y$ output, as is the common Cartesian case, instead it takes a parameter input $t$ that falls between 0 and 1, and outputs both the $x$ and $y$ values. In order to avoid getting confused with the variables we used in part two, we're going to use $u$ and $v$ instead of $x$ and $y$ respectively.
Here's the formula for a second-order Bézier curve.
$$
\begin{pmatrix} u \\ v \end{pmatrix} = (1 - t)^3 \begin{pmatrix} u_0 \\ v_0 \end{pmatrix} + 3(1 - t)^2 t \begin{pmatrix} u_1 \\ v_1 \end{pmatrix} + 3 (1 - t) t^2 \begin{pmatrix} u_2 \\ v_2 \end{pmatrix} + t^3 \begin{pmatrix} u_3 \\ v_3 \end{pmatrix} .
$$
Where $\begin{pmatrix} u_0 \\ v_0 \end{pmatrix}$, $\begin{pmatrix} u_3 \\ v_3 \end{pmatrix}$ are the start and end points of the curve respectively, and $\begin{pmatrix} u _1\\ v_1 \end{pmatrix}$, $\begin{pmatrix} u_2 \\ v_2 \end{pmatrix}$ are control points that we position in order to get our desired curve.
The fact a Bézier curve is parametric is a problem for us, because it makes it considerably more difficult to integrate under the graph. If we want to know the area under the curve, we're going to have to integrate it, so we need a way to turn the parameterised curve into a Cartesian form.
Luckily we can cheat.
If we set $\begin{pmatrix} u_1 \\ v_1 \end{pmatrix}$ and $\begin{pmatrix} u_2 \\ v_2 \end{pmatrix}$ to be $\frac{1}{3}$ and $\frac{2}{3}$ of the way along the curve respectively, then things get considerably easier. In other words, set
\begin{align*}
u_1 & = u_0 + \frac{1}{3} (u_3 - u_0) \\
& = \frac{2}{3} u_0 + \frac{1}{3} u_3 \\
\end{align*}
and
\begin{align*}
u_2 & = u_0 + \frac{2}{3} (u_3 - u_0) \\
& = \frac{1}{3} u_0 + \frac{2}{3} u_3 .
\end{align*}
Substituting this into our Bézier curve equation from earlier we get
\begin{align*}
u & = (1 - t)^3 u_0 + 3 (1 - t)^2 t \times \left( \frac{2}{3} u_0 + \frac{1}{3} u_3 \right) + 3 (1 - t) t^2 \times \left( \frac{1}{3} u_0 + \frac{2}{3} u_3 \right) + t^3 u_3 \\
& = u_0 + t (u_3 - u_0) .
\end{align*}
When we choose our $u_1$ and $u_2$ like this, we can perform the substitution
$$
\psi(t) = u_0 + t(u_3 - u_0)
$$
in order to switch between $t$ and $u$. This will make the integral much easier to solve. We note that $\psi$ is a bijection and so invertible as long as $u_3 \not= u_0$. We can therefore define the inverse:
$$
t = \psi^{-1} (u) = \frac{u - u_0}{u_3 - u_0} \\
$$
It will also be helpful to do a bit of groundwork. We find the values at the boundary as
\begin{align*}
\psi^{-1} (u_0) & = 0, \\
\psi^{-1} (u_3) & = 1, \\
\end{align*}
and we also define the following for convenience.
$$
V(u) = v(\psi^{-1} (u)) .
$$
We'll use these in the calculation of the integral under the Bézier curve, which goes as follows.
$$
\int_{u_0}^{u_3} V(u) \mathrm{d}u
$$
Using the substitution rule we get
\begin{align*}
\int_{\psi^{-1}(u_0)}^{\psi^{-1}(u_3)} & V(\psi(t)) \psi'(t)\mathrm{d}t = \int_{t = 0}^{t = 1} v(\psi^{-1}(\psi(t))) (u_3 - u_0) \mathrm{d}t \\
& = (u_3 - u_0) \int_{0}^{1} v(t) \mathrm{d}t . \\
& = (u_3 - u_0) \int_{0}^{1} (1 - t)^3 v_0 + 3 (1 - t)^2 t v_1 + 3 (1 - t) t^2 v_2 + t^3 v_3 \mathrm{d}t \\
& = (u_3 - u_0) \int_{0}^{1} (1 - 3t + 3t^2 - t^3) v_0 + 3 (t - 2t^2 + t^3) v_1 + 3 (t^2 - t^3) v_2 + t^3 v_3 \mathrm{d}t \\
& = \frac{1}{4} (u_3 - u_0) (v_0 + v_1 + v_2 + v_3) .
\end{align*}
We'll bank this calculation and come back to it. Let's now consider how we can wrap the Bézier curve over the points in our graph to make a nice curve. For each column we're going to end up with something like this.
Now as before, we don't have control over $u_0$, $v_0$ because it affects the adjoining curve. We also don't have control over $u_1$ and $u_2$ because as just described, we have these set to allow us to perform the integration. We also must have $u_3$ set as $u_3 = u_0 + w / 2$ so that it's half way along the column.
Our initial assumption wil be that $v_3 = h$, but this is the value we're going to manipulate (i.e. raising or lowering the central point) in order to get the area we need. We shouldn't need to adjust it by much.
That just leaves $v_1$ and $v_2$. We need to choose these to give us a sensible and smooth curve, which introduces some additonal constraints. We'll set the gradient at the point $u_0$ to be the gradient $g_1$ of the line that connects the heights of the centrepoints of the two adjacent columns:
$$
g_1 = \frac{y - y_L}{x - x_L}
$$
where $x, y$ are the same points we discussed in part two, and $x_L, y_L$ are the same points for the column to the left. We'll also use $x_R, y_R$ to refer to the points for the column on the right, giving us:
$$
g_2 = \frac{y_R - y}{x_R - x} .
$$
Using our value for $g_1$ we then have
$$
v_1 = v_0 + g_1 (u_1 - u_0) .
$$
For the gradient $g$ at the centre of the column, we set this to be the gradient of the line between $y_1$ and $y_2$:
$$
g = \frac{y_2 - y_1}{x_2 - x_1} .
$$
We then have that
$$
v_2 = v_3 + g (u_2 - u_3) .
$$
From these we can calculate the area under the curve using the result from our integration calculation earlier, by simply substiuting the values in. After simplifying the result, we get the following.
$$
A_1' = \frac{1}{8}(x_2 - x_1) \left( 2y' + \frac{13}{6} y_1 - \frac{1}{6} y_2 + \frac{1}{6} g_1 (x_2 - x_1) \right)
$$
where $y'$ is the height of the central point which we'll adjust in order to get the area we need. This looks nasty, but it'll get simpler. We can perform the same calculation for the right hand side to get
$$
A_2' = \frac{1}{8}(x_2 - x_1) \left( 2y' + \frac{13}{6} y_2 - \frac{1}{6} y_1 - \frac{1}{6} g_2 (x_2 - x_1) \right) .
$$
Adding the two to give the total area $A' = A_1' + A_2'$ allows us to do a bunch of simplification, giving us
$$
A' = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + y' \right) + \frac{w^2}{48} (g_1 - g_2) .
$$
If we now compare this to the $A$ we calculated for the straight line graph in part two, subtracting one from the other gives us that
$$
y' = y + \frac{w}{24} (g_2 - g_1) .
$$
This tells us how much we have to adjust $y$ by to compensate for the area change caused by the curvature of the Bézier curves.
What does this give us in practice? Here's the new smoothed graph based on the same data as before.
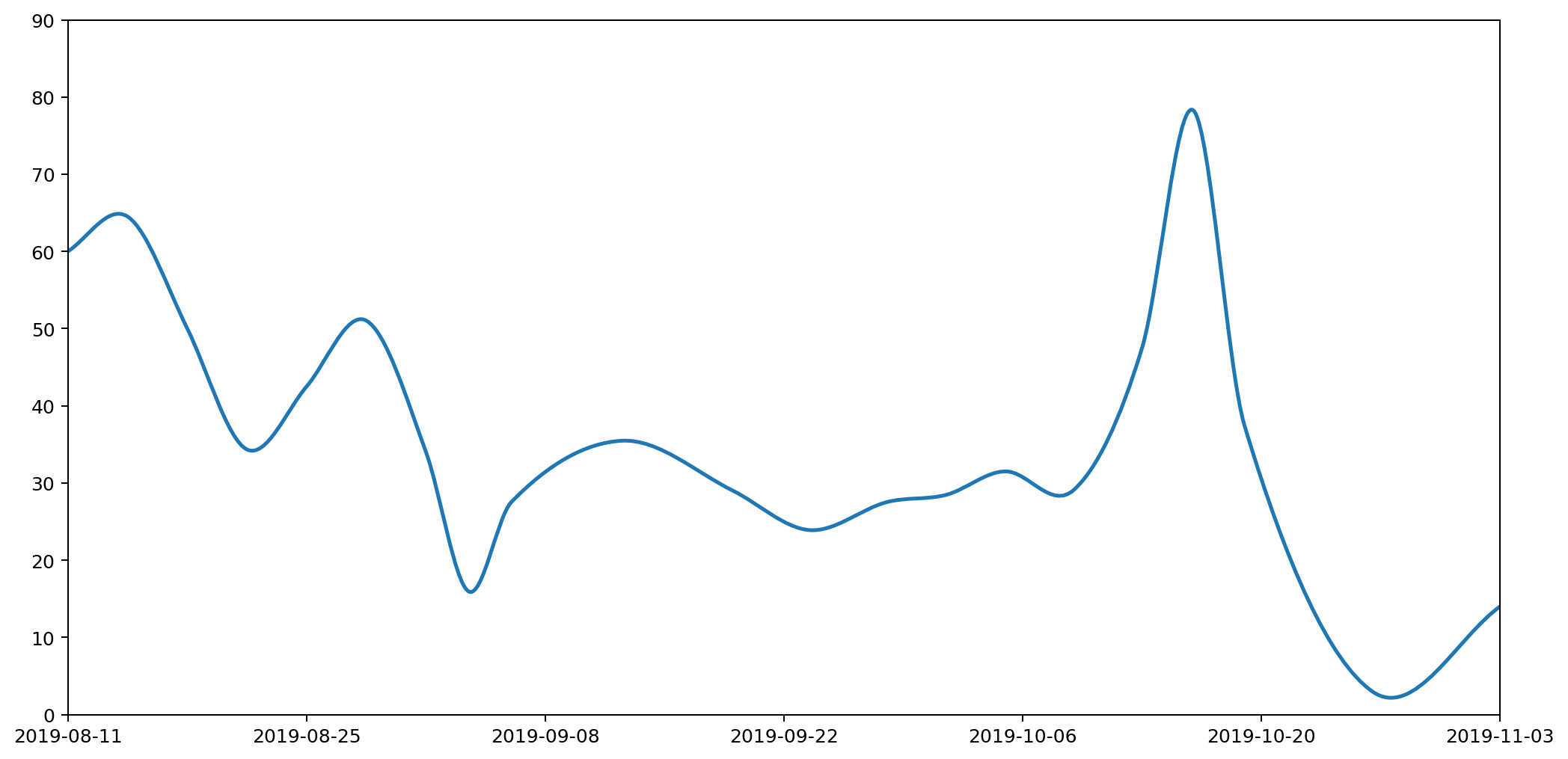
Let's overlay the three approaches — histogram, straight line and curved graphs — to see how they all compare. The important thing to note is that the area under each of the columns — bounded above by the flat line, the straight line and the curve respectively — are all the same.
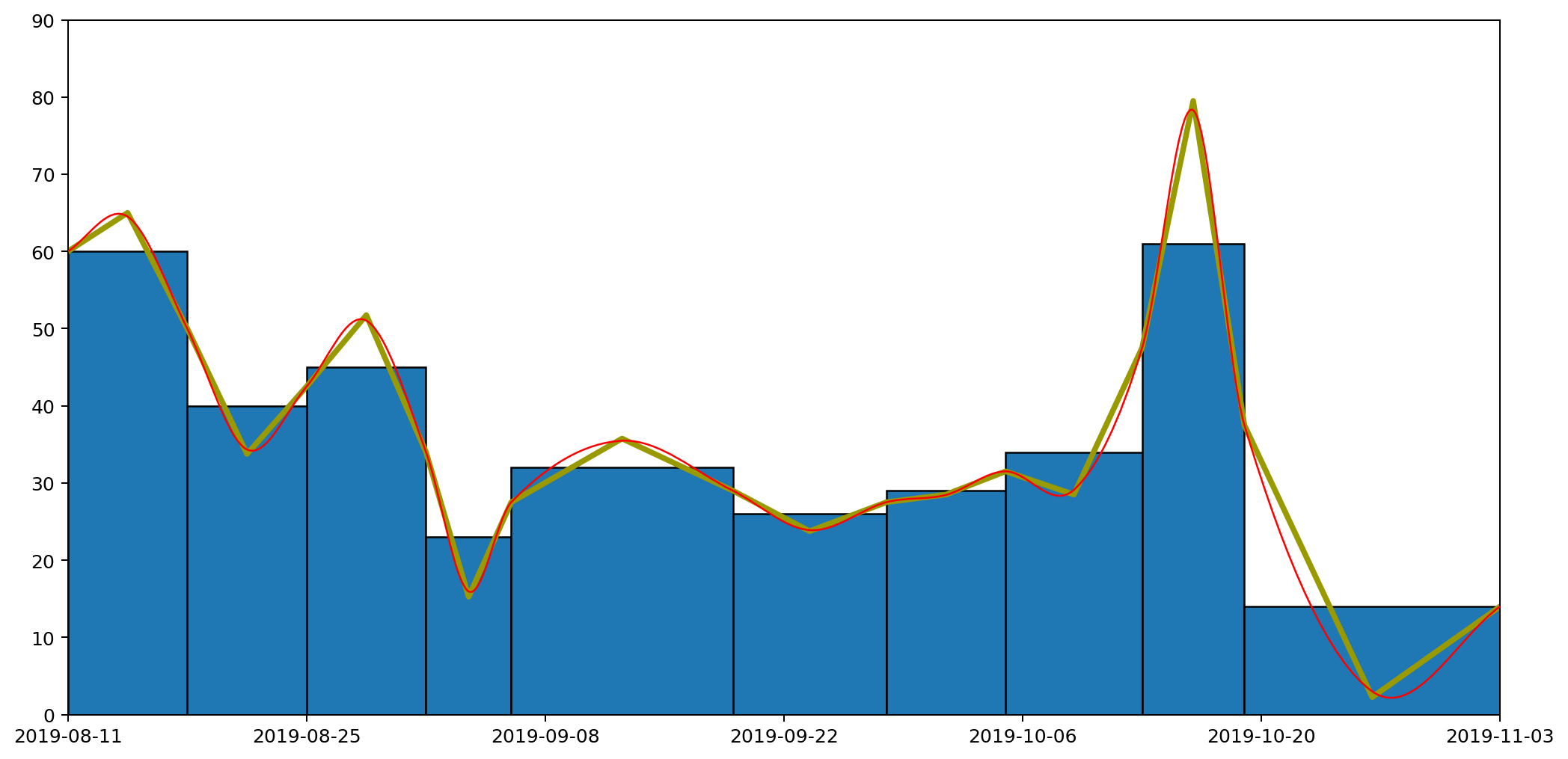
Because of the neat way Bézier curves retain their area properties, we can even stack them nicely, similarly to how we stacked our histogram in part one, to get the following representation of the full set of data.
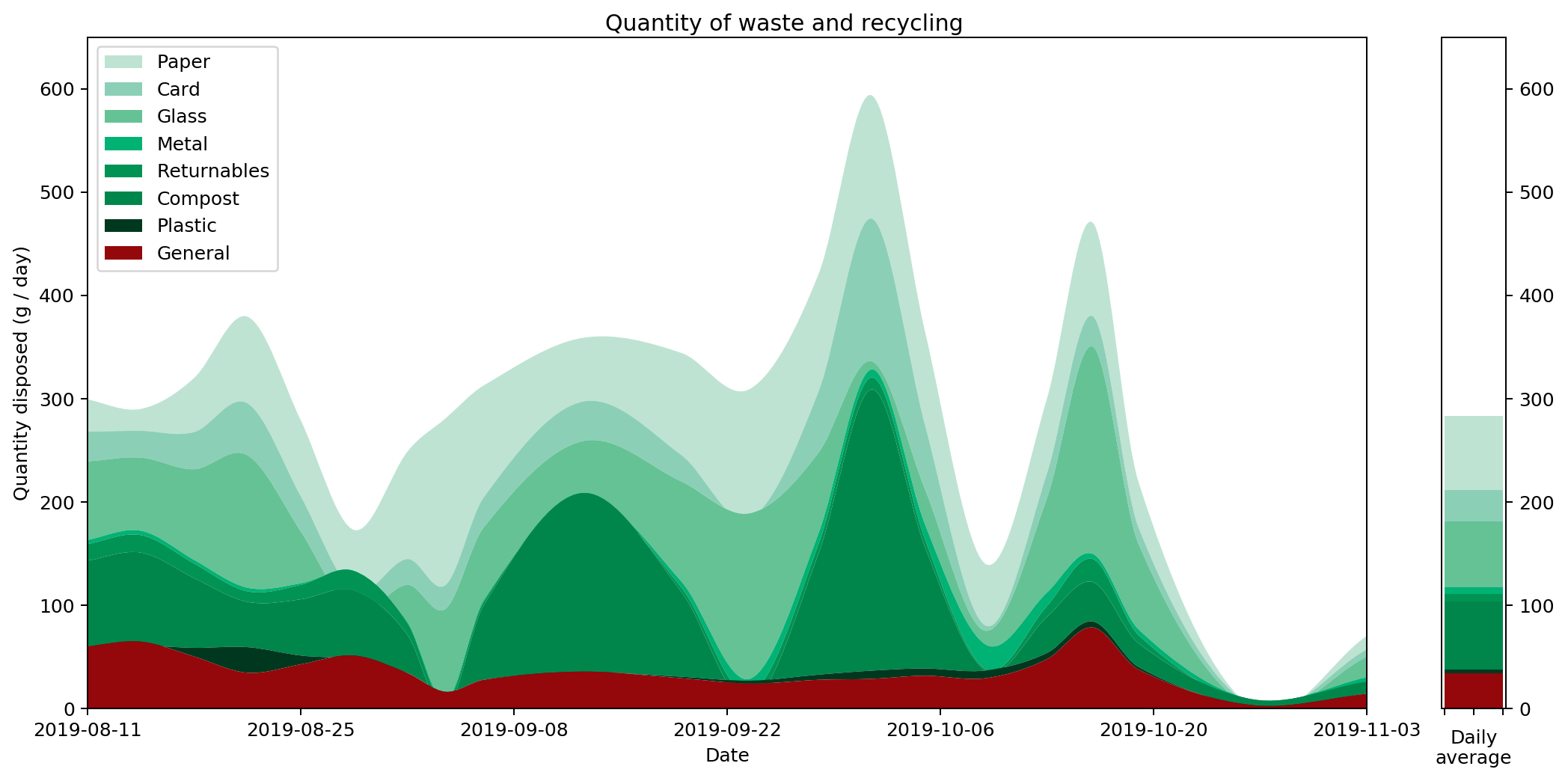
Putting all of this together, we now have a pretty straightforward way to present area-under-the-graph histograms of continuous data in a way that captures that continuity. I call this graph a "histocurve". A histocurve can give a clearer picture of the overall general trends of the data. For example, each of the strata in the histocurve remains unbroken, compared to the strata in a classic histogram which is liable to get broken at the boundary between every pair of columns.
That's all great, but it's certainly not perfect. In the fourth and final part of this series which I hope to get out on the 3rd December, I'll briefly discuss the pitfalls of histocurves, some of their negative properties, and things I'd love to fix but don't know how.
19 Nov 2019 : Sailfish Backup and Restore from Xperia XA2 to Xperia 10 #
It’ll come as no surprise to hear I’ve tried my share of phones running Sailfish OS, starting with the Jolla 1 and ending up with an Xperia XA2 via a Jolla C and Xperia X.
Yesterday I moved to the latest of the official Sailfish compatible phones, the Xperia 10. Having been using it now for a couple of days, I have to say that I’m exceptionally happy with it. It captures the understated aesthetic of the Xperia X, which I much preferred over the more brutal XA2 design that followed. But the screen is large and bright, and the long tall screen works really nicely with Sailfish OS which has always made good use of vertical space. Having an extra row of apps in the switcher makes the whole screen feel 33% bigger (even though in fact it's only 12% larger). Many apps, like Messages, Whisperfish, Depecher and Piepmatz, are built around a vertical scrolling SilicaFlickable. They all work beautifully on the tall thin screen. It turns out I'm much more excited at the move from the XA2 to the 10 than I expected.
There are some minor regressions. The camera bump is noticeably larger than on the X, and I'm still getting used to the button placement on the side (not only have the buttons moved, but they're also noticeablly harder to distinguish using touch alone). On the other hand the fingerprint reader is better placed and more responsive.

But one area where Sailfish OS deserves some love is in the upgrade process. The strong privacy-focus that makes the phone so attractive to people like me, also means that all of the data on the phone doesn’t get automatically synced to some megacorp’s datacentre. Moving from one phone to another requires a bit of manual effort, and I thought it might help some people to hear the process I went through (and even if not, it’ll certainly help me next time I go through this process). Ultimately it was pretty painless, and there’s nothing on my old phone that I don’t now have on my new phone, but it did require a few steps.
Step 1: Perform a system backup
My first step was to perform a system backup. This will backup photos, videos, accounts (minus passwords), notes and a few other bits and pieces. I’d love for it to have greater coverage, but it’s a clean, safe and stable way to capture the basic. I performed the backup to SD card, but if you have cloud accounts you could use them instead.
Step 2: Configure the new device (low-level)
There are a few default configuration steps I always like to go through. Not everyone will want to do all of this, but some might.
A. Set up a device lock and developer mode, including allowing a remote connection.
B. Enable developer updates… and update the phone.
C. Configure the hostname.
Log in to your phone using the developer password.
View the public key
E. Configure SSH to use a private/public keypair.
Having set up developer mode you can log in to the device via SSH using a password. It makes things much easier if you can also log in using a public/private key pair as well. To set this up, access the new phone using the SDK. This will neatly configure SSH on the phone.
Then log in to the phone and add the public key of the private computer you want to access your phone with to the ~/.ssh/authorized_keys file. Also add the private key of the phone you’re backup up from. If this phone doesn’t already have a public/private key pair, follow D above to create one on your old phone too.
Step 3: Install zypper
This step isn't really necessary, but I find it convenient.
Step 4: Restore the system backup
Move the SD card from the old phone to the new phone and use the system backup restore option to restored the contents of the backup to the new device.
Step 5: Copy the non-backed up stuff
As mentioned above there are a lots of things the system backup won’t capture. Many of these, like app configurations, can be neatly transferred from the old phone to the new phone anyway. To do this, log in to the old phone using SSH.
Then you can copy all the music and documents from the old phone to the new phone over the network like this.
And copy your app configurations. You should tweak this to suit the apps you have installed.
Step 6: Deploy software requiring manual installation
I use Storeman, Whisperfish and the Matrix client, all of which require manual installation (the latter two aren't in the Jolla Store or OpenRepos). Here's an example of how you can install Storeman (but make sure you update the links to use the latest available version).
Step 7: Install apps from Jolla Store and OpenRepos
I put the phones side-by-side, open the app draw on the old phone and just go through each app one by one installing them. Maybe there’s a better quicker way, but this worked for me.

Step 8: Update the accounts
For each of the accounts in the Settings app, the passwords will have been stripped from the backup for security reasons. I went through each systematically and added the passwords in again. I had some problems with a couple of accounts, so I just recreated them from scratch, copying over the details from the UI of the old phone.
Step 9: Swap the SIM cards
I use two SIM cards, which unfortunately leaves no space for the SD card.
Step 10: Manual configurations
At this point, I went through and did some manual configuration of things like the top menu, ambiances, VPNs, USB mode, Internet sharing name, Bluetooth name, Keyboards, etc.
Step 11: Install Android apps manually
Some android apps require manual installation. For me these were FDroid, APKPure and MicroG. These are essentially pre-requisiste of all of the other Android apps I use. As an example, here's how I went about installing FDroid (APKPure is similar).
APKPure can be installed in a similar way. MicroG is a bit more involved, but here's a summary of the steps:
A. Configure Android App Support to Disable Android App Support system package verification.
B. Add the MicroG repository to FDroid.
C. Check the fingerprint.
D. Search for and install microG Service Core and Fakestore.
E. Open the Android settings for MicroG, go back, re-enter and negotiate to the Apps & Notifications > App Permissions > Enable system package replacement screen.
F. Activate the system package replacement setting for MicroG and Fakestore.
G. Open MicroG and request permissions (grant them all).
H. Stop and then restart the Android App Support from the Android page in the Settings app in order finalise the MicroG configuration.
I. Open MicroG and check that everything is set up correctly.
Step 12: Install Android apps from the store
At this point, I install any other remaining Android apps that were on my old phone.
Step 13: Relax
Have a cup of tea, enjoy your new phone!
As a bit of a bootnote, I’m personally of the belief that several of these steps could be added to the automatic backup, such as the Music, Documents and app configurations. With a new device there will always be some need for fresh manual configuration. I’d love to see a better way for the apps to transfer across, but given that many of the apps are essentially sideloaded from OpenRepos, that may not be a realistic goal. At any rate, making the backup and restore process as smooth as possible is certainly something I think most users would find valuable.
Comment
Yesterday I moved to the latest of the official Sailfish compatible phones, the Xperia 10. Having been using it now for a couple of days, I have to say that I’m exceptionally happy with it. It captures the understated aesthetic of the Xperia X, which I much preferred over the more brutal XA2 design that followed. But the screen is large and bright, and the long tall screen works really nicely with Sailfish OS which has always made good use of vertical space. Having an extra row of apps in the switcher makes the whole screen feel 33% bigger (even though in fact it's only 12% larger). Many apps, like Messages, Whisperfish, Depecher and Piepmatz, are built around a vertical scrolling SilicaFlickable. They all work beautifully on the tall thin screen. It turns out I'm much more excited at the move from the XA2 to the 10 than I expected.
There are some minor regressions. The camera bump is noticeably larger than on the X, and I'm still getting used to the button placement on the side (not only have the buttons moved, but they're also noticeablly harder to distinguish using touch alone). On the other hand the fingerprint reader is better placed and more responsive.

But one area where Sailfish OS deserves some love is in the upgrade process. The strong privacy-focus that makes the phone so attractive to people like me, also means that all of the data on the phone doesn’t get automatically synced to some megacorp’s datacentre. Moving from one phone to another requires a bit of manual effort, and I thought it might help some people to hear the process I went through (and even if not, it’ll certainly help me next time I go through this process). Ultimately it was pretty painless, and there’s nothing on my old phone that I don’t now have on my new phone, but it did require a few steps.
Step 1: Perform a system backup
My first step was to perform a system backup. This will backup photos, videos, accounts (minus passwords), notes and a few other bits and pieces. I’d love for it to have greater coverage, but it’s a clean, safe and stable way to capture the basic. I performed the backup to SD card, but if you have cloud accounts you could use them instead.
Step 2: Configure the new device (low-level)
There are a few default configuration steps I always like to go through. Not everyone will want to do all of this, but some might.
A. Set up a device lock and developer mode, including allowing a remote connection.
B. Enable developer updates… and update the phone.
C. Configure the hostname.
devel-su echo NAME > /etc/hostname hostname NAME hostnamectl set_hostname NAMED. Create a public-private SSH key.
Log in to your phone using the developer password.
ssh-keygen -t rsa -b 4096 -C "david@flypig.co.uk"
View the public key
cat ~/.ssh/id_rsa.pub
E. Configure SSH to use a private/public keypair.
Having set up developer mode you can log in to the device via SSH using a password. It makes things much easier if you can also log in using a public/private key pair as well. To set this up, access the new phone using the SDK. This will neatly configure SSH on the phone.
Then log in to the phone and add the public key of the private computer you want to access your phone with to the ~/.ssh/authorized_keys file. Also add the private key of the phone you’re backup up from. If this phone doesn’t already have a public/private key pair, follow D above to create one on your old phone too.
Step 3: Install zypper
This step isn't really necessary, but I find it convenient.
devel-su pkcon install zypper
Step 4: Restore the system backup
Move the SD card from the old phone to the new phone and use the system backup restore option to restored the contents of the backup to the new device.
Step 5: Copy the non-backed up stuff
As mentioned above there are a lots of things the system backup won’t capture. Many of these, like app configurations, can be neatly transferred from the old phone to the new phone anyway. To do this, log in to the old phone using SSH.
Then you can copy all the music and documents from the old phone to the new phone over the network like this.
scp -r ~/Music nemo@192.168.1.8:~/ scp -r ~/Documents nemo@192.168.1.8:~/
And copy your app configurations. You should tweak this to suit the apps you have installed.
scp -r ~/.config nemo@192.168.1.8:~/ scp -r ~/.local/share/harbour-received nemo@192.168.1.8:~/.local/share scp -r ~/.local/share/harbour-tidings nemo@192.168.1.8:~/.local/share scp -r ~/.local/share/harbour-depecher nemo@192.168.1.8:~/.local/share scp -r ~/.local/share/harbour-sailotp nemo@192.168.1.8:~/.local/share scp -r ~/.local/share/harbour-whisperfish nemo@192.168.1.8:~/.local/shareThis step is actually rather neat. I was able to transfer the configurations for all of my native apps all from the contents of the ~/.config and .local/share directories, saving me a boat-load of time and hassle.
Step 6: Deploy software requiring manual installation
I use Storeman, Whisperfish and the Matrix client, all of which require manual installation (the latter two aren't in the Jolla Store or OpenRepos). Here's an example of how you can install Storeman (but make sure you update the links to use the latest available version).
devel-su curl -L https://openrepos.net/sites/default/files/packages/6416/harbour-storeman-0.1.6-2.armv7hl.rpm –output harbour-storeman.rpm rpm -U harbour-storeman.rpm rm harbour-storeman.rpm
Step 7: Install apps from Jolla Store and OpenRepos
I put the phones side-by-side, open the app draw on the old phone and just go through each app one by one installing them. Maybe there’s a better quicker way, but this worked for me.

Step 8: Update the accounts
For each of the accounts in the Settings app, the passwords will have been stripped from the backup for security reasons. I went through each systematically and added the passwords in again. I had some problems with a couple of accounts, so I just recreated them from scratch, copying over the details from the UI of the old phone.
Step 9: Swap the SIM cards
I use two SIM cards, which unfortunately leaves no space for the SD card.
Step 10: Manual configurations
At this point, I went through and did some manual configuration of things like the top menu, ambiances, VPNs, USB mode, Internet sharing name, Bluetooth name, Keyboards, etc.
Step 11: Install Android apps manually
Some android apps require manual installation. For me these were FDroid, APKPure and MicroG. These are essentially pre-requisiste of all of the other Android apps I use. As an example, here's how I went about installing FDroid (APKPure is similar).
cd ~/Downloads devel-su curl -L https://f-droid.org/FDroid.apk --output FDroid.apk apkd-install FDroid.apk rm Fdroid.apk
APKPure can be installed in a similar way. MicroG is a bit more involved, but here's a summary of the steps:
A. Configure Android App Support to Disable Android App Support system package verification.
B. Add the MicroG repository to FDroid.
C. Check the fingerprint.
D. Search for and install microG Service Core and Fakestore.
E. Open the Android settings for MicroG, go back, re-enter and negotiate to the Apps & Notifications > App Permissions > Enable system package replacement screen.
F. Activate the system package replacement setting for MicroG and Fakestore.
G. Open MicroG and request permissions (grant them all).
H. Stop and then restart the Android App Support from the Android page in the Settings app in order finalise the MicroG configuration.
I. Open MicroG and check that everything is set up correctly.
Step 12: Install Android apps from the store
At this point, I install any other remaining Android apps that were on my old phone.
Step 13: Relax
Have a cup of tea, enjoy your new phone!
As a bit of a bootnote, I’m personally of the belief that several of these steps could be added to the automatic backup, such as the Music, Documents and app configurations. With a new device there will always be some need for fresh manual configuration. I’d love to see a better way for the apps to transfer across, but given that many of the apps are essentially sideloaded from OpenRepos, that may not be a realistic goal. At any rate, making the backup and restore process as smooth as possible is certainly something I think most users would find valuable.
19 Nov 2019 : Graphs of Waste, Part 2: A Continuous Histogram Approach #
In part one we looked at how graphs can be a great tool for expressing the generalities in specific datasets, but how even seemingly minor changes in the choice of graphing technique can result in a graph that tells an inaccurate story.
We finished by looking at how a histogram would be a good choice for representing the particular type of data I've been collecting, to express the quantity of various types of waste (measured by weight) as the area under the graph. Here's the example data plotted as a histogram.
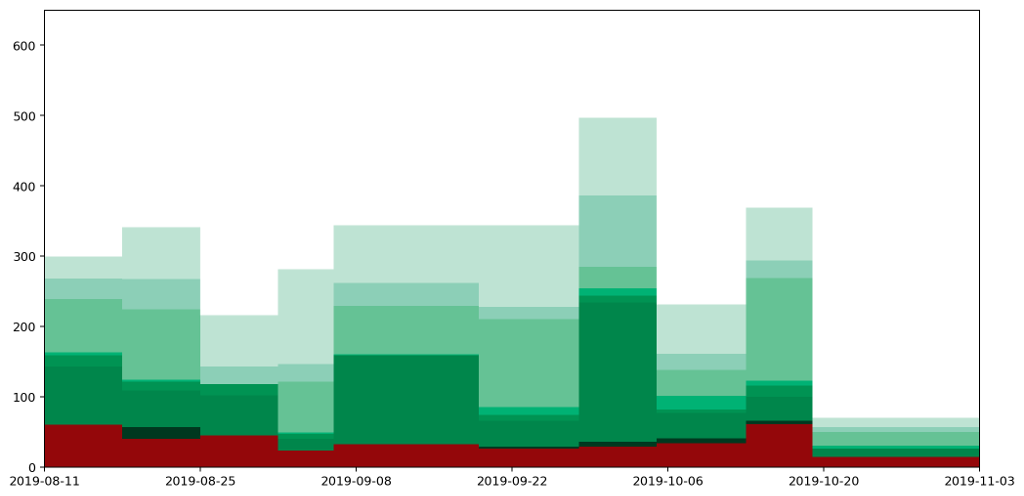
While this is good at presenting the general picture, I really want to also express how my waste generation is part of a continuous process. In the very first graph I generated to try to understand my waste output, I drew the datapoints and joined them with lines. This wasn't totally crazy as it highlighted the trends over time. However, it gave completely the wrong impression because the area under the graph bore no relation to the amount of waste I produced.
How can we achieve both? Show a continuous change of the data by joining datapoints with lines, while also ensuring the area under the graph represents the actual amount of waste produced?
The histogram above achieves the goal of having the area under the graph represent the all-important quantities captured by the data clearly visible in the graph. But it doesn't express the continuous nature of the data.
Contrariwise, if we were to take the point at the top of each histogram column and join them up, we'd have a continuous line across the graph, but the area underneath would no longer represent useful data.
If we want to capture a `middle ground' between the two, it's helpful to apply some additional constraints.
To do this, we'll adjust the position of the datapoints for each of the readings and introduce a new point in between every pair of existing datapoints as follows.
Following these rules we end up with something like this.
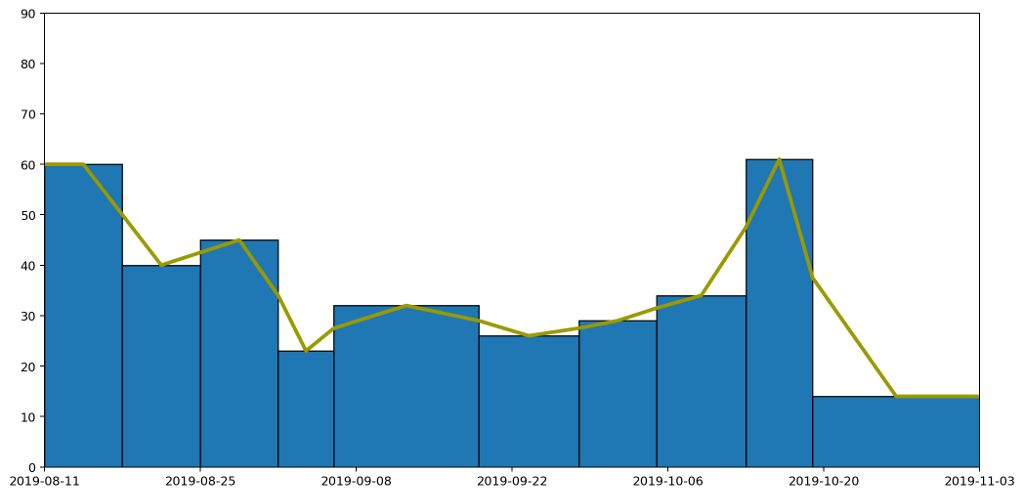
This gives us our continuous line, but as you can see from the diagram, for each column the area under the line doesn't necessarily represent the quantity captured by the data. We can see this more easily by focussing in on one of the columns. The hatched area in the picture below shows area that used to be included, but which would be removed if we drew our line like this, making the area under the line for this particular region less than it should be.

Across the entire width of these graphs the additions might cancel out the subtractions, but that's not guaranteed, and it also fails our second requirement that the area under the line should be the same as the area under the histogram column for each column individually.
To address this we can adjust the position of the point in the centre of each column by altering its height to capture the correct amount of area. In the case shown above, we'd need to move the point higher because we've cut off some of the area and need to get it back. In other cases we may need to reduce the height of the point to remove area that we over-captured.
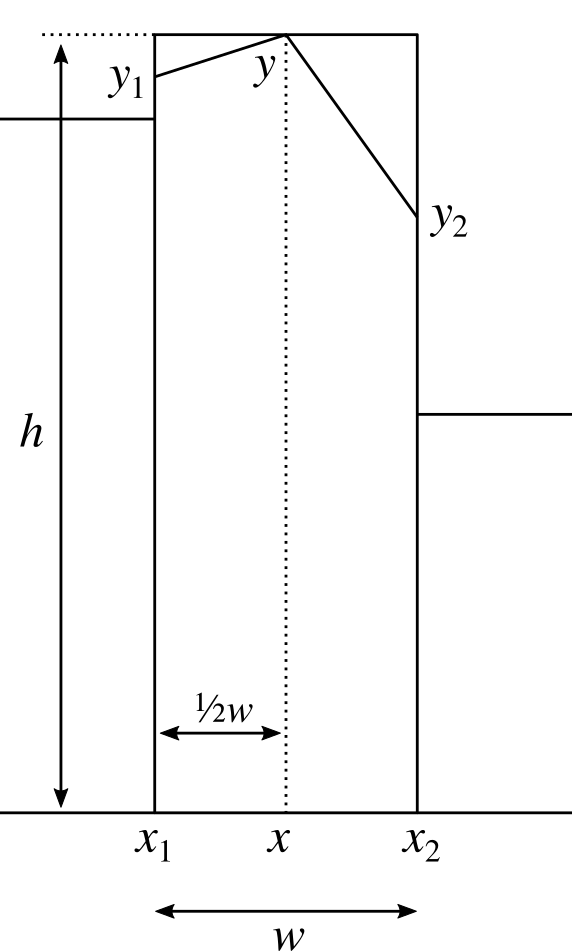
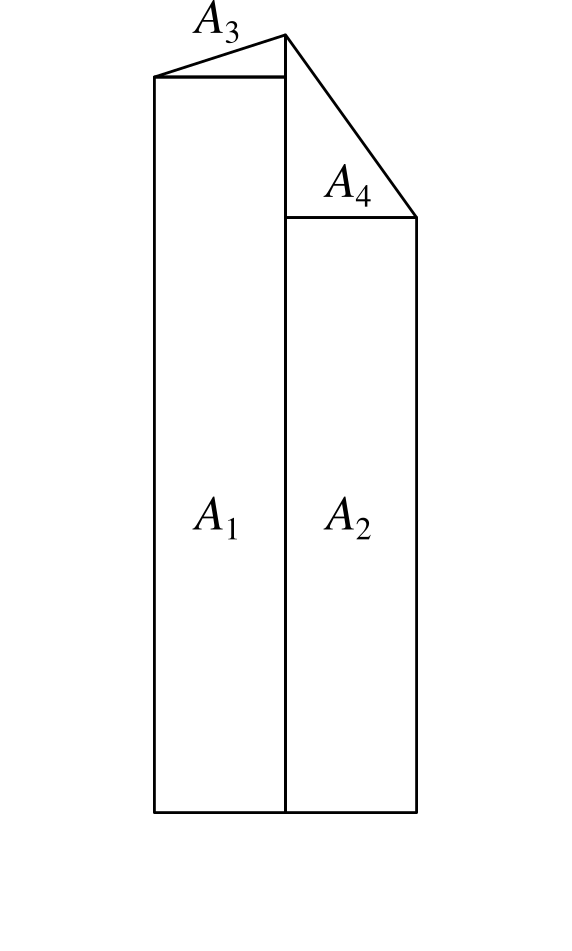 To calculate the exact height of the central point, we can use the following formula.
To calculate the exact height of the central point, we can use the following formula.
$$ y = 2h - \frac{1}{2} (y_1 + y_2) .
$$
The area $A = A_1 + A_2 + A_3 + A_4$ under the curve can then be calculated as follows.
\begin{align*} A & = \left( \frac{w}{2} \times y_1 \right) + \left( \frac{w}{2} \times y_2 \right) + \left( \frac{1}{2} \times \frac{w}{2} \times (y - y_1) \right) + \left( \frac{1}{2} \times \frac{w}{2} \times (y - y_3) \right) \\ & = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + y \right) . \\ \end{align*}
Substituting $y$ into this we get the following.
\begin{align*} A & = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + 2h - \frac{1}{2} y_1 - \frac{1}{2} y_2 \right) \\ & = wh. \end{align*}
Which is the area of the column as required.
Following this approach we end up with a graph like this.
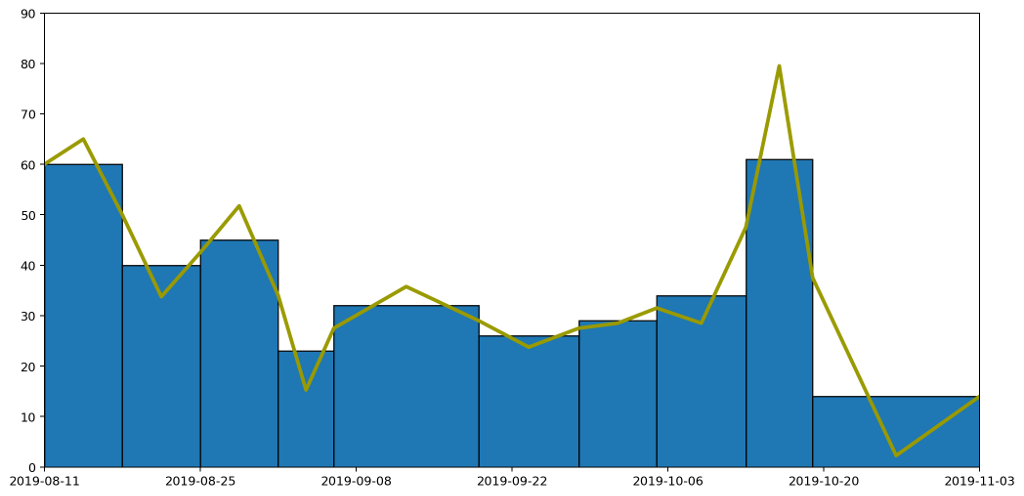
Which taken on its own gives a clear idea of the trend over time, while still capturing the overall quantity of waste produced in each period as the area under the graph.
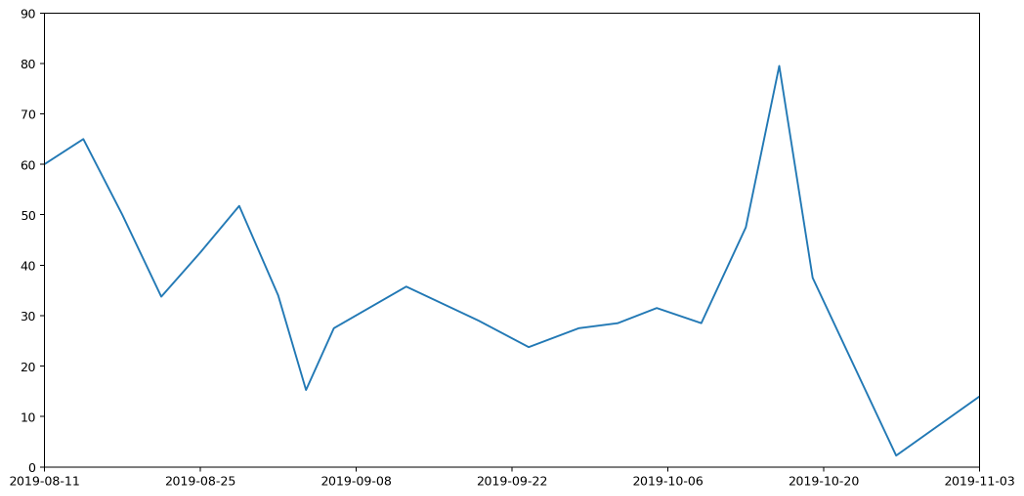
In the next part we'll look at how we can refine this further by rendering a smooth curve, rather than straight lines, but in a way that retains the same properties we've been requiring here.
All of the graphs here were produced using the superb MatPlotLib and the equations rendered using MathJax (the first time I'm using it, and it looks like it's done a decent job).
Comment
We finished by looking at how a histogram would be a good choice for representing the particular type of data I've been collecting, to express the quantity of various types of waste (measured by weight) as the area under the graph. Here's the example data plotted as a histogram.
While this is good at presenting the general picture, I really want to also express how my waste generation is part of a continuous process. In the very first graph I generated to try to understand my waste output, I drew the datapoints and joined them with lines. This wasn't totally crazy as it highlighted the trends over time. However, it gave completely the wrong impression because the area under the graph bore no relation to the amount of waste I produced.
How can we achieve both? Show a continuous change of the data by joining datapoints with lines, while also ensuring the area under the graph represents the actual amount of waste produced?
The histogram above achieves the goal of having the area under the graph represent the all-important quantities captured by the data clearly visible in the graph. But it doesn't express the continuous nature of the data.
Contrariwise, if we were to take the point at the top of each histogram column and join them up, we'd have a continuous line across the graph, but the area underneath would no longer represent useful data.
If we want to capture a `middle ground' between the two, it's helpful to apply some additional constraints.
- The line representing the weights should be continuous.
- The area under the line should be the same as the area under the histogram column for each column individually.
- For each reading, the line can be affected by the readings either side (this is inevitable if the constraint 1 is going to be enforced), but should be independent of anything further away.
To do this, we'll adjust the position of the datapoints for each of the readings and introduce a new point in between every pair of existing datapoints as follows.
- Start with the datapoints positioned to be horizontally centred in each column and taken as the height of the histogram column that encloses it.
- For every pair of datapoints A and B, place an additional point at the boundary of the columns for A and B, and with y value set as the average between the two columns A and B.
Following these rules we end up with something like this.
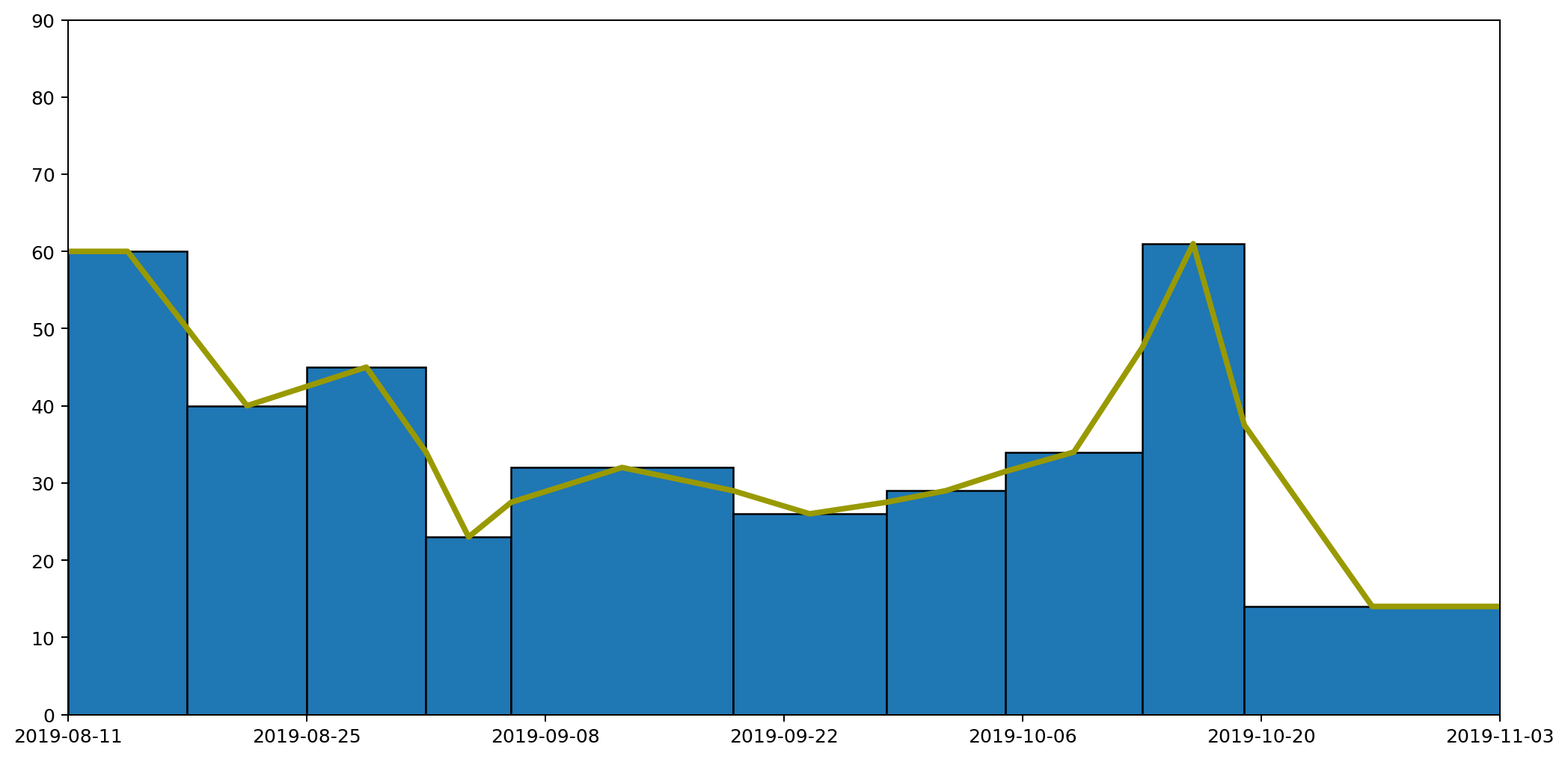
This gives us our continuous line, but as you can see from the diagram, for each column the area under the line doesn't necessarily represent the quantity captured by the data. We can see this more easily by focussing in on one of the columns. The hatched area in the picture below shows area that used to be included, but which would be removed if we drew our line like this, making the area under the line for this particular region less than it should be.
Across the entire width of these graphs the additions might cancel out the subtractions, but that's not guaranteed, and it also fails our second requirement that the area under the line should be the same as the area under the histogram column for each column individually.
To address this we can adjust the position of the point in the centre of each column by altering its height to capture the correct amount of area. In the case shown above, we'd need to move the point higher because we've cut off some of the area and need to get it back. In other cases we may need to reduce the height of the point to remove area that we over-captured.
$$ y = 2h - \frac{1}{2} (y_1 + y_2) .
$$
The area $A = A_1 + A_2 + A_3 + A_4$ under the curve can then be calculated as follows.
\begin{align*} A & = \left( \frac{w}{2} \times y_1 \right) + \left( \frac{w}{2} \times y_2 \right) + \left( \frac{1}{2} \times \frac{w}{2} \times (y - y_1) \right) + \left( \frac{1}{2} \times \frac{w}{2} \times (y - y_3) \right) \\ & = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + y \right) . \\ \end{align*}
Substituting $y$ into this we get the following.
\begin{align*} A & = \frac{w}{2} \left( \frac{1}{2} y_1 + \frac{1}{2} y_2 + 2h - \frac{1}{2} y_1 - \frac{1}{2} y_2 \right) \\ & = wh. \end{align*}
Which is the area of the column as required.
Following this approach we end up with a graph like this.
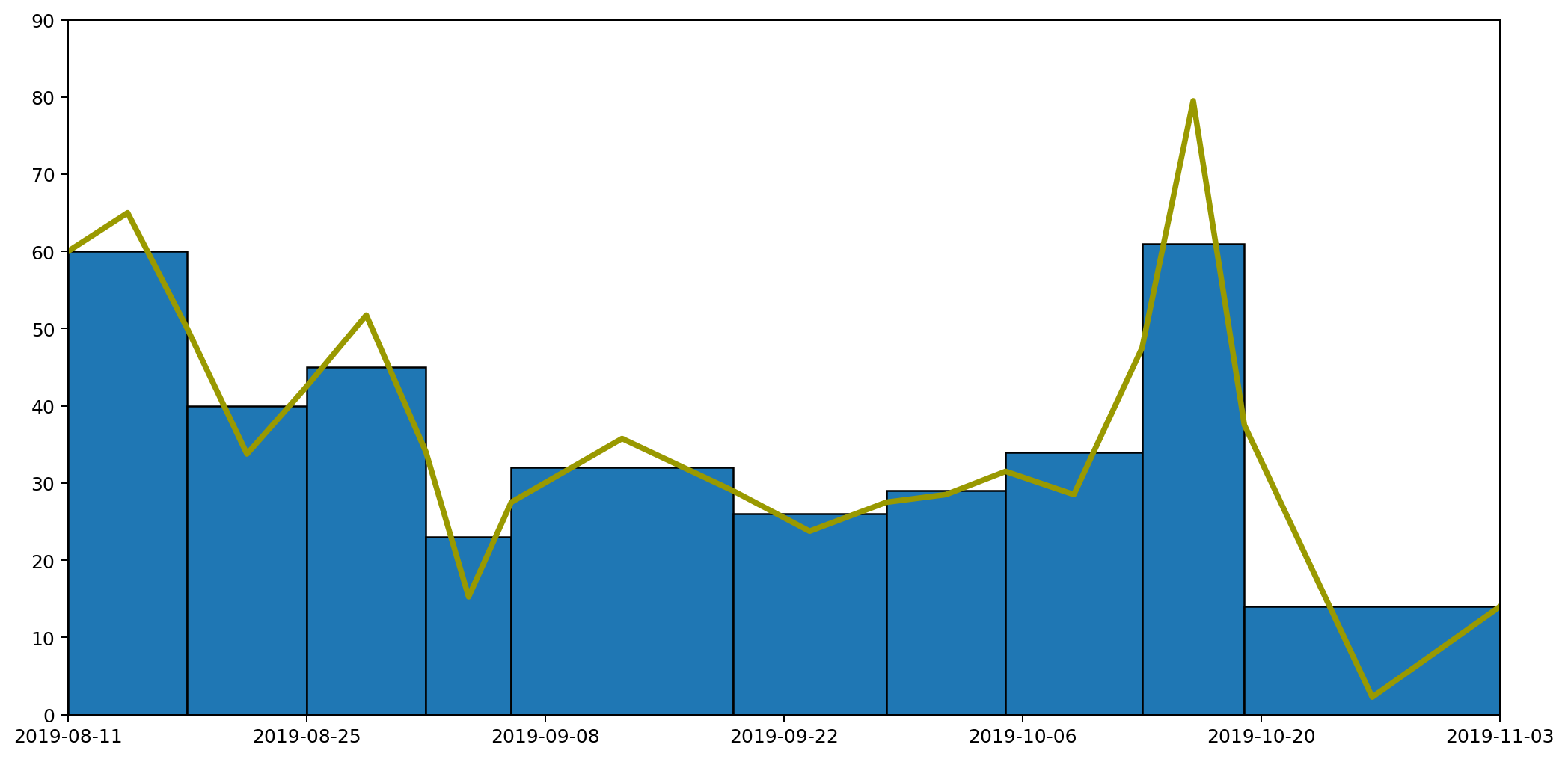
Which taken on its own gives a clear idea of the trend over time, while still capturing the overall quantity of waste produced in each period as the area under the graph.
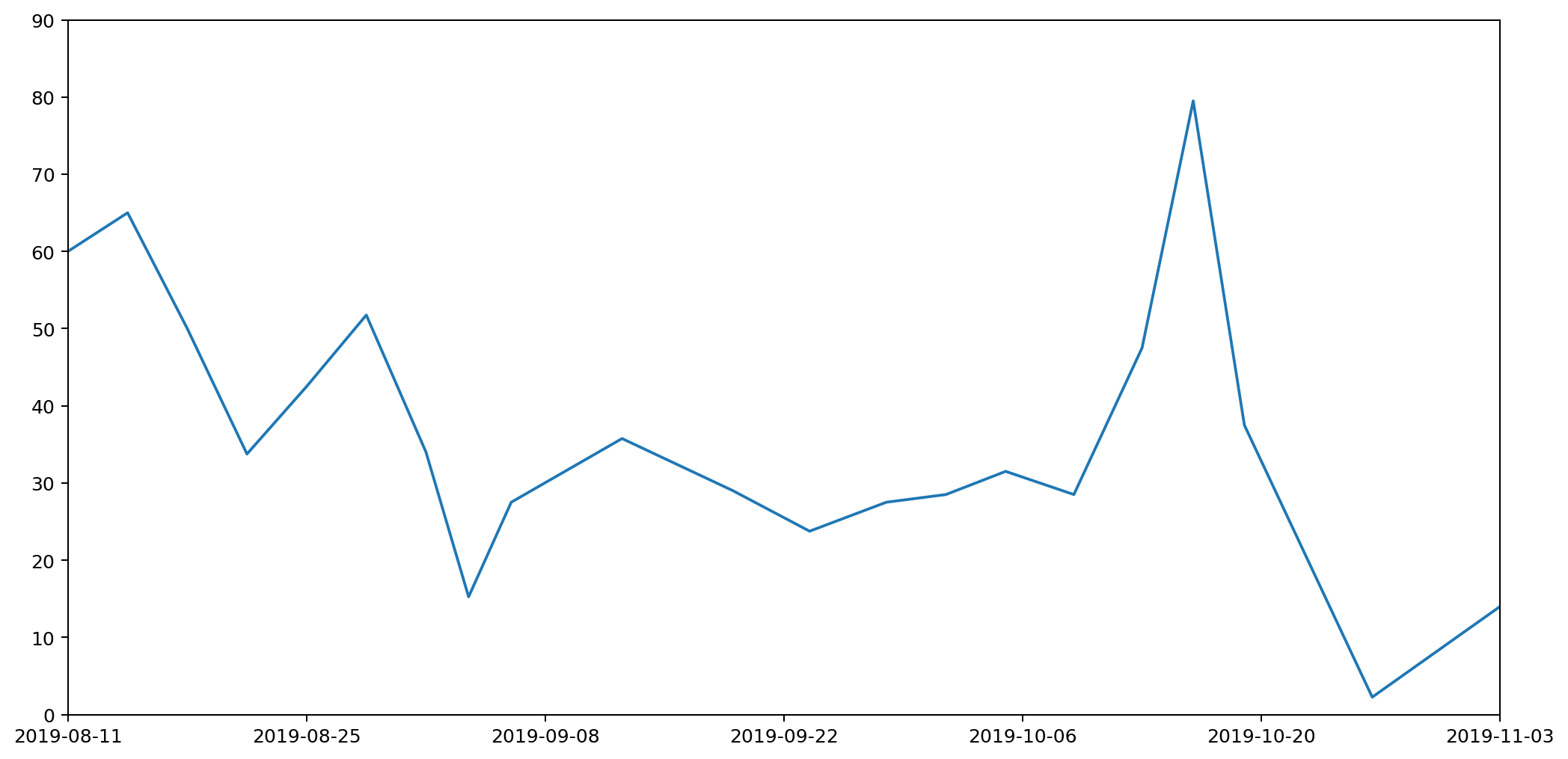
In the next part we'll look at how we can refine this further by rendering a smooth curve, rather than straight lines, but in a way that retains the same properties we've been requiring here.
All of the graphs here were produced using the superb MatPlotLib and the equations rendered using MathJax (the first time I'm using it, and it looks like it's done a decent job).
12 Nov 2019 : Graphs of Waste, Part 1: Choose Your Graph Wisely #
I have to admit I'm a bit of a data visualisation pedant. If I see data presented in a graph, I want the type of graph chosen to match the expressive aim of the visualisation. A graph should always aim to expose some underlying aspect of the data that would be hard to discern just by looking at the data in a table. Getting this right means first and foremost choosing the correct modality, but beyond that the details are important too: colours, line thicknesses, axis formats, labels, marker styles. All of these things need careful consideration.
You may think this is all self-evident, and that anyone taking the trouble to plot data in a graph will obviously have taken these things into account, but sadly it's rarely the case. I see data visualisation abominations on a daily basis. What's more it's often the people you'd expect to be best at it who turn out to fall into the worst traps. Over fifteen years of reviewing academic papers in computer science, I've seen numerous examples of terrible data visualisation. These papers are written by people who have both access to and competence in the best visualisation tooling, and who presumably have a background in analytical thinking, and yet graphs presented in papers often fail the most basic requirements. It's not unusual to see graphs that are too small to read, with unlabelled axes, missing units, use of colour in greyscale publications, or with continuous lines drawn between unrelated discrete data points.
And that's without even mentioning pseudo-3D projections or spider graphs.
One day I'll take the time to write up some of these data visualisation horror stories, but right now I want to focus on one of my own infractions. I'll warn you up front that it's not a pretty story, but I'm hoping it will have a happy ending. I'm going to talk about how I created a most terrible graph, and how I've attempted to redeem myself by developing what I believe is a much clearer representation of the data.
Over the last couple of months I've been collecting data on how much waste and recycling I generate. Broadly speaking this is for environmental and motivational reasons: I believe that if I make myself more aware of how much rubbish I'm producing, it'll motivate me to find ways to reduce it, and also help me understand where my main areas for improvement are. If I'm honest I don't expect it'll work (many years ago I was given a device for measuring real-time electricity usage with a similar aim and I can't say that succeeded), but for now it's important to understand my motivations. It goes to the heart of what makes a good graphing choice.
So, each week I weigh my rubbish using kitchen scales, categorised into different types matching the seven different recycling bins provided for use in my apartment complex.

Here's the data I've collected until now presented in a table.
We can't tell a great deal from this table. We can certainly read off the measurements very easily and accurately, but beyond that the table fails to give any sort of overall picture or idea of trends.
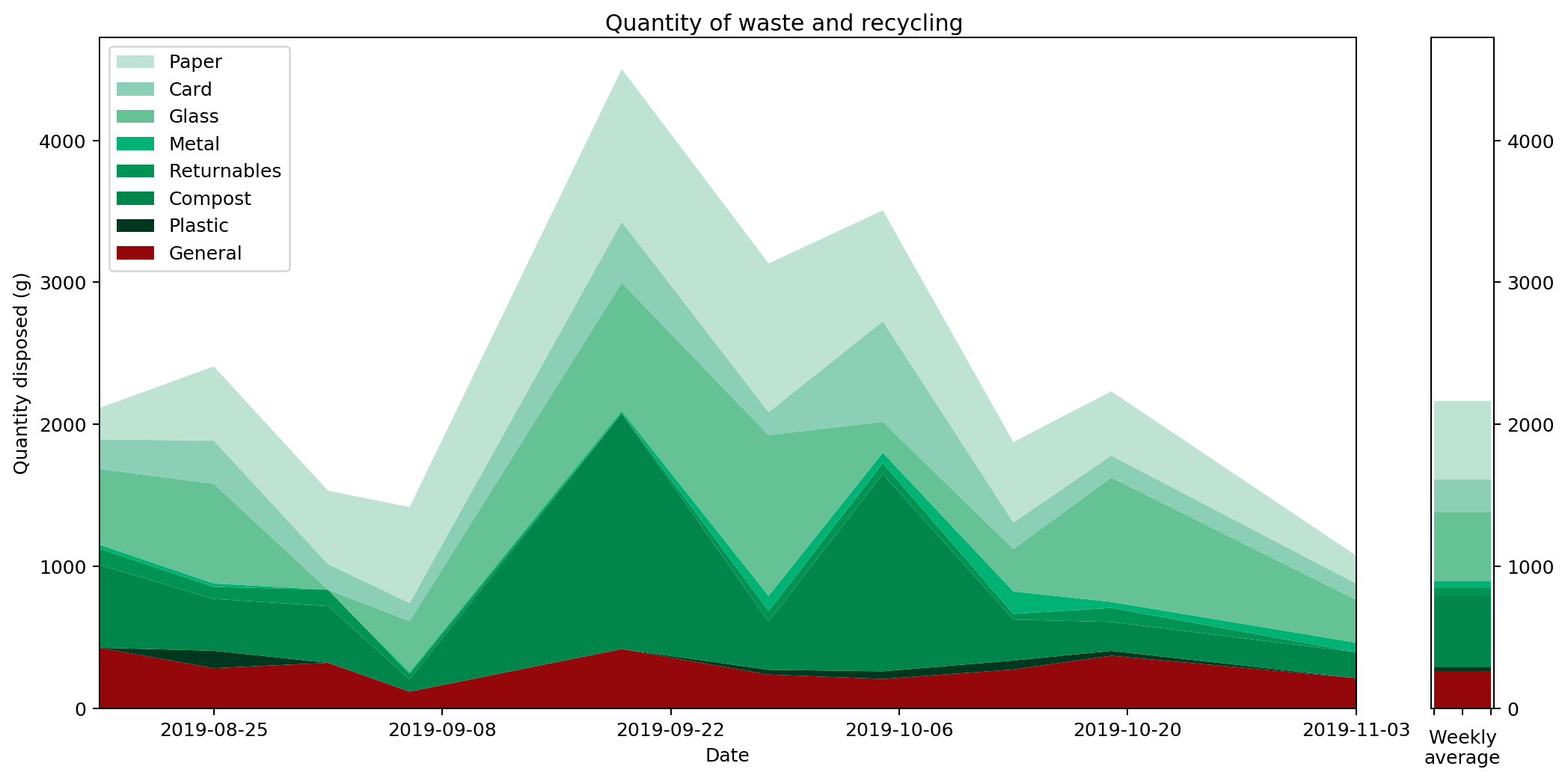
The obvious thing to do is therefore to draw a graph and hope to tease out something that way. So, here's the graph I came up with, and which I've had posted and updated on my website for a couple of months.
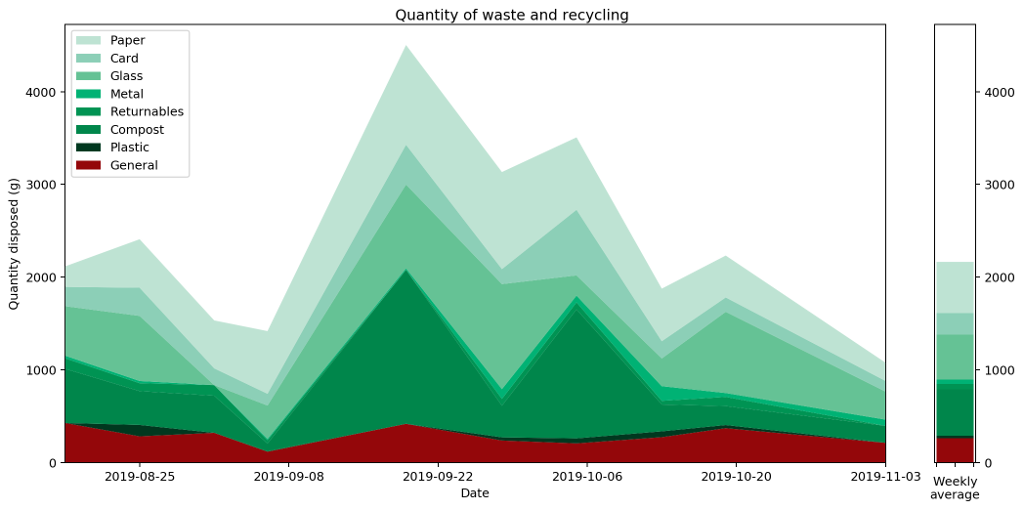
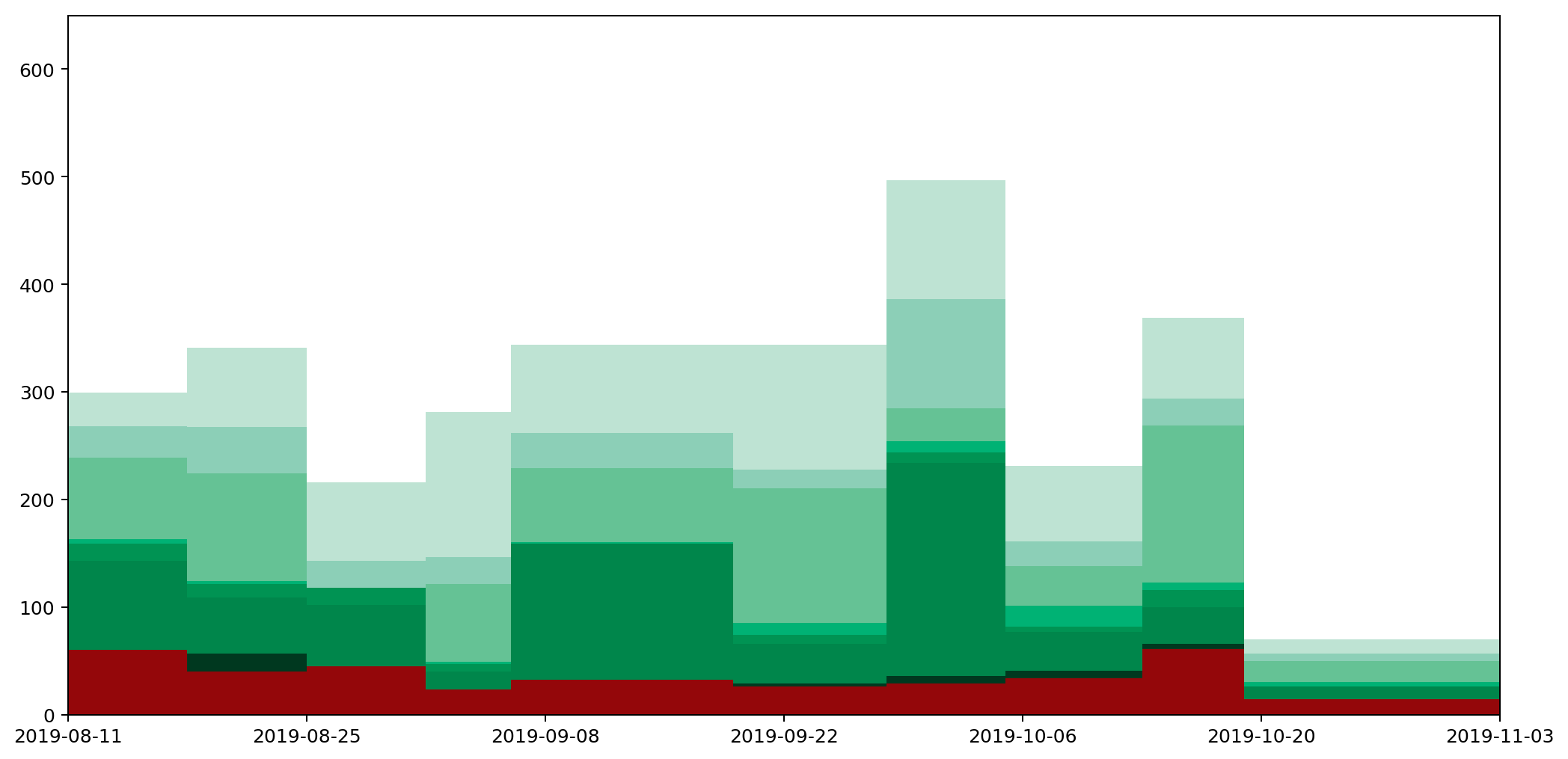
What does this graph show? Well, to be precise, it's a stacked plot of the weight measurements against the dates the measurements were taken. It gives a pretty clear picture of how much waste I produced over a period of time. We can see that my waste output increased and peaked before falling again, and that this was mostly driven by changes in the weight of compost I produced.
Or does it? In fact, as the data accumulated on the graph, it became increasingly clear that this is a misleading visualisation. Even though it's an accurate plot of the measurements taken, it gives completely the wrong idea about how much waste I've been generating.
To understand this better, let's consider just one of the stacked plots. The red area down at the base is showing the measurements I took for general waste. Here's another graph that shows the same data isolated from the other types of waste and plotted on a more appropriate scale.
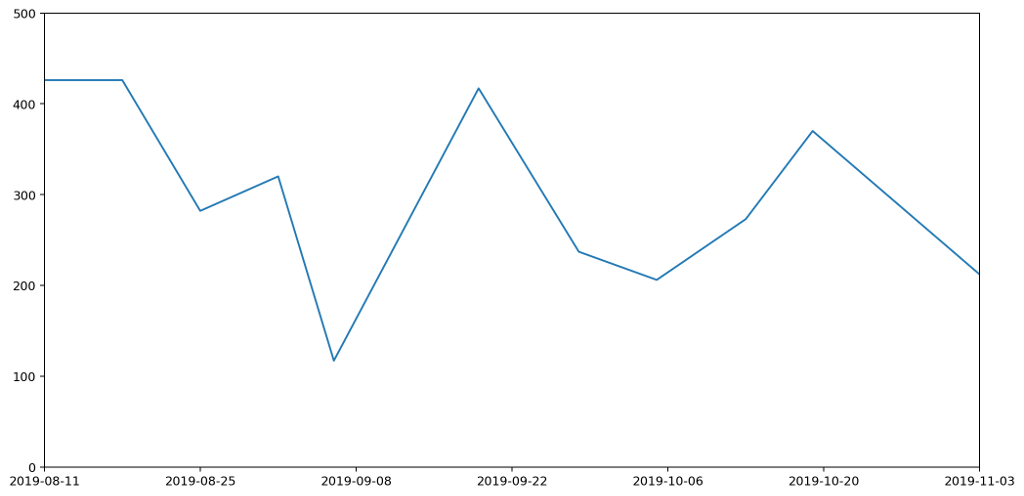
If you're really paying attention you'll notice that the start date on this second graph is different to that of the first. That's because the very first datapoint represents my waste output for the seven days prior to the reading, and we'll need those extra seven days for comparison with some of the other plots we'll be looking at shortly.
There are several things wrong with this plot, but the most serious issue, the one I want to focus on, is that it gives a completely misleading impression of how much waste I've been generating. That's because the most natural way to interpret this graph would be to read off the value for any given day and assume that's how much waste was generated that day. This would leave the area under the graph being the total amount of waste output. In fact the lines simply connect different data points. The actual datapoints themselves don't represent the amount of waste generated in a day, but in fact the amount generated in a week. And because I don't always take my measurements at the same time each week, they don't even represent a week's worth of rubbish. To find out the daily waste generated, I'd need to divide a specific reading by the number of days since the last reading.
Take for example the measurements taken on the 6th September. I usually weight my rubbish on a Saturday, but because I went on holiday on the 7th I had to do the weighing a day early. Then I was away from home for seven days, came back and didn't then weight my rubbish again until the 19th, nearly two weeks later.
Although I spent a chunk of this time away, it still meant that the reading was high, making it look as if I'd generated a lot of waste over the two-week period. In fact, considering this was double the time of the usual readings, it was actually a relatively low reading. This should be reflected in the graph, but it's not. It looks like I generated more rubbish than expected; in fact I generated less.
We can see this more clearly if we plot the data as a column (bar) graph and as a histogram. Here's the column graph first.
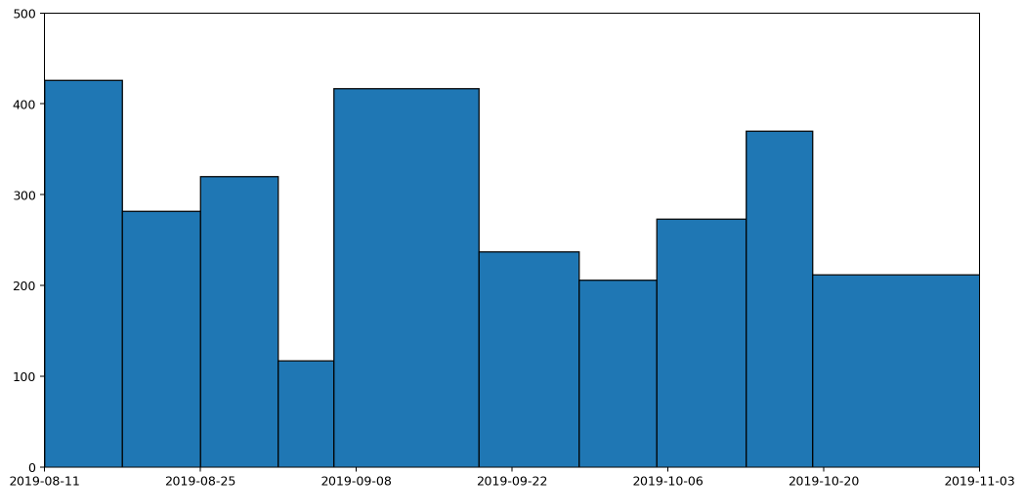
These are the same datapoints as in the previous graph, but drawn as columns with widths proportional to the duration that the readings represent. The column that spreads across from the 6th to the 19th September is the reading we've just been discussing. This is a tall, wide, column because it represents a long period (nearly two weeks) and a heaver than usual weight reading (because it's more than a weeks' worth of rubbish). If we now convert this into a histogram, it'll give us a clearer picture of how much waste was being generated per day.
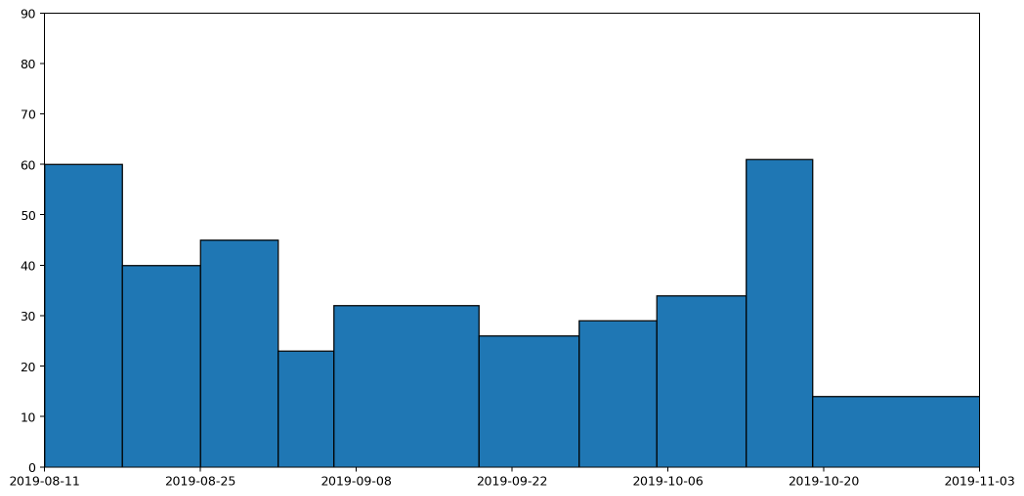
This histogram takes each of the columns and divides it by the number of days the column represents. A histogram has the nice property that the area — rather than the height — of a column represents the value being plotted. In this histogram, the area under all of the columns represents the quantity of waste that I've generated across the entire period: the more blue, the more waste.
Not only is this a much clearer representation, it also completely changes the picture. The original graph made it look like my waste output peaked in the middle. There is a slight rise in the middle, but it's actually just a local maximum. In fact the overall trend was that my daily general waste output was decreasing until the middle of the period, and then rose slightly over time. That's a much more accurate reflection of what actually happened.
It would be possible to render the data as a stacked histogram, and to be honest I'd be happy with that. The overall picture, which ties in with my motivation for wanting the graph in the first place, indicates how much waste I'm generating based on the area under the graph.
But in fact I tend to be generating small bits of rubbish throughout the week, and I'd like to see the trend between readings, so it would be reasonable to draw a line between weeks rather than have them as histogram blocks or columns.
So this leads us down the path of how we might draw a graph that captures these trends, but still also retains the nice property that the area under the graph represents the amount of waste produced.
That's what I'll be exploring in part two.
All of the graphs here were generated using the superb MatPlotLib.
Comment
You may think this is all self-evident, and that anyone taking the trouble to plot data in a graph will obviously have taken these things into account, but sadly it's rarely the case. I see data visualisation abominations on a daily basis. What's more it's often the people you'd expect to be best at it who turn out to fall into the worst traps. Over fifteen years of reviewing academic papers in computer science, I've seen numerous examples of terrible data visualisation. These papers are written by people who have both access to and competence in the best visualisation tooling, and who presumably have a background in analytical thinking, and yet graphs presented in papers often fail the most basic requirements. It's not unusual to see graphs that are too small to read, with unlabelled axes, missing units, use of colour in greyscale publications, or with continuous lines drawn between unrelated discrete data points.
And that's without even mentioning pseudo-3D projections or spider graphs.
One day I'll take the time to write up some of these data visualisation horror stories, but right now I want to focus on one of my own infractions. I'll warn you up front that it's not a pretty story, but I'm hoping it will have a happy ending. I'm going to talk about how I created a most terrible graph, and how I've attempted to redeem myself by developing what I believe is a much clearer representation of the data.
Over the last couple of months I've been collecting data on how much waste and recycling I generate. Broadly speaking this is for environmental and motivational reasons: I believe that if I make myself more aware of how much rubbish I'm producing, it'll motivate me to find ways to reduce it, and also help me understand where my main areas for improvement are. If I'm honest I don't expect it'll work (many years ago I was given a device for measuring real-time electricity usage with a similar aim and I can't say that succeeded), but for now it's important to understand my motivations. It goes to the heart of what makes a good graphing choice.
So, each week I weigh my rubbish using kitchen scales, categorised into different types matching the seven different recycling bins provided for use in my apartment complex.

Here's the data I've collected until now presented in a table.
| Date | Paper | Card | Glass | Metal | Returnables | Compost | Plastic | General |
|---|---|---|---|---|---|---|---|---|
| 18/08/19 | 221 | 208 | 534 | 28 | 114 | 584 | 0 | 426 |
| 25/08/19 | 523 | 304 | 702 | 24 | 85 | 365 | 123 | 282 |
| 01/09/19 | 517 | 180 | 0 | 0 | 115 | 400 | 0 | 320 |
| 06/09/19 | 676 | 127 | 360 | 14 | 36 | 87 | 0 | 117 |
| 19/09/19 | 1076 | 429 | 904 | 16 | 0 | 1661 | 0 | 417 |
| 28/09/19 | 1047 | 162 | 1133 | 105 | 74 | 341 | 34 | 237 |
| 05/10/19 | 781 | 708 | 218 | 73 | 76 | 1391 | 54 | 206 |
| 13/10/19 | 567 | 186 | 299 | 158 | 40 | 289 | 63 | 273 |
We can't tell a great deal from this table. We can certainly read off the measurements very easily and accurately, but beyond that the table fails to give any sort of overall picture or idea of trends.
The obvious thing to do is therefore to draw a graph and hope to tease out something that way. So, here's the graph I came up with, and which I've had posted and updated on my website for a couple of months.
What does this graph show? Well, to be precise, it's a stacked plot of the weight measurements against the dates the measurements were taken. It gives a pretty clear picture of how much waste I produced over a period of time. We can see that my waste output increased and peaked before falling again, and that this was mostly driven by changes in the weight of compost I produced.
Or does it? In fact, as the data accumulated on the graph, it became increasingly clear that this is a misleading visualisation. Even though it's an accurate plot of the measurements taken, it gives completely the wrong idea about how much waste I've been generating.
To understand this better, let's consider just one of the stacked plots. The red area down at the base is showing the measurements I took for general waste. Here's another graph that shows the same data isolated from the other types of waste and plotted on a more appropriate scale.
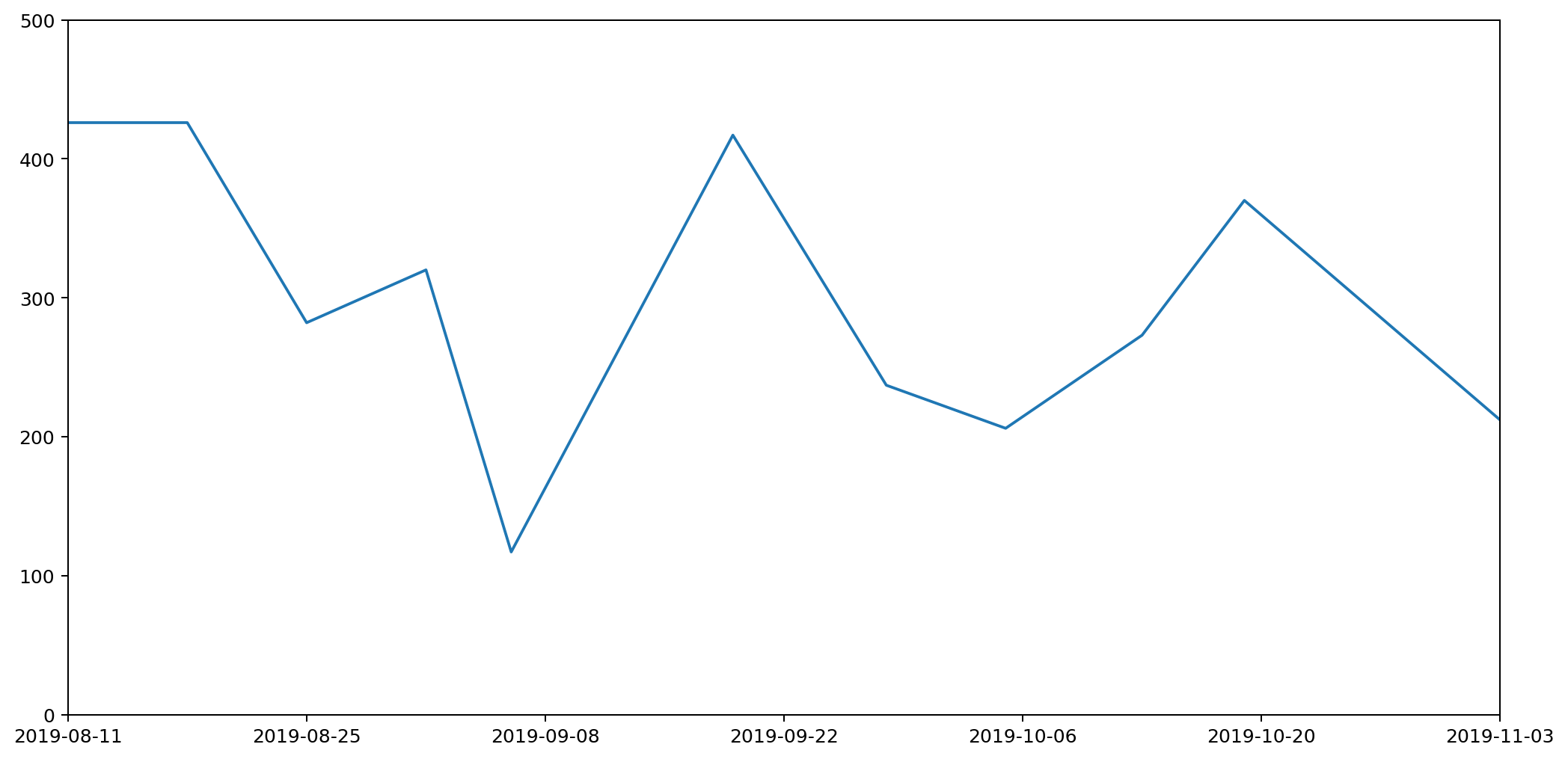
If you're really paying attention you'll notice that the start date on this second graph is different to that of the first. That's because the very first datapoint represents my waste output for the seven days prior to the reading, and we'll need those extra seven days for comparison with some of the other plots we'll be looking at shortly.
There are several things wrong with this plot, but the most serious issue, the one I want to focus on, is that it gives a completely misleading impression of how much waste I've been generating. That's because the most natural way to interpret this graph would be to read off the value for any given day and assume that's how much waste was generated that day. This would leave the area under the graph being the total amount of waste output. In fact the lines simply connect different data points. The actual datapoints themselves don't represent the amount of waste generated in a day, but in fact the amount generated in a week. And because I don't always take my measurements at the same time each week, they don't even represent a week's worth of rubbish. To find out the daily waste generated, I'd need to divide a specific reading by the number of days since the last reading.
Take for example the measurements taken on the 6th September. I usually weight my rubbish on a Saturday, but because I went on holiday on the 7th I had to do the weighing a day early. Then I was away from home for seven days, came back and didn't then weight my rubbish again until the 19th, nearly two weeks later.
Although I spent a chunk of this time away, it still meant that the reading was high, making it look as if I'd generated a lot of waste over the two-week period. In fact, considering this was double the time of the usual readings, it was actually a relatively low reading. This should be reflected in the graph, but it's not. It looks like I generated more rubbish than expected; in fact I generated less.
We can see this more clearly if we plot the data as a column (bar) graph and as a histogram. Here's the column graph first.
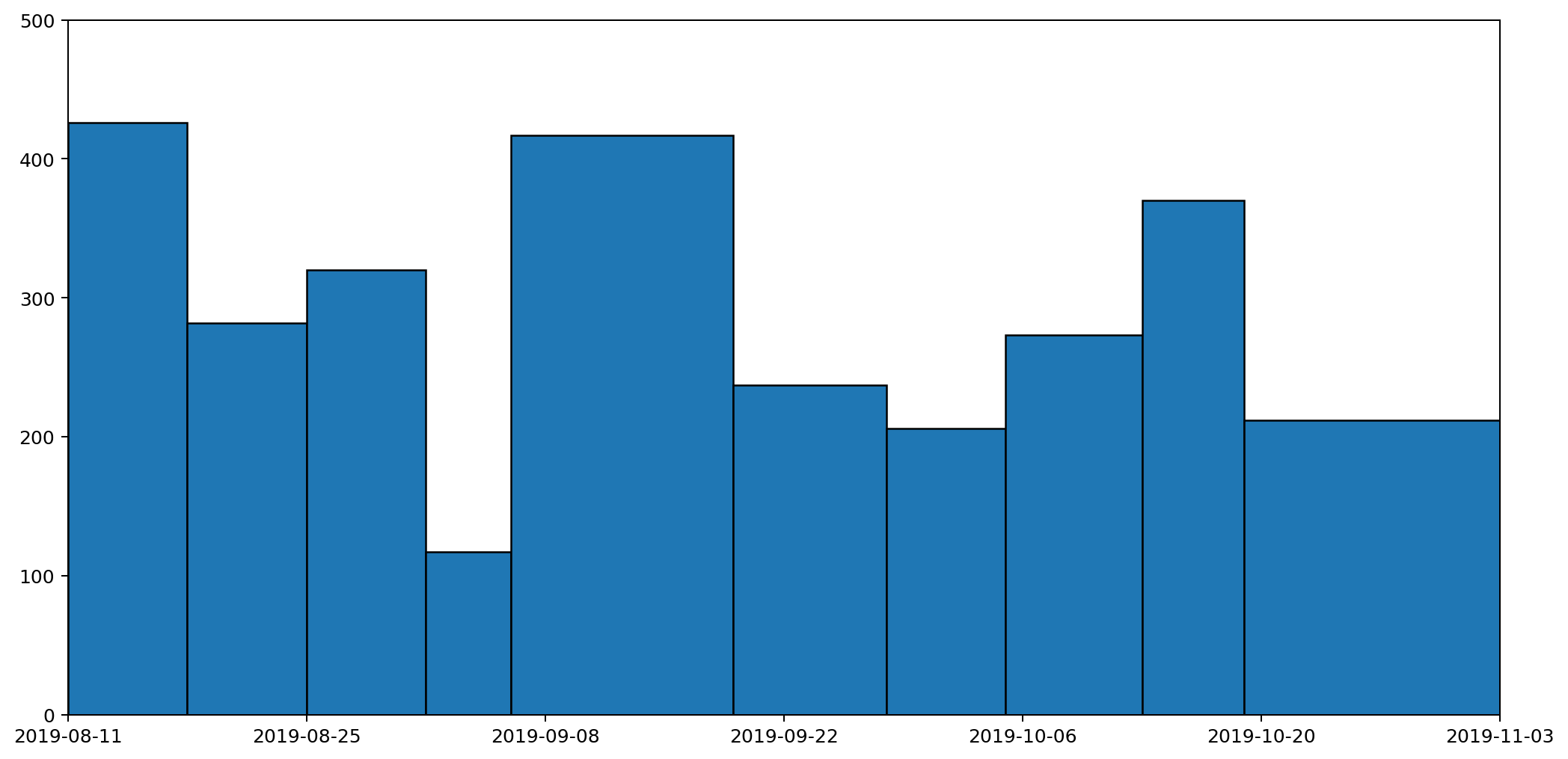
These are the same datapoints as in the previous graph, but drawn as columns with widths proportional to the duration that the readings represent. The column that spreads across from the 6th to the 19th September is the reading we've just been discussing. This is a tall, wide, column because it represents a long period (nearly two weeks) and a heaver than usual weight reading (because it's more than a weeks' worth of rubbish). If we now convert this into a histogram, it'll give us a clearer picture of how much waste was being generated per day.
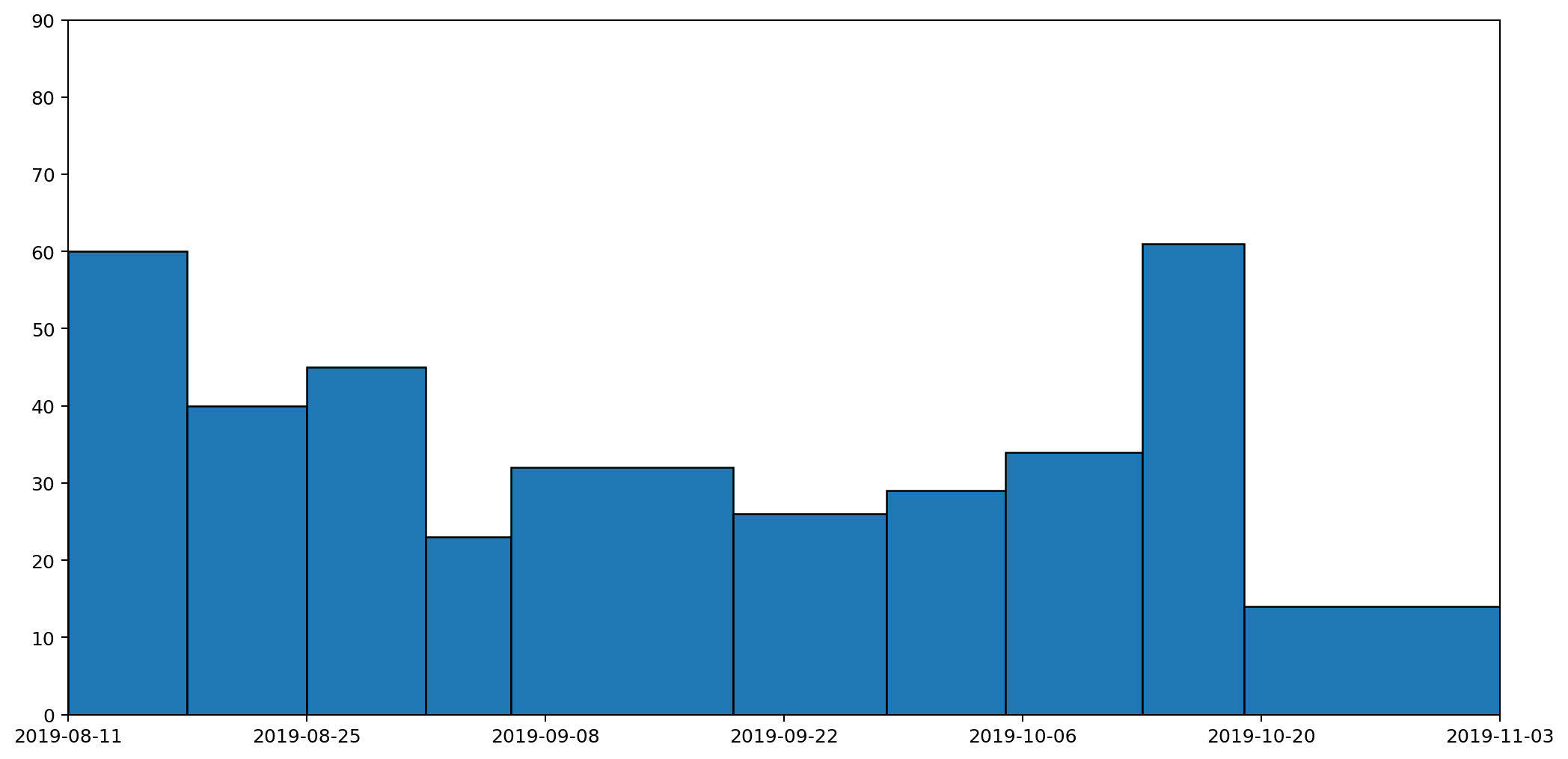
This histogram takes each of the columns and divides it by the number of days the column represents. A histogram has the nice property that the area — rather than the height — of a column represents the value being plotted. In this histogram, the area under all of the columns represents the quantity of waste that I've generated across the entire period: the more blue, the more waste.
Not only is this a much clearer representation, it also completely changes the picture. The original graph made it look like my waste output peaked in the middle. There is a slight rise in the middle, but it's actually just a local maximum. In fact the overall trend was that my daily general waste output was decreasing until the middle of the period, and then rose slightly over time. That's a much more accurate reflection of what actually happened.
It would be possible to render the data as a stacked histogram, and to be honest I'd be happy with that. The overall picture, which ties in with my motivation for wanting the graph in the first place, indicates how much waste I'm generating based on the area under the graph.
But in fact I tend to be generating small bits of rubbish throughout the week, and I'd like to see the trend between readings, so it would be reasonable to draw a line between weeks rather than have them as histogram blocks or columns.
So this leads us down the path of how we might draw a graph that captures these trends, but still also retains the nice property that the area under the graph represents the amount of waste produced.
That's what I'll be exploring in part two.
All of the graphs here were generated using the superb MatPlotLib.