List items
Items from the current list are shown below.
Gecko
12 Dec 2023 : Day 105 #
We're back looking at printing today after about a week of work now. Yesterday we looked at the parent-child structure of the PBrowser interface and came to the conclusion that we should be calling CanonicalBrowsingContext::Print() in the DownloadPDFServer code rather than the nsIWebBrowserPrint::Print() call that's there now. It'd be a good thing to try at least. Our route in to the call is through windowRef which is a Ci.nsIDOMWindow. So the question I want to answer today is: "given a Ci.nsIDOMWindow, how do a find my way to calling something in a CanonicalBrowsingContext object?"
It's a pretty simple question, but as is often the case with object-oriented code, finding a route from one to the other is not always obvious. It's obfuscated by the class hierarchy and child-parent message-passing, and made even more complex by gecko's approach to reflection using nsISupports runtime type discovery.
I'll need to look through this code carefully again.
[...]
I've been poring over the code for some time now and reading around the BrowsingContext documentation, but still not made any breakthrough headway. The one thing I did find was that it's possible to collect the browsing context from the DOM window:
There's also this potentially useful static function for getting the CanonicalBrowsingContext from an ID:
So I'm going to try going down the BrowsingContext.getFromWindow() route. If I'm going to use this I've already got a good idea about where it should go, which is in the DownloadPDFSaver code.
So I've added some debug prints to the DownloadPDFSaver in DownloadCore.jsm to try to figure out if we can extract the BrowsingContext from the windowRef using this method. Here's what I added:
Having added that code and selected the option to safe as PDF, there's now some rather strange and dubious looking output sent to the console. It's the same output that we see when the browser starts:
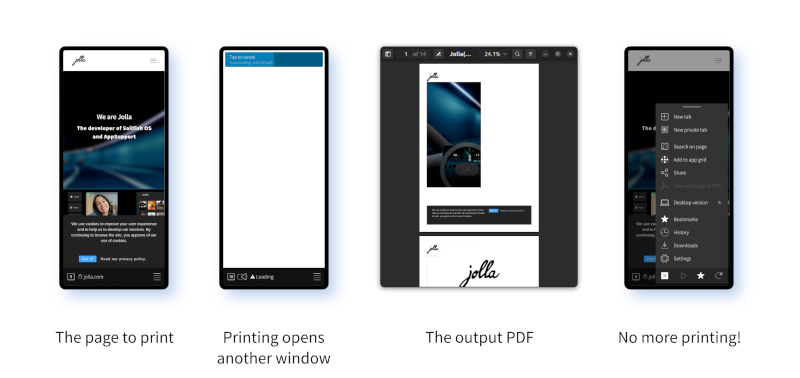
Well as you can see the actual PDF print out is a bit rubbish, but I don't think that's anything I've done: that's just the inherent difficulty of providing decent PDF printouts of dynamic webpages. This is actually exactly the PDF output we need.
I admit I'm pretty happy about this. All that reading of documentation and scattered code seems to have paid off. There is a slight problem though, in that the process seems to open a new window when the printing takes place. That's not ideal and will have to be fixed.
Also, having printed out a page, the "Save web page as PDF" option is now completely greyed out in the user interface. It's not possible to print another page. That feels more like the consequence of a promise not resolving, or some completion message not being received, rather than anything more intrinsic though.
I've done some brief testing of other functionality in the browser. Nothing else seems to be broken and the browser didn't crash. So that's also rather encouraging.
I'm going to call it a night: finish on a high. There's still plenty of work to be done with the PDF printing: prevent the extra window from opening; ensure the option to print is restored once the printing is complete. But those will have to be for tomorrow. The fact saving to PDF is working is a win already.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
It's a pretty simple question, but as is often the case with object-oriented code, finding a route from one to the other is not always obvious. It's obfuscated by the class hierarchy and child-parent message-passing, and made even more complex by gecko's approach to reflection using nsISupports runtime type discovery.
I'll need to look through this code carefully again.
[...]
I've been poring over the code for some time now and reading around the BrowsingContext documentation, but still not made any breakthrough headway. The one thing I did find was that it's possible to collect the browsing context from the DOM window:
browsingContext = BrowsingContext.getFromWindow(domWin);
This was taken from Prompt.jsm which executes some code similar to the above. That's making use of the following static call in the BrowsingContext.h header:
static already_AddRefed<BrowsingContext> GetFromWindow(
WindowProxyHolder& aProxy);
As far as I can tell BrowsingContext isn't pulled into the JavaScript as any sort of prototype or object. It's just there already.There's also this potentially useful static function for getting the CanonicalBrowsingContext from an ID:
static already_AddRefed<CanonicalBrowsingContext> Get(uint64_t aId);Unfortunately I'm not really sure where I'm supposed to get the ID from. It's added into a static hash table and if I had a BrowsingContext already I could get the ID, but without that first, it's not clear where I might extract it from.
So I'm going to try going down the BrowsingContext.getFromWindow() route. If I'm going to use this I've already got a good idea about where it should go, which is in the DownloadPDFSaver code.
So I've added some debug prints to the DownloadPDFSaver in DownloadCore.jsm to try to figure out if we can extract the BrowsingContext from the windowRef using this method. Here's what I added:
dump("PRINT: win: " + win + "\n");
this._webBrowserPrint = win.getInterface(Ci.nsIWebBrowserPrint);
dump("PRINT: webBrowserPrint: " + this._webBrowserPrint + "\n");
this._browsingContext = BrowsingContext.getFromWindow(win)
dump("PRINT: BrowsingContext: " + this._browsingContext + "\n");
I've not changed any of the functional code though, so I'm not expecting this to fix the segfault; this is just to extract some hints. Here's what it outputs to the console when I try running this and selecting the "Save web page as PDF" option:
PRINT: win: [object Window] PRINT: webBrowserPrint: [xpconnect wrapped nsIWebBrowserPrint] PRINT: BrowsingContext: [object CanonicalBrowsingContext] Segmentation fault (core dumped)This is... well it's pretty exciting for me if I'm honest. That last print output suggests that it's successfully extracted some kind of CanonicalBrowsingContext object, which is exactly what we're after. So the next step is to call the print() method on it to see what happens.
Having added that code and selected the option to safe as PDF, there's now some rather strange and dubious looking output sent to the console. It's the same output that we see when the browser starts:
PRINT: win: [object Window] PRINT: webBrowserPrint: [xpconnect wrapped nsIWebBrowserPrint] PRINT: BrowsingContext: [object CanonicalBrowsingContext] JSScript: ContextMenuHandler.js loaded JSScript: SelectionPrototype.js loaded JSScript: SelectionHandler.js loaded JSScript: SelectAsyncHelper.js loaded JSScript: FormAssistant.js loaded JSScript: InputMethodHandler.js loaded EmbedHelper init called Available locales: en-US, fi, ru Frame script: embedhelper.js loaded [...]On the other hand, looking into the downloads folder, there's a new PDF output that looks encouragingly non-empty. I wonder what it will contain?
$ cd Downloads/ $ ls -l total 4624 -rw------- 1 defaultuser defaultuser 0 Dec 7 21:38 'Jolla(10).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 8 23:36 'Jolla(11).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 8 23:47 'Jolla(12).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 10 21:50 'Jolla(13).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 10 21:53 'Jolla(14).pdf' -rw-rw-r-- 1 defaultuser defaultuser 4673253 Dec 10 21:57 'Jolla(15).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 5 22:17 'Jolla(2).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 5 22:17 'Jolla(3).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 6 08:23 'Jolla(4).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 6 08:27 'Jolla(5).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 6 22:32 'Jolla(6).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 6 23:05 'Jolla(7).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 7 19:23 'Jolla(8).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 7 21:24 'Jolla(9).pdf' -rw------- 1 defaultuser defaultuser 0 Dec 5 22:16 Jolla.pdfThat 4673253 byte file that's been output must have something interesting inside it, surely?
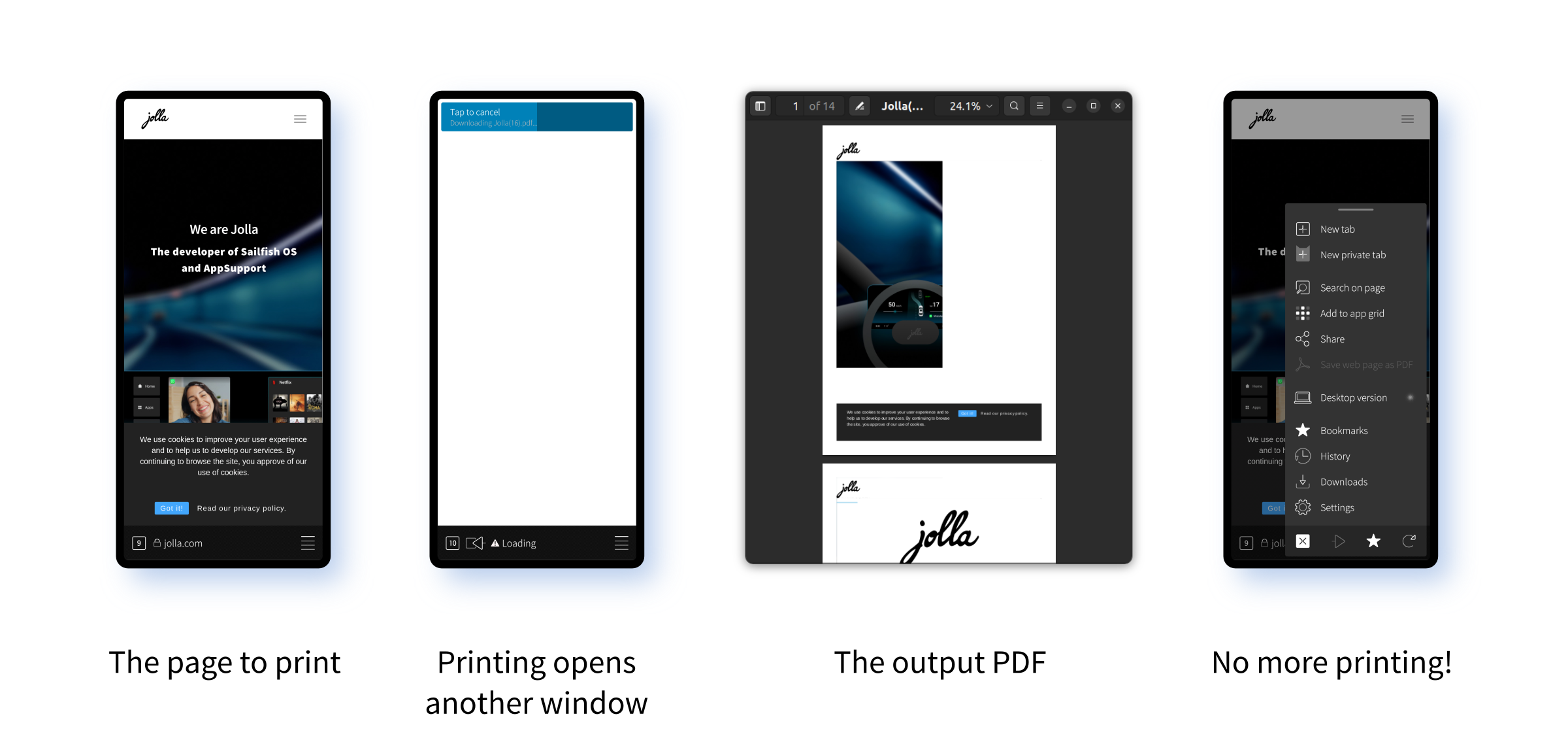
Well as you can see the actual PDF print out is a bit rubbish, but I don't think that's anything I've done: that's just the inherent difficulty of providing decent PDF printouts of dynamic webpages. This is actually exactly the PDF output we need.
I admit I'm pretty happy about this. All that reading of documentation and scattered code seems to have paid off. There is a slight problem though, in that the process seems to open a new window when the printing takes place. That's not ideal and will have to be fixed.
Also, having printed out a page, the "Save web page as PDF" option is now completely greyed out in the user interface. It's not possible to print another page. That feels more like the consequence of a promise not resolving, or some completion message not being received, rather than anything more intrinsic though.
I've done some brief testing of other functionality in the browser. Nothing else seems to be broken and the browser didn't crash. So that's also rather encouraging.
I'm going to call it a night: finish on a high. There's still plenty of work to be done with the PDF printing: prevent the extra window from opening; ensure the option to print is restored once the printing is complete. But those will have to be for tomorrow. The fact saving to PDF is working is a win already.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
Comments
Uncover Disqus comments