Blog
5 most recent items
13 Nov 2024 : Templating in C #
Many years ago — probably some time around 2006 — I was working as a researcher at Liverpool John Moores University and we had an external speaker come to talk to our students about C++ coding.
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
For the methods we have a bunch of constructors and destructors:
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
If you look in the main() method in main.c you'll see an example of its use:
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
Next we define the default constructor and destructor, alongside respective new and delete methods.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?
Comment
It's so long ago that I don't recall the speaker's name, but they presented very convincingly about the benefits of using templates and their extensive and effective use as part of the C++ standard library. Or possibly Boost.
Either way, I recall the focus on templates and how powerful they could be. Although I was familiar with templates, I'd never had them explained to me in quite such a vivid and uncomplicated way.
Still, with this new found clarity I had some doubts. "What do templates give you that you can't already do with C pre-processor macros?" I wondered. As we travelled down in the lift together following the presentation, I remember asking the presenter this same question. They said something about type safety, but the journey in the lift wasn't long enough to go in to detail and I remained unconvinced. As is so often the case, I assumed my confusion must be grounded in a lack of knowledge on my part.
Twenty years later a friend and I were discussing the benefits of C++ over C. We both agree that the lack of destructors in C is one of its biggest omissions, something that it's hard to work around. You can create your own destructor, but how to you get it called automatically when a variable goes out of scope? My friend then suggested that he particularly likes C++ support for vectors.
"I appreciate the simplicity of C++'s vector (for example). You probably can do something similar in C but won't it be more involved to get it working for all types for example?"
There's no doubt, vectors are a nice feature of the C++ standard library. But I felt there was scope to achieve something similar in C. In doing so you might run up against the same lack of support for destructors, but we'd already covered that. Otherwise vectors felt like something a good C library should be able to provide, not something that relies on any intrinsic capability of the language.
I'd always regretted not pursuing my 20-year-old macro-template question to the point of implementation, so I saw my opportunity to try now. What's needed to implement a nice templated vector class in C?
You can see the code we came up with on GitHub. It's not intended as a complete implementation; more a demonstration of what might be possible. It provides two constructs: a vector template and an Example class to test it with. This is C++ so the former isn't actually a template and the latter isn't actually a class. Instead we've used pre-processor macros and conventions based on an object-oriented approach instead respectively.
Throughout the rest of this post I'll talk about them as templates and classes anyway, because conceptually that's what we're aiming for.
Before getting in to how the template is implemented, let's first take a look at the Example class. We can see the struct that collects together the "member variables" and the functions that provide the "methods" alongside one another in the example-class.h file.
Here are the members:
struct _Example {
uint64_t length;
char * string;
};
As you can see the class holds a length to indicate the length of the string and a dynamic array of char instances for the string data. You can imagine that this is a much simplified version of the standard library's string class.For the methods we have a bunch of constructors and destructors:
void Example_construct(Example *data); void Example_construct_init(Example *data, char const * const string); void Example_destruct(Example *data);Similar to C++ we have a default constructor and an "override" that accepts initialisation parameters. It's not an override at all of course because C doesn't support multiple functions using the same name. Instead we just name the two constructors differently, but with the same prefix. Under the hood this is what C++ is doing as well through name mangling, it's just hidden from the programmer.
In practice this will turn out to be fine, because code that wants to automatically call the constructor is likely to want the default constructor anyway.
If you check inside the implementations for these methods you'll notice that the constructors don't allocate memory for the struct and the destructor doesn't free it, they only allocate and free for the member variables. You might reflect that the same is true for constructors and destructors in C++. But this isn't just a case of copying C++, it turns out to be necessary for our implementation, especially for handling objects rather than references.
I think it's interesting to note that, in doing this task, we end up making all the same decisions as were made decades ago for C++. It makes it a useful learning exercise for me.
We'll come back to this later, but it means we can also create some new and delete methods for ourselves. We get these for free in C++:
Example *example_new(); Example *example_new_init(char const * const string); Example *example_delete(Example *data);These two new methods do allocate memory for the object data, before calling the constructor. Contrariwise the delete method calls the destructor and then frees the allocated memory. I've not looked at the C++ source code for creation and deletion, but I imagine it does something similar.
Finally we have a bunch of methods for manipulating the data held be the object. The first is used to populate the string using a given format provided, similar to sprintf(). The latter just dumps out the contents of the string to the console, prefixed by the length. As the name implies, this second method is really only intended for debugging purposes.
void example_sprintf(Example *data, char const * format, ...); void example_debug_print(Example *data);If this were a proper string implementation we'd want a lot more functionality for accessing and manipulating the string. But this simple example is enough for our purposes.
If you look in the main() method in main.c you'll see an example of its use:
Example_construct_init(&example, "Hello World!"); example_debug_print(&example);Now as the name suggestions this is just an example class, but it already demonstrates the foundations of our class-based approach to C. Apart from the new methods every one of our functions accepts a pointer to an Example as its first parameter. This is the equivalent of the class object this in C++. Every class has a constructor and a destructor. Following the same conventions for all other struct implementations will make our C code safer and more robust, and will encourage increased separation between classes.
There are many interesting ways to extend this, including with support for virtual methods and inheritance, all within the constraints of C, but those are topics for another day. If you'd like to see a nice object-oriented set of class implementations in C, I recommend taking a look at the GLib code. The GLib GString implementation is a much more feature-complete version of what we've got here.
This is all well and good, I hear you say, but what does it have to do with C templates? Okay, okay, it has nothing to do with them, but we will get there. Before we do we can make our lives easier by first considering how we might make a bespoke vector class just for use with Example objects.
If we check out an earlier version of the code in the repository we can see an example in the cvector.h and cvector.c files. I put these together so that I could understand what was needed prior to converting it into a template, so I think it'll be helpful to review the files before we move on.
The header shows a similar sort of structure to our Example class. Given what I said above about following similar conventions for all of our "classes" this won't come as a great shock. We start with the structure for holding the member variables:
typedef struct _Vector Vector;Unlike for our Example class in this case we're keeping the actual implementation opaque because we don't have to know its size for use elsewhere.
Next we define the default constructor and destructor, alongside respective new and delete methods.
void vector_construct(Vector *data); Vector *vector_new(); void vector_destruct(Vector * data); Vector *vector_delete(Vector *data);Finally we have a bunch of class methods that are unique to this class and which provide all of the real functionality:
Example vector_get(Vector *data, uint64_t position); void vector_push(Vector *data, Example example); Example vector_pop(Vector *data); uint64_t vector_length(Vector *data); void vector_resize(Vector *data, uint64_t required); void vector_debug_print_space(Vector *data);We have a method for getting items from the vector using random access, a method for pushing items to the end of the vector; a method for popping items from the end of the vector and a method that returns the number of items in the vector. The resize method is for internal use (I shouldn't have included it in the header really) and a debug method for printing out some info about the contents of the vector.
As before, in each case the data parameter can be considered equivalent to this in C++ (or self in other languages).
One important thing to note about these methods is that the Example parameter of vector_push() and the return value of vector_pop() are both values rather than pointers or references. That's intentional, because our vector doesn't just store pointers, we want it to be able to store values as well. That's to reflect the same situation as a C++ vector, which can also store values. Pointers all have the same size (64 bits on a 64 bit machine), so if we store only pointers the stride of the vector is always going to be the same. That's a bit dull. We want to support vectors that handle strides of different lengths, both larger (e.g. structs containing lots of data) and smaller (e.g. chars) than would be typically needed for pointers.
The downside is that calling the vector_push() method will potentially result in a large memory copy. A constant reference would be nice here, but we don't have references in C. If this were a real library I might have gone for a constant pointer as a compromise, but for the sake of this exercise and to keep things less confusing I'm sticking with passing by value.
Let's take a look at the implementation, starting with the all-important data structure.
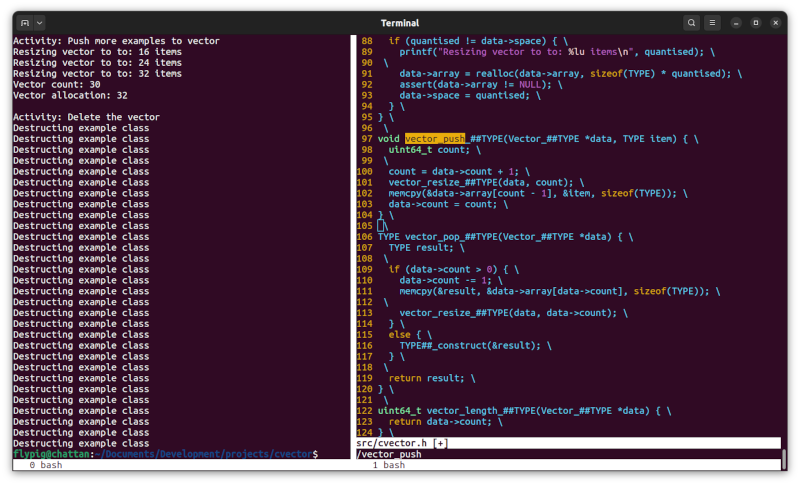
struct _Vector {
uint64_t space;
uint64_t count;
Example *array;
};
Here we store an array of Example elements. We use a pointer rather than an actual array because we want the size to be dynamic, but by giving it the Example type our stride will be sizeof(Example). We also store a count to represent the number of items in the vector and a space value which represents the size of the array.The value of count and space can be different because we may want to allocate more space than we have elements. This will allow us to reallocate memory more judiciously, in our case controlled by the VECTOR_SPACE_STRIDE value. This represents how many items we allocate for at a time. I've set this to be eight, which means that the memory for the array will be allocated eight items at a time. Note that we must always have space ≥ count to avoid memory corruption.
Keeping the size of the array large enough is the job of the vector_resize() method. We pass in the number of items we need the array to accommodate (count) and it resizes the array to ensure it's large enough, potentially reducing its size if this is possible.
I'm going to skip over how vector_resize() works (it's an implementation detail) but it's helpful to see how things are working to some extent, so let's look at the vector_push() method:
void vector_push(Vector *data, Example example) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &example, sizeof(Example));
data->count = count;
}
The purpose of this method is to push an item to the end of the vector. We calculate the new space required, which is just the current space plus one (we're adding a single element to the end). We resize the array using vector_resize() to ensure we have the space for it. Then we copy the value from the passed Example structure into the memory that we now know is now available in the array. Finally we set the count of our array to the new, incremented, value.We're using memcpy to transfer the value. That's important. If this were C++ we might have invoked the class's copy assignment operator here, but this is C and we don't have one.
Actually that's not true. I could very well have created an Example_copy() method, equivalent to a copy assignment. This would make our vector more flexible at the expense of having to implement more methods on our Example structure. I skipped this to avoid complicating the implementation but it would be a very simple addition.
If you look through the full implementation of Vector you'll see that we reference Example as a type quite a few times (I count nine in total). We also reference the following two methods that apply to it explicitly:
- void example_construct(Example *data);
- void example_destruct(Example *data);
- Example *example_copy(Example const *data, Example *other);
They're a pretty minimal set of requirements and align nicely with the default methods we'd normally stick in a C++ class. One of the nice features about our templated version of our C vector is that the code won't compile if these methods aren't defined for our particular type: it'll be a compile-time error rather than a runtime error.
That's true for C++ as well, except that one of the benefits of C++ is that we get default versions of these in case we don't define them ourselves. For our C version we get nothing for free: if we don't define them they won't exist. That's arguably one of the benefits of C over C++: everything is explicit, so you always know what's going on. But obviously the downside is we need to write much more of the implementation ourselves.
Let's take stock. We have an Example class that's like a cut-down version of std::string and we have a Vector class that's like a cut-down version of std::vector. But our vector can only hold Example items; it's intrinsically restricted to supporting this one type.
The next step is to decouple them, which is where the templating comes in.
In order to turn our vector into a template vector class we need to make two changes. First we need to abstract out all of those references to the Example type. Second we have to abstract out the references to example_construct() and example_destruct().
The first change is the easier of the two. We're going to replace every use of Example in our vector code with a TYPE placeholder. Then we're going to allow TYPE to be changed at compile-time by making all of our code a pre-processor macro.
So this is what our struct becomes:
typedef struct _Vector {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector;
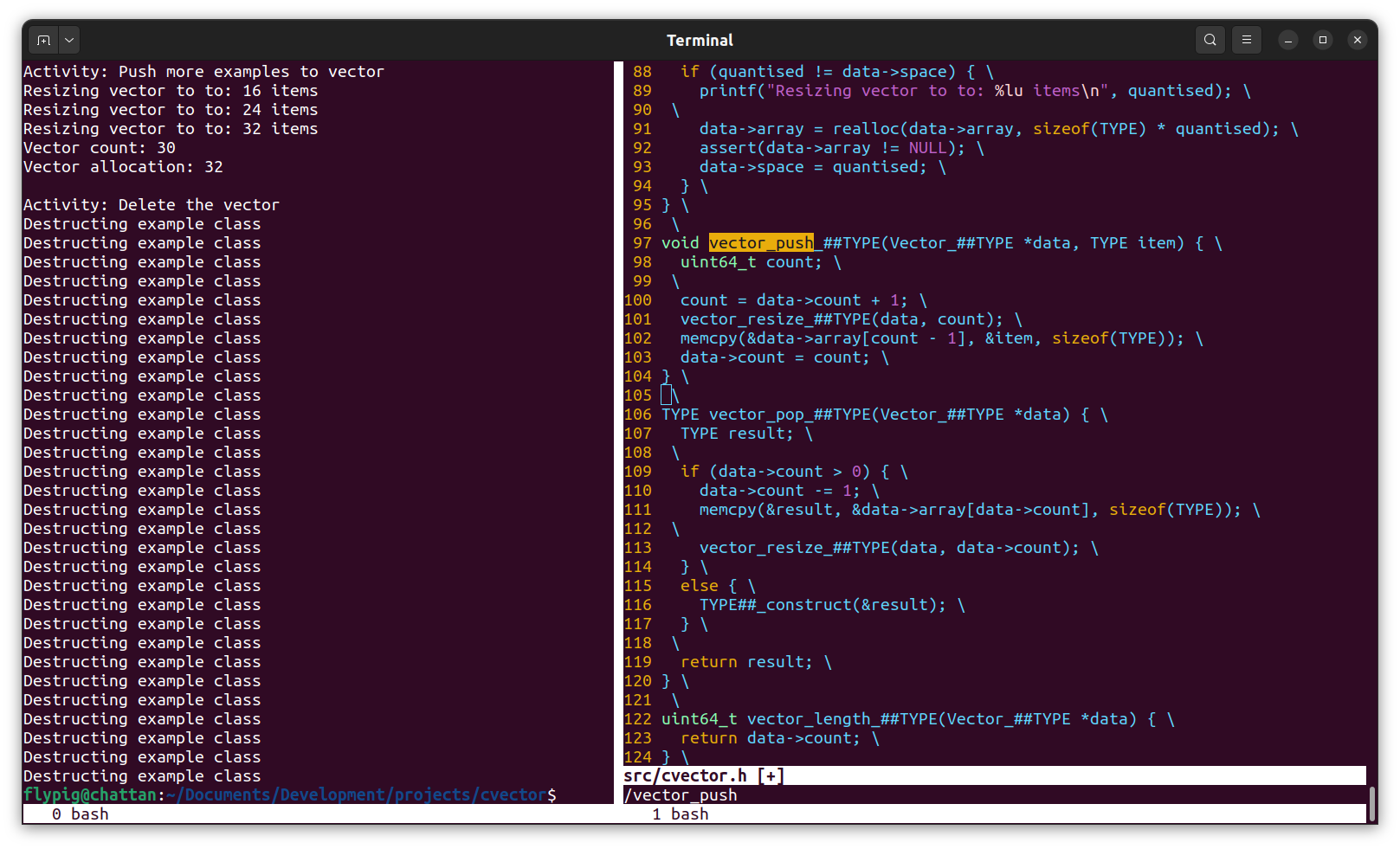
By way of example for the methods, this is what our vector_push() becomes:
void vector_push(Vector *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
Eventually we'll put these into a macro and we'll need to generate different versions for every TYPE we want to use. But let's not get ahead of ourselves just yet.In C we can't override functions, so we're going to have to give each of our structures and functions a name that's unique to the type. To do this we're going to use some more macro magic, by concatenating the TYPE placeholder with each of the names, like so:
typedef struct _Vector_##TYPE {
uint64_t space;
uint64_t count;
TYPE *array;
} Vector_##TYPE;
Now our vector implementation for the Example type will use a struct called Vector_Example rather than just Vector. We can do the same thing for our methods as well, like this:
void vector_push_##TYPE(Vector_##TYPE *data, TYPE item) {
uint64_t count;
count = data->count + 1;
vector_resize_##TYPE(data, count);
memcpy(&data->array[count - 1], &item, sizeof(TYPE));
data->count = count;
}
So now our vector_push() method will actually take the name vector_push_Example(). If we were to create a vector that consumes a different type, say a Blob type, the names would become Vector_Blob and vector_push_Blog() respectively.We don't want to have to remember to perform this name mangling ourselves every time, so we also create some pre-processor macros for the function names as well, like this:
#define vector_push(TYPE) vector_push_##TYPENow, if we want to call the vector_push() method that we've defined for the Example type, we can call it like this:
vector_push(Example)(vector, example);The code with Example surrounded by parenthesis can be considered like the angle-bracket equivalent for templates in C++:
vector_push<Example>(vector, example);We just have to use parentheses rather than angle brackets because C has no concept of the angle brackets as used for templates. The compiler would think they were inequalities.
Next we have to deal with the constructor and destructor calls. For example, when we call the destructor on our vector it's going to call the destructor on all of the items it's holding, like this:
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
example_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
We need to fix the call to example_destruct() in the middle of that code so that it calls the destructor for the specific type held by the vector. We can do it like this:
void vector_destruct_##TYPE(Vector_##TYPE * data) {
uint64_t pos;
if (data->array) {
for (pos = 0; pos < data->count; ++pos) {
TYPE##_destruct(&data->array[pos]);
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
So now, in the case of our vector holding Example objects this will now call Example_destruct() whereas for our vector holding Blob objects, this will call Blob_destruct(). Great!The C pre-processor isn't powerful enough to manipulate parameters into lowercase, so in order to support this change, we have to capitalise the constructor and destructor methods for our Example class as well:
void Example_construct(Example *data); void Example_destruct(Example *data);It's a bit ugly like this in my opinion, but pragmatically it's the right thing to do. For example, it ensures we can to support structs that share the same name apart from their capitalisation, just as we should.
Finally we need to actually wrap all of these changes up into a macro. That means we have to name the macro and add a backslash to the end of each line of our implementation. We end up with something that looks horrific, but is otherwise pretty clear and works as we expect:
#define VECTOR_TEMPLATE(TYPE) \
typedef struct _Vector_##TYPE { \
uint64_t space; \
uint64_t count; \
\
TYPE *array; \
} Vector_##TYPE; \
[...]
With all this in place, the only thing we now need to do is add a call to this macro at the top of our code to define the actual vector classes we want to use:
VECTOR_TEMPLATE(Example) VECTOR_TEMPLATE(Blob) [...]And that's it! We now have a fully type-safe templated vector class written in C that doesn't require any C++ magic.
The nice thing about this is that it really is very similar to the C++ implementation. For example, as with C++ templates, all of the implementation code is now in the header file and only gets compiled in the place where the macro is instantiated. Similar to a C++ template, entirely new code is generated for every template instance that's defined. And if one of the classes we use in our template is missing a constructor or destructor method, the code will refuse to compile. No messy runtime failures due to a missing implementation.
C++ has become a wild and wonderful language, while C has remained astonishingly stable. Despite this it seems the ties between C and C++ remain surprisingly strong.
We didn't go through all of the code here, but I did try to include examples to cover all of the relevant aspects. Do check out the full C template implementation in the repository. Here's the result of running the code:
If we can implement templates in C, the obvious follow-on question is why we need templates in C++ at all. After all, pre-processor macros are available in C++ as well.
Well, although using pre-processor macros this way allows us to get something remarkably close to C++ templates, there remain significant limitations.
The most obvious one is that writing the code is much harder with the C version. Using string concatenation works, but you have to be quite careful to get the code correct, for example with all of the function renaming. This is still needed with C++ templates, the difference is that the compiler does it all for you automatically when it mangles the function names.
Perhaps more importantly, templates are type-aware. That means that you can have template functionality that's dependent on type, using C++ traits, like this:
#include <type_traits>
template <typename TYPE>
void vector_destruct(Vector * data) {
uint64_t pos;
if (data->array) {
if constexpr (std::is_object_v<TYPE>) {
for (pos = 0; pos < data->count; ++pos) {
destruct(&data->array[pos]);
}
}
free(data->array);
data->array = NULL;
}
data->space = 0;
data->count = 0;
}
Sadly the C pre-processor simply isn't sophisticated enough to do anything like this. This also hints at other issues that we might experience with our C implementation. For example, everything works fine for vanilla types, but if we try to use pointers, or const pointers, or any datatype with a composite name, we're going to run in to trouble. There's a solution, which is to make a typedef and use that instead, but it's an extra layer of abstraction and work. Likewise, if we want to use a datatype that has no constructor or destructor (for example if it's a fundamental type) then we'll have to define an empty constructor and an empty destructor in order to allow the code to compile. We can set these as being inline so that the compiler can optimise them away, but again, it's extra work.Using macros in place of templates this way isn't intended to be a serious tool. It might be useful under certain circumstances, but if you find yourself regularly using these kinds of constructs, it might be an indication that it's time to switch to C++. But thinking about how to implement templates in C can be a useful exercise in better understanding the underlying mechanisms of C++. At least, I certainly feel I've improved my understanding as a result.
Now that we have templates the next step is to automate all this using a tool to pre-process our source files. Perhaps our tool could also allow the developer to use angle brackets Vector>Example< instead of Vector(Example) parentheses? I can see this becoming really successful! I just have this nagging feeling... didn't someone already implemented something like this?
6 Oct 2024 : Reviewing My Browser History #
For many years I thought it would be a mistake to mix my hobbies with my professional life. Blurring the boundary would prevent me defining a clear boundary between my work time and my relaxation time. I thought it could also lead to things I enjoy becoming contaminated, irreversibly harming the joy I get from them. It's not that I didn't want to enjoy my work: quite the opposite in fact. I felt in order to enjoy both I needed to maintain a separation.
As my life has progressed I've changed my opinion on this. It's great to separate work and play, but there's also immense joy to be had from doing something you love as a professional endeavour. Mixing the two together has the potential to amplify the joy from both.
Working for Jolla was what really brought this home to me. Smartphone development, user privacy and control, and Sailfish OS in particular were always part of the life I separated from my career. When I started working at Jolla I thought I was taking a risk. Would I lose my passion? Would I regret knowing what goes on inside the "sausage factory"?
My concerns were unfounded and, with this experience in hand, I now make it my aim to bring my personal passions into my professional life as well.
Now I'm at the Turing I'm no longer developing for Sailfish OS during work hours. As readers of my gecko dev diaries will know, upgrading the Sailfish browser has been one of my main activities outside of work. Finding opportunities to bring this Sailfish development into my professional world has been one of my objectives and recently just such an opportunity arose.
It's only a small overlap: in November I'll be giving a presentation about browsers at the Turing. The title of the talk will be "The Anatomy of a Browser: Embedded Mobile Lizards". Lizards being a reference to Gecko.
To help with this I've been digging a little into the history of browsers. They have a rich, fascinating and often fractious history that I find fascinating and one I want to talk a little more about today.
But to understand the history, we first need to understand a little about the internals of a browser.

The protocol client handles network interactions. It opens a network connection, sends a message to the server, then waits for and interprets the response. If the protocol uses a secure transport layer it handles certificate validation, checking certificate revocation, data encryption and integrity. The latest releases of Firefox and Chrome support HTTP, HTTPS, WebSockets, Secure WebSockets, Secure Real-time Transport Protocol, file access and probably others I'm not aware of. Firefox and Chrome used to support FTP but have since dropped it. Firefox dropped support in version 90 (July 2021) while Chrome dropped it in version 95 (September 2021). Unlike the rendering and JavaScript engines, protocol clients tend not to be given their own bespoke names separate from the browser. Maybe this is because they're often built from other libraries offering support for specific protocols. Nevertheless the protocol client is both a crucial and complex part of the browser.
I've listed the DOM as a separate piece of the browser, but it's usually tightly coupled with the layout and rendering engines. The DOM defines the internal data structures used to represent the page being rendered. For HTML, XML or SVG documents these are hierarchically built from nodes that have a parent and multiple (possibly zero) children. Typically the document structure will map naturally onto the DOM, with XML elements and attributes mapping onto nodes. Child nodes in the document will map to child nodes in the DOM. In practice nodes are likely to be represented as class objects in the code containing references to child nodes. The DOM is usually part of the rendering engine separate from the JavaScript engine, but if it weren't for JavaScript the DOM might be considered as just an implementation details. The existence of JavaScript elevates the DOM to something Web developers have to have a good understanding of, as we'll see.
The JavaScript engine allows execution of JavaScript code. JavaScript has an odd history. Originally invented at Netscape by Brendan Eich, you might think that the JavaScript language has something to do with Java. In fact they're very different. Java is a strictly-typed object-oriented garbage-collected language that compiles down to a bytecode representation that can be executed by a Java Virtual Machine. Although at one point Java "applets" that ran in the browser were a thing, you rarely see these nowadays (they're not supported without installing a plugin). Java is still used in server applications and to be honest, given Sun's expertise and revenue rested primarily with servers I always found it rather surprising that it was ever anything other than server-focused. JavaScript on the other hand is very much a client-side, dynamically-typed event-based scripting language with prototype-based object orientation. In recent years it's also become popular as a server-side language for reasons that I won't go in to here. Both Java and JavaScript are "curly-brace" languages with similarities to C++; and while I realise I've managed to make them sound quite similar, they're actually totally different. The only reason they share a name is that in a bit to ride the wave of Java's popularity, Netscape signed a licensing agreement with Sun to use the name. Marketing genius or ontological vandalism? You decide.
Another key difference between JavaScript and Java is that the DOM is a first-class entity in JavaScript. Although they live in different parts of the browser, the development of the DOM is tightly intertwined with that of the language. When first released by Netscape JavaScript could interact with only certain elements of the page, most notably form elements. The name now given to the set of elements exposed at that time is DOM Level 0. Access to the full document didn't come until DOM Level 1. While JavaScript is a perfectly good language even without the DOM, in a browser context the two are tightly coupled.
Although JavaScript refers to and can modify the DOM, the DOM implementation is part of the layout and rendering engine. When we refer to browser engines (WebKit, Gecko, Blink,...) we're usually referring to this layout/render engine portion of the browser. The layout engine takes the document, structured using the DOM, and lays it out as elements on the page in the way they'll be viewed by the user. This allows the browser to build up the equivalent of a scene graph which is then rendered by the rendering engine to some sort of canvas (the screen or an offscreen buffer). This rendering usually uses an appropriate render backend, for example on the Sailfish Browser it calls a serious of GLES commands. The layout engine follows a strict set of rules for positioning elements on the page. The HTML/CSS box model is used for rendering most items, but there are exceptions. For example SVG has its own rendering model which Gecko also supports as part of the same DOM hierarchy.
HTML and SVG documents embed or reference large numbers of other file types, which the browser has to support as well. These multimedia files include images, audio, animations and video. Historically browser support for different multimedia elements has been a mess, often delegated to some other operating system component (e.g. Windows Media Player, ffmpeg, gstreamer). Each file type will have its own decoder and there may be Digital Rights Management involved as well (e.g. Widevine). In practice browsers tend to separate raster and vector images from video and audio. The former have been tightly integrated into HTML for decades whereas the latter two only became standardised in HTML 5 with the introduction of the audio and video tags. These allow audio and video to be embedded with customisable controls.
Finally we have the user interface, which is the bit that we most associate with the browser. This is a little ironic given I'd argue the depth, complexity and maintenance burden is weighted towards the other layers. But most people aren't really concerned with the rendering or JavaScript engine, they care about whether a particular user interface feature is supported or not.
And to be fair, the user interface doesn't just display an address bar. It also has to provide tabs, JavaScript pop-ups, permissions dialogues, Settings controls, password management functionality, bookmarks, history management and a whole lot more.
In the embedded browser space the user interface is intentionally minimal. The idea is that the browser gets embedded into some other application which provides the user interface elements needed over and above those provided by the rendered Web page itself. On Sailfish OS this minimal interface is provided by the WebView. The additional capabilities are managed through the WebView's Application Programming Interface. On Sailfish OS there's also a Qt-based user interface to the browser, which brings its own complexity. For simplicity I've grouped together the user interface of the browser and the application programming interface of the embeddable WebView in the "Interface" section in the diagram.
During my time upgrading the Sailfish Browser from ESR 78 to ESR 91 I routinely referred to it as a Gecko upgrade. The name Gecko covers the DOM, layout engine and rendering engine but typically doesn't include the JavaScript engine or user interface. The user interface is typically referred to by the name of the browser itself. For example Firefox uses the Gecko rendering engine, the SpiderMonkey JavaScript engine and the Firefox user interface. For Safari it's WebKit, Nitro and Safari. For Chrome it's Blink, V8 and Chrome. And so on.
Now that we've broken down the different parts of the browser we're equipped to delve into the history of Web browsers in more detail.
Right at the start the history is a bit messy. The WorldWideWeb browser was the graphical HTML browser (and editor) written by Tim-Berners Lee in Objective-C to run on NeXTSTEP. The first version was completed at the end of 1990 with the browser being later renamed to Nexus. The code was re-written in C by Tim and Jean-François and turned into the Libwww library to become the very first browser engine. This was then used by Nicola Pellow at CERN to write the Line Mode Browser which was text-based, usable over telnet and released in 1991.

This was not just the birth of the Web, but also the genesis of structures that now define what it means to be a Web browser. These same structures can be seen in how browsers are built today.
Libwww and the Line Mode Browser that were created from it continued to be developed right up until 2017. Although the library is written in C it applies an object-oriented approach. Structures have constructors and destructors with the me context variable often used in places where you might find this or self in an object-oriented language. Reading this code in the early noughties had a profound influence on me, shaping my own style of C coding to this day.
More notably it was also used by the Amaya lightweight Web editor developed at INRIA and the Mosaic Browser developed at the NCSA. The Mosaic browser was popular in its day and the NCSA spun out a commercial entity in the form of Spyglass Mosaic which built on the NCSA Mosaic code. The company was set up to licence the browser to other companies.
The licensing agreement struck with Spyglass required Microsoft to pay a small monthly fee with additionally a portion of all non-Windoww revenue from the browser going to Spyglass.
As anyone who experienced the browser wars at that time will know, Microsoft proceeded to give Internet Explorer away for free with Windows. This ultimately earned them a lawsuit from Spyglass (settled out of court for $8 million) and an antitrust lawsuit from the US Government (eventually resulting in Microsoft having to change its approach to interoperability).
Internet Explorer remained as a core component of Windows until Windows 10, after which the company finally switched to offering Edge as the default browser. While Edge is built on Google's Blink engine, even that wasn't enough to dislodge Trident entirely. It remains to this day as the rendering engine powering Edge's compatibility mode. While it's not clear whether any of the original code can still be found in Edge (seems unlikely), a thirty-five year legacy is pretty good going.
Running up to 2000 Netscape completely re-wrote their browser engine. The result was what we now know as Gecko and which powers both Firefox and the Sailfish Browser. The purpose of the re-write was ostensibly to improve standards compliance and maintainability. But the highly abstracted code — arguably what has allowed the renderer to remain relevant to this day — resulted in poor performance. Netscape Navigator was a large programme, incorporating not just a browser but also a full email client and Website editor. In an attempt to improve performance in 2002 the components were split up to form Firefox as a stand-alone Web browser and Thunderbird as a stand-alone email client. My recollection is that this was controversial at the time and didn't improve performance a great deal. But the separation stuck. Splitting email from Web and dropping editing entirely seems to have resonated with users.
Gecko, in the form of Firefox, has experienced ups and downs. Browser statistics are notoriously subjective, but Statscounter registers Firefox market share as having dropped to just over 3% as of January 2024, having peaked in January 2010 at just over 30%.
There's plenty more to say about Gecko's history, not least in relation to its use as an embeddable component, but let's put that aside for today and I'll return to it in a future post.
Gecko remains relevant today as the most popular alternative to the WebKit/Blink family of browsers. While technically open source, both WebKit and Blink are directed by large corporations with few concessions to open source development methodologies. Mozilla on the other hand is a not-for-profit foundation that embraces the spirit of open source as well as the letter. For many, Gecko is an important bulwark against a corporate-controlled browser monoculture.
An interesting twist in Gecko's development comes from its adoption of the Rust language. Developed by Mozilla employee Graydon Hoare and officially adopted by Mozilla in 2009, Mozilla has been gradually moving Gecko's internal components from C++ to Rust.
This led to the development of the Servo engine, written wholly in Rust as a Mozilla research project. While never intended to replace Gecko, elements of the Servo engine were integrated back into the Gecko's WebRender rendering engine.
Servo is currently available as an engine with an intentionally bare-bones user interface. Mozilla divested itself of Servo in 2020, but development continues with the aim of specifying a WebView API during 2024 for use as an embeddable engine.
Through much of its life Opera forged its own path. It was the first mainstream browser to introduce tabs. It integrated a (very good) email client long after Mozilla had disentangled Firefox and Thunderbird from Netscape Navigator. It even integrated its own Web server at one point. Opera also made a point of sticking to W3C standards while other browsers were still trying to lock users in to a proprietary Web.
Perhaps it's for this reason that there was much disappointment when Opera switched to using Blink and V8 in 2013, soon after Google and announced it would fork WebKit. To find out how it got to this point we'll need to go back a bit again and look at the evolution of WebKit.
Initially part of the KDE project, WebKit provided the engine for Konquerer, the default browser for the KDE desktop environment. At that point the engine was referred to by the name KHTML, alongside the KJS JavaScript engine. It was picked up by Apple in 2001, apparently because of its small code footprint. Apple renamed KHTML and KJS to WebCore and JavaScriptCore respectively with the WebKit project encompassing both.
Contributions to WebKit came from both Apple and the KDE project, as well as from the Qt Project which offered the QtWebKit embeddable widget. Sailfish OS supported use of QtWebKit up until its deprecation in Sailfish OS 4.4 and removal in 4.5, the functionality being replaced by the Gecko WebView API.
In 2008 Google introduced its own Chrome browser also built on WebKit but using the new and Google-developed V8 JavaScript engine. Google's advertising for it emphasise speed (start times and JavaScript execution in particular). Chrome also had an — at the time — unusual sandboxing model with each tab executed as a separate process. This meant that crashes triggered by WebKit or V8 would only bring down a single tab, leaving other tabs and the browser intact.
Although built using many open source components, Chrome itself is made available under a proprietary licence. The Chromium project, also developed by Google, is a fully open source implementation of Chrome, but with the proprietary components removed.
From the outset Google had to make changes to WebKit to support its use in Chrome. Still it took another five years before Google officially forked WebKit in 2013, creating the Blink browser engine. Consequently Chrome now uses both its own renderer and JavaScript combination: Blink and V8.
One of the attractive features of the Blink engine, also particularly relevant to Sailfish OS, is its embedding API which allows it to be used separately from Chrome (or Chromium) and embedded in independent applications. A common example of this usage can be found in the Electron framework, which uses Blink for rendering.
This embeddable design, which neatly separates the chrome from the engine, also makes Blink attractive for use by other browser developers. As noted earlier, Opera switched from Presto and Caraken to Blink and V8 for rendering and JavaScript respectively. Microsoft similarly chose Blink and V8 as the basis for its Edge browser in 2019.
Qt introduced the Qt WebEngine component, wrapping Blink and V8 to offer an embeddable browser, around the release of Qt 5.2 in 2013. This was intended to replace QtWebKit, which was ultimately removed in Qt 5.6. The closest KDE has to a default browser is Falkon, which uses the Qt WebEngine. This therefore completed a strange cycle, with KHTML having been started as part of KDE, forked by Apple, forked again by Google and then integrated back in to KDE via Qt.
Recently the main Serenity OS developer, Andreas King, refocused his attention from the operating system to the Ladybird browser. Ladybird is built using the LibWeb and LibJS browser components of Serenity OS, but which he now develops independently. This arguably represents the first new engine to be introduced with the aim of being a fully-fledged browser for over twenty years, making for a particularly interesting development.
The first version of NetSurf was released in 2002. At that time it was developed exclusively for use on RISC OS, the operating system that powered the Acorn Archimedes (the first publicly available computer to use an ARM processor).
RISC OS is very different from most other operating systems available today. It makes no attempt to be Unix-like and has its own distinctive and cooperatively multitasking desktop environment. This heritage means that the browser is incredibly lightweight, with good CSS support but without viable JavaScript.
During the early days of development JavaScript support was considered out-of-scope for the browser. The reason for this is interesting: it wasn't for lack of a usable JavaScript interpreter, but because the browser lacked a standards-compliant DOM. It turns out JavaScript isn't especially useful without a standards-compliant way to access the elements of a Web page.
Despite the lack of JavaScript support NetSurf still managed to find a niche as a fast and lightweight browser, growing beyond RISC OS. As of today there are downloadable packages available for RISC OS, GTK (Linux), Haiku, AmigoOS, Atari and experimentally for Windows.
Even the question of what a browser is, presented in anything other than the most abstract terms, is likely to suffer exceptions.
What is clear is that browsers have become deeply integrated into our lives. Whether using a computer or smartphone, access to a browser has become a necessity. Over time they've continued to become more capable and more technically complex. Combined with their convoluted history, that makes them fascinating objects of study.
Comment
As my life has progressed I've changed my opinion on this. It's great to separate work and play, but there's also immense joy to be had from doing something you love as a professional endeavour. Mixing the two together has the potential to amplify the joy from both.
Working for Jolla was what really brought this home to me. Smartphone development, user privacy and control, and Sailfish OS in particular were always part of the life I separated from my career. When I started working at Jolla I thought I was taking a risk. Would I lose my passion? Would I regret knowing what goes on inside the "sausage factory"?
My concerns were unfounded and, with this experience in hand, I now make it my aim to bring my personal passions into my professional life as well.
Now I'm at the Turing I'm no longer developing for Sailfish OS during work hours. As readers of my gecko dev diaries will know, upgrading the Sailfish browser has been one of my main activities outside of work. Finding opportunities to bring this Sailfish development into my professional world has been one of my objectives and recently just such an opportunity arose.
It's only a small overlap: in November I'll be giving a presentation about browsers at the Turing. The title of the talk will be "The Anatomy of a Browser: Embedded Mobile Lizards". Lizards being a reference to Gecko.
To help with this I've been digging a little into the history of browsers. They have a rich, fascinating and often fractious history that I find fascinating and one I want to talk a little more about today.
But to understand the history, we first need to understand a little about the internals of a browser.
Browser Internals
What are the various pieces that make up a browser? Broadly speaking we can see it as being made up of five parts:- Protocol client (HTTP/S, WS/S, file, FTP,...).
- JavaScript engine.
- DOM - Document Object Model.
- Layout/rendering engine (HTML, CSS, SVG).
- Media encoder/decoder (JPEG, PNG, audio, video,...).
- User interface.
The protocol client handles network interactions. It opens a network connection, sends a message to the server, then waits for and interprets the response. If the protocol uses a secure transport layer it handles certificate validation, checking certificate revocation, data encryption and integrity. The latest releases of Firefox and Chrome support HTTP, HTTPS, WebSockets, Secure WebSockets, Secure Real-time Transport Protocol, file access and probably others I'm not aware of. Firefox and Chrome used to support FTP but have since dropped it. Firefox dropped support in version 90 (July 2021) while Chrome dropped it in version 95 (September 2021). Unlike the rendering and JavaScript engines, protocol clients tend not to be given their own bespoke names separate from the browser. Maybe this is because they're often built from other libraries offering support for specific protocols. Nevertheless the protocol client is both a crucial and complex part of the browser.
I've listed the DOM as a separate piece of the browser, but it's usually tightly coupled with the layout and rendering engines. The DOM defines the internal data structures used to represent the page being rendered. For HTML, XML or SVG documents these are hierarchically built from nodes that have a parent and multiple (possibly zero) children. Typically the document structure will map naturally onto the DOM, with XML elements and attributes mapping onto nodes. Child nodes in the document will map to child nodes in the DOM. In practice nodes are likely to be represented as class objects in the code containing references to child nodes. The DOM is usually part of the rendering engine separate from the JavaScript engine, but if it weren't for JavaScript the DOM might be considered as just an implementation details. The existence of JavaScript elevates the DOM to something Web developers have to have a good understanding of, as we'll see.
The JavaScript engine allows execution of JavaScript code. JavaScript has an odd history. Originally invented at Netscape by Brendan Eich, you might think that the JavaScript language has something to do with Java. In fact they're very different. Java is a strictly-typed object-oriented garbage-collected language that compiles down to a bytecode representation that can be executed by a Java Virtual Machine. Although at one point Java "applets" that ran in the browser were a thing, you rarely see these nowadays (they're not supported without installing a plugin). Java is still used in server applications and to be honest, given Sun's expertise and revenue rested primarily with servers I always found it rather surprising that it was ever anything other than server-focused. JavaScript on the other hand is very much a client-side, dynamically-typed event-based scripting language with prototype-based object orientation. In recent years it's also become popular as a server-side language for reasons that I won't go in to here. Both Java and JavaScript are "curly-brace" languages with similarities to C++; and while I realise I've managed to make them sound quite similar, they're actually totally different. The only reason they share a name is that in a bit to ride the wave of Java's popularity, Netscape signed a licensing agreement with Sun to use the name. Marketing genius or ontological vandalism? You decide.
Another key difference between JavaScript and Java is that the DOM is a first-class entity in JavaScript. Although they live in different parts of the browser, the development of the DOM is tightly intertwined with that of the language. When first released by Netscape JavaScript could interact with only certain elements of the page, most notably form elements. The name now given to the set of elements exposed at that time is DOM Level 0. Access to the full document didn't come until DOM Level 1. While JavaScript is a perfectly good language even without the DOM, in a browser context the two are tightly coupled.
Although JavaScript refers to and can modify the DOM, the DOM implementation is part of the layout and rendering engine. When we refer to browser engines (WebKit, Gecko, Blink,...) we're usually referring to this layout/render engine portion of the browser. The layout engine takes the document, structured using the DOM, and lays it out as elements on the page in the way they'll be viewed by the user. This allows the browser to build up the equivalent of a scene graph which is then rendered by the rendering engine to some sort of canvas (the screen or an offscreen buffer). This rendering usually uses an appropriate render backend, for example on the Sailfish Browser it calls a serious of GLES commands. The layout engine follows a strict set of rules for positioning elements on the page. The HTML/CSS box model is used for rendering most items, but there are exceptions. For example SVG has its own rendering model which Gecko also supports as part of the same DOM hierarchy.
HTML and SVG documents embed or reference large numbers of other file types, which the browser has to support as well. These multimedia files include images, audio, animations and video. Historically browser support for different multimedia elements has been a mess, often delegated to some other operating system component (e.g. Windows Media Player, ffmpeg, gstreamer). Each file type will have its own decoder and there may be Digital Rights Management involved as well (e.g. Widevine). In practice browsers tend to separate raster and vector images from video and audio. The former have been tightly integrated into HTML for decades whereas the latter two only became standardised in HTML 5 with the introduction of the audio and video tags. These allow audio and video to be embedded with customisable controls.
Finally we have the user interface, which is the bit that we most associate with the browser. This is a little ironic given I'd argue the depth, complexity and maintenance burden is weighted towards the other layers. But most people aren't really concerned with the rendering or JavaScript engine, they care about whether a particular user interface feature is supported or not.
And to be fair, the user interface doesn't just display an address bar. It also has to provide tabs, JavaScript pop-ups, permissions dialogues, Settings controls, password management functionality, bookmarks, history management and a whole lot more.
In the embedded browser space the user interface is intentionally minimal. The idea is that the browser gets embedded into some other application which provides the user interface elements needed over and above those provided by the rendered Web page itself. On Sailfish OS this minimal interface is provided by the WebView. The additional capabilities are managed through the WebView's Application Programming Interface. On Sailfish OS there's also a Qt-based user interface to the browser, which brings its own complexity. For simplicity I've grouped together the user interface of the browser and the application programming interface of the embeddable WebView in the "Interface" section in the diagram.
During my time upgrading the Sailfish Browser from ESR 78 to ESR 91 I routinely referred to it as a Gecko upgrade. The name Gecko covers the DOM, layout engine and rendering engine but typically doesn't include the JavaScript engine or user interface. The user interface is typically referred to by the name of the browser itself. For example Firefox uses the Gecko rendering engine, the SpiderMonkey JavaScript engine and the Firefox user interface. For Safari it's WebKit, Nitro and Safari. For Chrome it's Blink, V8 and Chrome. And so on.
Now that we've broken down the different parts of the browser we're equipped to delve into the history of Web browsers in more detail.
Libwww
We're going to start our history in 1990 when Tim-Berners Lee and Jean-François Groff, both working at CERN, created the HTTP protocol and HTML language that still define the Web today. It fascinates me that Tim-Berners Lee is so well-known as the inventor of the Web, but pioneers like Jean-François Groff and Nicola Pellow, who were there at the beginning, are scarcely recorded. But the Computer History Museum has documented a fascinating interview with Jean-François in which he gives am explanation of the very first Web engine.my main task during my days at CERN... was porting all the software libraries, I mean the software components that were on the NeXT system into a universal code library that was written in C, it's the 'libwww'" It didn't even have a name at the beginning, which is why in some history books, you see, 'Oh, libwww was released in November of 92.' No, it wasn't, you know? It was running since February '91, it just didn't have that name... We had the page rendering system, the parsing of HTML, and also all the URL mechanisms, history list, all that was abstracted into one software library as a package, as a toolset basically. And then in August 91, I think when we announced the World Wide Web, we also said 'You can use that toolset and build whatever you want with it'".
Right at the start the history is a bit messy. The WorldWideWeb browser was the graphical HTML browser (and editor) written by Tim-Berners Lee in Objective-C to run on NeXTSTEP. The first version was completed at the end of 1990 with the browser being later renamed to Nexus. The code was re-written in C by Tim and Jean-François and turned into the Libwww library to become the very first browser engine. This was then used by Nicola Pellow at CERN to write the Line Mode Browser which was text-based, usable over telnet and released in 1991.
This was not just the birth of the Web, but also the genesis of structures that now define what it means to be a Web browser. These same structures can be seen in how browsers are built today.
Libwww and the Line Mode Browser that were created from it continued to be developed right up until 2017. Although the library is written in C it applies an object-oriented approach. Structures have constructors and destructors with the me context variable often used in places where you might find this or self in an object-oriented language. Reading this code in the early noughties had a profound influence on me, shaping my own style of C coding to this day.
/* Create a Context Object
** -----------------------
*/
PRIVATE Context * Context_new (LineMode *lm, HTRequest *request, LMState state)
{
Context * me;
if ((me = (Context *) HT_CALLOC(1, sizeof (Context))) == NULL)
HT_OUTOFMEM("Context_new");
me->state = state;
me->request = request;
me->lm = lm;
HTRequest_setContext(request, (void *) me);
HTList_addObject(lm->active, (void *) me);
return me;
}
Besides the Line Mode Browser, Libwww was used in countless other projects. My own port to RISC OS from 2004 is still available. I used it to extend a forensic analysis tool for use on the Web (that the University I worked for later patented).More notably it was also used by the Amaya lightweight Web editor developed at INRIA and the Mosaic Browser developed at the NCSA. The Mosaic browser was popular in its day and the NCSA spun out a commercial entity in the form of Spyglass Mosaic which built on the NCSA Mosaic code. The company was set up to licence the browser to other companies.
Trident
This Microsoft duly did. The browser engine of Internet Explorer — called Trident — was built on the Mosaic technology. The first version of Internet Explorer shipped without JavaScript support (the language hadn't been invented yet), but when it arrived in IE 3 in 1996 it was powered by Microsoft's Chakra JavaScript (nee JScript) engine.The licensing agreement struck with Spyglass required Microsoft to pay a small monthly fee with additionally a portion of all non-Windoww revenue from the browser going to Spyglass.
As anyone who experienced the browser wars at that time will know, Microsoft proceeded to give Internet Explorer away for free with Windows. This ultimately earned them a lawsuit from Spyglass (settled out of court for $8 million) and an antitrust lawsuit from the US Government (eventually resulting in Microsoft having to change its approach to interoperability).
Internet Explorer remained as a core component of Windows until Windows 10, after which the company finally switched to offering Edge as the default browser. While Edge is built on Google's Blink engine, even that wasn't enough to dislodge Trident entirely. It remains to this day as the rendering engine powering Edge's compatibility mode. While it's not clear whether any of the original code can still be found in Edge (seems unlikely), a thirty-five year legacy is pretty good going.
Gecko
Internet Explorer's arch rival during the browser wars was Netscape Navigator, offered to consumers by countless dial-up Internet providers bundling it on free CDs alongside their own dial-up software and configurations. Netscape was the first browser to incorporate JavaScript support, which it did using the SpiderMonkey JavaScript interpreter in 1995.Running up to 2000 Netscape completely re-wrote their browser engine. The result was what we now know as Gecko and which powers both Firefox and the Sailfish Browser. The purpose of the re-write was ostensibly to improve standards compliance and maintainability. But the highly abstracted code — arguably what has allowed the renderer to remain relevant to this day — resulted in poor performance. Netscape Navigator was a large programme, incorporating not just a browser but also a full email client and Website editor. In an attempt to improve performance in 2002 the components were split up to form Firefox as a stand-alone Web browser and Thunderbird as a stand-alone email client. My recollection is that this was controversial at the time and didn't improve performance a great deal. But the separation stuck. Splitting email from Web and dropping editing entirely seems to have resonated with users.
Gecko, in the form of Firefox, has experienced ups and downs. Browser statistics are notoriously subjective, but Statscounter registers Firefox market share as having dropped to just over 3% as of January 2024, having peaked in January 2010 at just over 30%.
There's plenty more to say about Gecko's history, not least in relation to its use as an embeddable component, but let's put that aside for today and I'll return to it in a future post.
Gecko remains relevant today as the most popular alternative to the WebKit/Blink family of browsers. While technically open source, both WebKit and Blink are directed by large corporations with few concessions to open source development methodologies. Mozilla on the other hand is a not-for-profit foundation that embraces the spirit of open source as well as the letter. For many, Gecko is an important bulwark against a corporate-controlled browser monoculture.
An interesting twist in Gecko's development comes from its adoption of the Rust language. Developed by Mozilla employee Graydon Hoare and officially adopted by Mozilla in 2009, Mozilla has been gradually moving Gecko's internal components from C++ to Rust.
This led to the development of the Servo engine, written wholly in Rust as a Mozilla research project. While never intended to replace Gecko, elements of the Servo engine were integrated back into the Gecko's WebRender rendering engine.
Servo is currently available as an engine with an intentionally bare-bones user interface. Mozilla divested itself of Servo in 2020, but development continues with the aim of specifying a WebView API during 2024 for use as an embeddable engine.
Presto
We're going to jump ahead a little in the diagram and turn our attention to the Opera browser. There are many unique and fascinating facets to Opera that it won't be possible to explore fully here, but it's still worth skimming the surface. Opera is unusual in that it was, for a long time, one of the few independent commercial browsers. When first released in 1995 it was shareware (requiring payment after a trial period). There was no JavaScript support (the language hadn't been invented yet) and at the outset the rendering engine wasn't named separately to the browser. This changed in 2000 with the introduction of the Elektra rendering engine and the Linear A JavaScript engine. In 2003 Opera switched to using what they claimed to be a new rendering engine, the internally developed Presto, alongside a new Linear B JavaScript engine. While the Presto name stuck, Opera's JavaScript engines have enjoyed periodic renaming: the Futhark JavaScript engine in 2008, followed by the Carakan JavaScript engine in 2010. Since the browser and all of these engines are closed source it's impossible to know to what extent they were really new technology as compared to an evolution of existing code.Through much of its life Opera forged its own path. It was the first mainstream browser to introduce tabs. It integrated a (very good) email client long after Mozilla had disentangled Firefox and Thunderbird from Netscape Navigator. It even integrated its own Web server at one point. Opera also made a point of sticking to W3C standards while other browsers were still trying to lock users in to a proprietary Web.
Perhaps it's for this reason that there was much disappointment when Opera switched to using Blink and V8 in 2013, soon after Google and announced it would fork WebKit. To find out how it got to this point we'll need to go back a bit again and look at the evolution of WebKit.
WebKit and Blink
At this point in time WebKit is the most popular engine for accessing the Web (in either its WebKit or Blink variants). Moreover it's also the go-to browser engine for use in embedded scenarios as we'll see shortly.Initially part of the KDE project, WebKit provided the engine for Konquerer, the default browser for the KDE desktop environment. At that point the engine was referred to by the name KHTML, alongside the KJS JavaScript engine. It was picked up by Apple in 2001, apparently because of its small code footprint. Apple renamed KHTML and KJS to WebCore and JavaScriptCore respectively with the WebKit project encompassing both.
Contributions to WebKit came from both Apple and the KDE project, as well as from the Qt Project which offered the QtWebKit embeddable widget. Sailfish OS supported use of QtWebKit up until its deprecation in Sailfish OS 4.4 and removal in 4.5, the functionality being replaced by the Gecko WebView API.
In 2008 Google introduced its own Chrome browser also built on WebKit but using the new and Google-developed V8 JavaScript engine. Google's advertising for it emphasise speed (start times and JavaScript execution in particular). Chrome also had an — at the time — unusual sandboxing model with each tab executed as a separate process. This meant that crashes triggered by WebKit or V8 would only bring down a single tab, leaving other tabs and the browser intact.
Although built using many open source components, Chrome itself is made available under a proprietary licence. The Chromium project, also developed by Google, is a fully open source implementation of Chrome, but with the proprietary components removed.
From the outset Google had to make changes to WebKit to support its use in Chrome. Still it took another five years before Google officially forked WebKit in 2013, creating the Blink browser engine. Consequently Chrome now uses both its own renderer and JavaScript combination: Blink and V8.
One of the attractive features of the Blink engine, also particularly relevant to Sailfish OS, is its embedding API which allows it to be used separately from Chrome (or Chromium) and embedded in independent applications. A common example of this usage can be found in the Electron framework, which uses Blink for rendering.
This embeddable design, which neatly separates the chrome from the engine, also makes Blink attractive for use by other browser developers. As noted earlier, Opera switched from Presto and Caraken to Blink and V8 for rendering and JavaScript respectively. Microsoft similarly chose Blink and V8 as the basis for its Edge browser in 2019.
Qt introduced the Qt WebEngine component, wrapping Blink and V8 to offer an embeddable browser, around the release of Qt 5.2 in 2013. This was intended to replace QtWebKit, which was ultimately removed in Qt 5.6. The closest KDE has to a default browser is Falkon, which uses the Qt WebEngine. This therefore completed a strange cycle, with KHTML having been started as part of KDE, forked by Apple, forked again by Google and then integrated back in to KDE via Qt.
LibWeb
An unexpected entrant into the browser space was recently announced in the form of Ladybird. To understand why Ladybird exists, it helps to understand a little about Serenity OS, the operating system project it grew out of and which it has now eclipsed. According to the FAQ of Serenity OS the developers try to "maximize hackability, accountability, and fun(!) by implementing everything ourselves.". And that includes the Web browser: the project developed its own renderer and JavaScript engine in the form of the imaginatively-named LibWWW and LibJS.Recently the main Serenity OS developer, Andreas King, refocused his attention from the operating system to the Ladybird browser. Ladybird is built using the LibWeb and LibJS browser components of Serenity OS, but which he now develops independently. This arguably represents the first new engine to be introduced with the aim of being a fully-fledged browser for over twenty years, making for a particularly interesting development.
NetSurf
Last but not least we have NetSurf, which like Ladybird, is a bit of an outlier. Like Ladybird it was originally developed for exclusive use on a non-mainstream operating system.The first version of NetSurf was released in 2002. At that time it was developed exclusively for use on RISC OS, the operating system that powered the Acorn Archimedes (the first publicly available computer to use an ARM processor).
RISC OS is very different from most other operating systems available today. It makes no attempt to be Unix-like and has its own distinctive and cooperatively multitasking desktop environment. This heritage means that the browser is incredibly lightweight, with good CSS support but without viable JavaScript.
During the early days of development JavaScript support was considered out-of-scope for the browser. The reason for this is interesting: it wasn't for lack of a usable JavaScript interpreter, but because the browser lacked a standards-compliant DOM. It turns out JavaScript isn't especially useful without a standards-compliant way to access the elements of a Web page.
Despite the lack of JavaScript support NetSurf still managed to find a niche as a fast and lightweight browser, growing beyond RISC OS. As of today there are downloadable packages available for RISC OS, GTK (Linux), Haiku, AmigoOS, Atari and experimentally for Windows.
The Truth About Browsers
Browser history is a tangled Web. While writing this it quickly became clear that, when it comes to browsers, any generalised claim is likely to turn out false. The date a browser came into existence? Do you mean the date the project was first thought of? The first commit? The first release? An alpha release? A beta release? Release 1.0? Is a particular engine entirely new, the redevelopment of an old engine, or just a rename? To what extent does the code of one engine flow into another when they both share libraries? Every browser out there is like the Ship of Theseus at this point. When we talk about a browser engine are we talking about the renderer, the layout engine, the JavaScript engine, the chrome? Sometimes these things can be separated, other times they're intrinsically tied together. Is it good to have a single reference engine that all browsers use for a consistent experience across the Web, or should we be championing diversity as way to prevent any single entity taking control? Do we even know how to calculate browser market share?Even the question of what a browser is, presented in anything other than the most abstract terms, is likely to suffer exceptions.
What is clear is that browsers have become deeply integrated into our lives. Whether using a computer or smartphone, access to a browser has become a necessity. Over time they've continued to become more capable and more technically complex. Combined with their convoluted history, that makes them fascinating objects of study.
23 Sep 2024 : Retrospective #
Way back last year in August 2023, before actually starting the process of upgrading the Gecko engine in Sailfish OS from ESR 78 to ESR 91, I wrote a preamble in which I set out my objectives and sketched a brief plan for how to achieve them. Although the work isn't entirely complete, after 339 days I consider the main bulk of my work on the project to be complete. We're now in the mopping up stage. That means it's a good time to look back at the process, find out what went well, what went badly, what I've learned from the experience and how I feel about things. If the preamble was the opening bracket, this retrospective can be considered its closing partner. Together they're the bookends encapsulating all the diary entries in between.

On day 149 I gave a presentation of this work at FOSDEM'24, including an earlier version of this diagram. I thought I was about half way through the work at that stage, but this turned out to be an underestimate, as is clear from this diagram. I was in fact only 11/25 of the way through.
The longest task of 87 days involved getting the WebView render pipeline working. In comparison getting the first successful build to complete took only 45 days. Both of these were quite dark and gloomy times. Without a working build it's impossible to debug or test the code, whilst without a working renderer nothing else can be effectively tested. Both periods felt like dark tunnels that took an age to emerge from.
Following these in terms of length of task were PDF Printing at 28 days, the WebGL renderer at 25 days and the Sec-Fetch-* headers at 15 days. These were the only tasks that took more than 14 days, which is a bit of a cut-off point for me. After two weeks of writing daily about the tasks it becomes really hard to write more without sounding (and seeming) a bit lost and exhausted.
It was particularly frustrating how long it took to get the WebView rendering working, given the browser already worked nicely. It could have been worse though: I had a clear plan which involved gradually stripping out and adjusting pieces of code to align with the code in the ESR 78 implementation. This gradual convergence towards ESR 78 meant I knew the task was inevitably going to be time-limited, also allowing me to identify progress on a daily basis. As it turned out I had to do it twice: first removing code, then adding code back in again. But it did eventually get there.
Realising on Day 254, after all this, that I'd broken the WebGL rendering process was also a bit of a low point. By then I really wanted to move on from the render pipeline.
But eventually I did emerge from all of these tunnels and the joy of getting something to work is a crucial counterbalance to the frustration when it isn't. In retrospect the low points were all worth it for the sake of the enjoyment I also got out of it.
Apart from how things turned out in practice it's also interesting to compare how closely it matched my initial expectations. Returning to the preamble once again, it's clear I was expecting a long haul, but I also had experience to draw from my previous involvement in browser upgrades at Jolla:
I think it's fair to say that I did follow this approach, starting with getting things to compile and then focusing on the details afterwards. This led on to the following decision about the structure of the work:
In hindsight I think that was the right thing to do. But it also felt like a natural consequence of the situation I found myself in. Given the upstream code changes the patches I did apply needed quite a lot of work to get them to stick. That gave me the impression that many of the existing patches might turn out to be redundant, superseded by changes in the upstream code.
By applying only the patches that were necessary it give me the opportunity to potentially avoid patches which were no longer relevant in a more intentional way. Hopefully the patches I've ended up with are closer to the minimum required and have a slightly cleaner structure than would otherwise have been the case.
But practically speaking I think my original plan was a good one and, in retrospect, I followed it pretty closely.
Abstractly speaking, one of the most compelling reasons to want to upgrade is because websites routinely attempt to fingerprint browsers and serve different content depending on the result. This practice is as old as the hills, yet remains as common today as it is problematic. I understand that different browsers have different capabilities and that website creators will be blamed (unfairly) if a page renders poorly as a result of a user failing to keep their browser up-to-date. But you'd have thought at the very least browsers could test for features rather than versions.
When browsing using ESR 78 it's not uncommon for a site to chastise its own customers. Updating the engine on Sailfish OS is one way to reduce the chance of seeing these invectives, even if just changing the user agent string is often just as effective as a browser upgrade without any of the effort.
One of the worst offenders is Cloudflare, which routinely blocks the Sailfish browser from accessing sites on its content delivery network. Upgrading to ESR 91 seems to circumvent this in at least some cases.
But browser upgrades also bring genuine improvements as well. New features, improved stability, increased security and bug fixes. There have been a total of 45 point releases between the previous Sailfish OS engine of 78.15.0 and the upgraded version at 91.9.1. Each of these point releases has brought improvements, although not all will be relevant to Sailfish OS. Major releases (e.g. from 78 to 79) will typically include new features, stability improvements and security fixes, whereas point releases (e.g. 91.1.0 to 91.2.0) will often only include security and regression fixes.
Working through the Firefox changelogs the following are some of the obvious improvements that have a direct impact on the Sailfish browser:
In addition to the above changes, there were 15 critical, 115 high severity, 68 medium severity and 30 low severity security fixes combined into these updates. The importance of these can be best understand with reference to Mozilla's security classification:
Whether this is actually the case is hard to say. My tests using various performance measurement tools don't suggest significant performance improvements. But I must admit to having the same feeling of improved responsiveness. I suspect that may be due to the upstream changes in version 91.0 that claim to have improved responsiveness for user-interactions by 10-20%. That would make a noticeable improvement for users in a way that may not show up in benchmarks. It's my suspicion that the page loading feedback that's used to drive the progress bar on Sailfish OS has also been improved, although I've not found any explicit changes that would do this.
What do all of these changes mean for the state of the code? The upgrade from ESR 78 to ESR 91 also, surprisingly for me, brought with it a larger codebase. Mozilla has been intentionally transitioning code from C++ to Rust, with the number of lines of Rust code increasing by 14%. But the number of lines of C++ code also increased by 3% and for the total combined C++, JavaScript and Rust code this increased by 7%. Plotting the lines of code categorised by language, these increases are clearly visible.

Although proportionally there's been a bigger increase in Rust code than C++, in absolute terms the increase in both is almost identical (380607 lines of Rust code added compared to 384080 lines of C++ code).
In the above diagram Docs refers to content that relates to documentation. Build refers to scripts used to manage the build pipeline. IDL refers to interface definition files.
It's worth pausing to consider the code needed to build the Gecko engine. Gecko has experienced several changes through its life accumulating a mixture technologies as it goes. As a result the build system is a strange combination of Build (the mozilla build system), Python, Make, ninja, GN and Cargo. At certain points the build system compiles Rust into native binaries that then become part of the build pipeline itself. This causes havoc for the scratchbox2 cross-platform build engine Sailfish OS uses. No small part of the work in getting gecko working for Sailfish OS involves taming these build systems.
Although the numbers for IDL shown in the graph are low compared to the other languages, I nevertheless wanted to include it because it's such a critical part of the way Gecko works. The combination of C++/Rust and JavaScript means that there needs to be a really solid way to expose native methods to JavaScript and JavaScript methods to native code. The type systems aren't equivalent and so this requires a careful arrangement. Gecko supports this using its Interface Definition Language. IDL files read a bit like C++ header files but are more generic. Any interface defined using IDL can be exposed both natively and to the JavaScript layer. It's critical glue that holds everything together.
The numbers shown in the graph are measured in millions of lines of code. They're big numbers, but it's worth bearing in mind that Gecko is a relative minnow when it comes to code size in the world of browsers. For comparison I ran the same code analysis on the Chromium source. I was pretty surprised by how large Chromium is compared to Gecko.

Chromium contains over four times the code: 154 981 674 lines of code for Chromium compared to a paltry 37 361 820 lines of code for Gecko ESR 91. It's also interesting to compare the range of technologies involved in the two projects. Chromium introduces TypeScript, Go, Java, Objective-C, Lua, AppleScript, TCL and WASM, although some of these will be target-specific.
As any Sailfish OS developer will be aware, Sailfish OS uses RPMs for packaging software, a technology that originated on Red Hat Linux as the Red Hat Package Management system. Work started on RPM in 1995, a good ten years before the initial release of git and two years before Netscape started work on Gecko. Back then it was commonplace for software to be provided in the form of a tarball and in some ways the RPM build process reflects this. Distribution-specific changes are provided as patches applied directly to the upstream source. These patches are all listed in the spec file which is passed to the rpm tool to perform the build. On Sailfish OS this is all hidden behind sfdk which is itself a wrapper for the scratchbox2 sb2 tool. It's a complex layered system with multiple abstractions.
The point is that even now on Sailfish OS packages that use upstream code can pull directly from the upstream repositories, rather than having to use Sailfish-specific implementations. Any Sailfish OS specific changes can then be applied onto this code in the form of patches. It's not a process I enjoy working with because patching is a lot messier and less flexible than working with commits in a repository. Even though it's possible to convert a patch list into a series of commits and back again this adds an extra step and contrains what actions can be performed at different times.
The benefit is that we always retain a very clean and clear distinction between the upstream code and the Sailfish OS specific changes, with the latter being encapsulated in the patches to be applied. We can use this separation to discover how the changes needed to get Gecko ESR 78 to work with Sailfish OS differ compared to those needed for ESR 91.

This figure shows only a very high-level view, but nevertheless tells a story. Note that unlike the previous figures the y-axis of this chart uses a logarithmic scale to account for the big differences in scale between different languages. This can make the values harder to read so, for clarity, here they are in tabular form.
These numbers represent the actual code I've been working on for the last year. In general the number of lines added or removed has reduced as we've moved from ESR 78 to ESR 91. This is a good thing. The fewer changes made to the upstream code the better. In general the difference isn't huge, but it does exist. The total number of patches reduced from 98 to 84. The number of lines added to ESR 91 was 82% of the number of lines added to ESR 78. The number of lines removed from ESR 91 was only 57% of the number removed from ESR 91.
Interestingly, while there were fewer change made, the differences practically balance themselves out. Overall the patches to ESR 78 increased the code size by 31 383 lines compared to 31 049 lines for ESR 91. That's astonishingly similar.
These numbers don't quite capture all of the changes because they relate only to the gecko code. There were also changes needed in the other four components that make up the Sailfish browser stack, as well as to the EmbedLIte code (which is handled separately from gecko but ends up in the same xulrunner package). Let's briefly take a look at these other components.

The gecko renderer is by far the largest of the components. The qtmozembed component provides a QT wrapper around the renderer. The embedlite-components package adds the privileged JavaScript shims needed for Sailfish OS, largely replacing equivalent privileged JavaScript that would typically run in Firefox. The sailfish-components-webview component provides Qt components needed in order to support both the browser and WebView (for example the pop-up dialogues), but also provides the code needed to offer the rendering engine as a WebView component to other Qt apps. Finally the sailfish-browser component is the actual browser app you run when you open the browser on your phone.
Apart from the gecko renderer all of these are Sailfish-specific packages, so they don't have any "upstream" code. The Jolla repositories are the upstream repositories for these. Consequently there's no need to apply patches and we can work on the code directly. That means that when analysing changes for these we're just using the commits that take the code from ESR 78 versions to ESR 91 versions. Between them they accumulated 169 commits with the following additions and removals (these numbers also including the changes to the gecko source):
This table essentially captures the sum total of the changes needed to move from one version to the next. As you can see, the majority of the additions have been to C++ code. The build scripts saw rather a lot of churn. I'm very surprised to see more Rust additions than JavaScript additions. The QML code changed very little, which is perhaps to be expected given the external appearance, renderer aside, is almost identical. That was intentional: there's always scope to improve the Sailfish browser user interface, but my objective with this work was to get the renderer upgraded as quickly as possible. Changing the interface would have been a diversion.
Nevertheless, this was a big deal for me. I'm not a natural blogger so the prospect of writing about my coding on a daily basis was daunting at the outset. But it turned out to be surprisingly easy. Writing about specific tasks is very different from having to come up with inventive and interesting topics to write about on a daily basis.
Having to write daily diary entries undoubtedly helped keep me on track and working on the project every day. The need to have at least a few paragraphs to write about drove me to do the coding work.
There were a few occasions when I struggled with this. Typically on a Friday night after having spent two and a half hours on public transport returning from work. Having to then write up a diary entry in a tired state of semi-consciousness was not always ideal. But these cases were relatively rare.
There were also occasions — mostly in the middle of the work to get the various rendering pipelines working — when the work really got me down. Writing the diary entries made me very conscious of the progress I was — or in many cases wasn't — making. In the middle of the trough when it's really not clear whether it will be possible to come up with a solution, some of those occasions felt quite dark. If I hadn't been writing the diary I can imagine myself choosing to take a break and then having that break go on for several days.
But, and this is a big but, I was supported the entire way through by the amazing Sailfish community who responded to my posts on Mastodon and the forum, always encouraging and supportive. I'm not a social person and this was a bit of a shock for me. People out there in the Sailfish community and beyond really are the most encouraging and thoughtful people you could hope to interact with.
The amazing images and poetry from the likes of Thigg (thigg) and Leif-Jöran Olsson (ljo) are beautiful cases in point.

But there are so many people who helped and contributed in so many ways, I couldn't possibly mention everyone here. I apologise for not mentioning you all individually, but I'm really grateful.
Besides the community I also have to mention Joanna, my wife, who's sacrificed more than anyone else for the sake of me spending three hours each day and most of my weekends on gecko development. She carried me through this.
With all of this support, I found the experience surprisingly effortless. Perhaps the biggest challenge, as it turns out, was being able to find a suitable point to wind things down. Dropping off from posting diary entries every day and having a very clear purpose for my free time has been hard to manage in a measured way. It was too much of a cliff edge and, if I do this again, I think I'd want to look into ways to mitigate this. But I don't yet have a good solution: writing these diary entries doesn't lend itself to a tapered reduction of work.
As I write this the current situation is that three out of five pull requests have been merged into Jolla's repositories. The remaining three have been through a couple of review rounds already. So the immediate task is to get them through review and merged in. This alone won't result in their release as part of Sailfish OS as they're currently being merged into bespoke ESR 91 branches. Jolla will need to merge these into the main branch before they can become part of any official Sailfish OS release.
It's nevertheless exciting to see that as part of the recent upgrade from Sailfish OS 4.6.0.13 to 4.6.0.15, several changes to libhybris were included that will support the move to ESR 91. As readers of my diary entries will know, there were several issues that caused the browser to crash or hang which were ultimately traced back to libhybris and which, looking at the changelog, will now be fixed. If ESR 91 does go out in some future Sailfish OS release, this will make the transition much smoother.
At present I've been building exclusively for aarch64. The build will need to be tested and potentially amended for armv7hl and i486 targets. On top of this, it appears that getting the browser to work on native platforms such as the emulator and the PinePhone, where there is no libhybris layer, will also require some additional work.
In the longer term, there are two, maybe three, objectives. The obvious next step after the release of ESR 91 would be to move to the next ESR release, which is 102.15.1. Checking the various release notes we can see that ESR 91.9.1 was released on 20 May 2022, whereas ESR 102.15.1 was released on 12 September 2023. That's a gap of around 16 months. So far the upgrade from ESR 78 has taken 13 months, so it looks like we may have an opportunity to catch up with Firefox ESR latest. In practice though it's usually around 12 months between ESR releases so some acceleration will be needed if we're to properly keep up. It's worth noting that the extended service releases have a much longer support cycle than other releases, which can lead to some overlap. For example both ESR 115.15.0 and ESR 128.2.0 were released on 3 September 2024.
Besides the obvious upgrade to the renderer engine it would also be great to add features to the browser. On the Sailfish OS Forum Niels (fingus) suggested supporting MPRIS for the video and audio controls of the browser. That's the sort of thing I'd love to add, but which would require some research and effort to investigate and implement. I'd also love to introduce support for reader mode, scrollbars and maybe even extensions. There's no shortage of interesting ideas for things to work on.
The third objective would be to properly support the WebRender compositor on Sailfish OS. It's not clear how much work this would involve, but it's potentially substantial. Integrating this with the Sailfish OS render pipeline could be quite a challenge.
Finally there's plenty of scope to make important improvements to the browser build process. Updating Rust, fixing the multi-process hang — which remains a significant barrier to reducing build times — and introducing a build cache would all help to make development easier.
But I've learnt a whole lot more than this and not just from the process of development, but also from the experience of writing a daily diary about it. I'd like to think that the work has helped demonstrate the importance and benefit of open source, for users of course, but also for Jolla. Jolla invested heavily in ensuring the browser is open source. Not just in giving the code the right licence and making the source available, but also in documenting it, following an open development model and supporting the community in making it accessible. In no way was this a "free" browser upgrade for Jolla, but I hope it goes some small way to justifying this open source strategy. I'd also like to think the diary entries have demonstrated some of the benefits of being open about progress as well.
I've also learnt more than I'd like to admit about Brownian debugging. This is the process of performing a random walk, changing bits of the code en route, until it works. It may not be the most efficient debugging approach and it may be that an element of strategic direction improves matters, but as long as the problem space can be constrained I've found Brownian debugging can be unexpectedly effective. Given enough time and patience.
There's a follow-up to this, which is that it also demonstrates how much can be achieved without the benefit of understanding or insight, but relying on perseverance alone. I'm definitely more familiar with the gecko code than when I started, but the gaps in my knowledge remain prodigious. Armed only with my abilities in Brownian debugging and enough time to deploy them, I managed to make some progress.
I admit this wasn't my first involvement in upgrading the browser. While working at Jolla I contributed to the upgrade from ESR 60 to ESR 68, and then again from ESR 68 to ESR 78. But that was as part of a team with an incredible depth of knowledge of the browser and impressive software development skills. When I started this process I wasn't at all certain whether I'd be able to make any meaningful contribution to the next upgrade. I'm now much more confident that not only has this been possible, but that I'd be able to do it again.
It's been great to feel some purpose within the Sailfish OS community. I really enjoyed working for Jolla, not least because it felt worthwhile contributing to an operating system I love using, but also contributing to the community I felt a part of. Doing this work has served as a great way to continue feeling like I have something to contribute.
Writing the development diaries was, I hope, helpful in demonstrating that work was continuing on the browser: it hadn't been forgotten or left to decay. It gave me a lot more visibility than I would have got otherwise. Crucially though it made me realise that there are many, many, Sailfish OS developers putting in similar or greater levels of commitment, for ports and apps and bug checking, who may not have the same visibility because they're not writing a diary, but who nevertheless put in more work and deserve the same appreciation that I've felt privileged to have received from the community.
Comment
The Journey
Back when I started I hadn't quite appreciated how long this whole process was going to take. Although somewhere between half a year and a year seemed reasonable, the final 339 day tally is a little closer to the latter than I'd hoped. Moreover a year in theory feels much shorter than a year in practice. Adjusting for the fact I'm employed full-time to not do Gecko work, in practice I must have worked only around three hours a day during the week and twelve hours at the weekend. Two thirds of that time was spent coding and the other third writing up the diary entries. Given that the 339 days was made up of 244 weekdays and 48 weekends, I can be a bit more precise about how much time I actually spent on it.$ time gecko-dev real 48w 3d 0h 0m 0.000s code 5w 1d 12h 0m 0.000s diary 2w 4d 4h 0m 0.000sLet's convert that into work time. This is interesting because practically speaking this is the "Full Time Equivalent" (FTE) or the amount of person-hours needed to complete the project from a commercial perspective. Typically the work would of course be distributed between multiple people to speed up project implementation, so the real time would be shorter.
$ time --work gecko-dev real 67w 4d 0h 0m 0.000s code 23w 1d 2h 0m 0.000s diary 11w 3d 1h 0m 0.000sLet's consider now how those days were partitioned into tasks. The following diagram shows the linear sequence of how I spent each day of work. This oversimplifies things a little given I didn't always complete tasks sequentially, but is pretty close to reality.
On day 149 I gave a presentation of this work at FOSDEM'24, including an earlier version of this diagram. I thought I was about half way through the work at that stage, but this turned out to be an underestimate, as is clear from this diagram. I was in fact only 11/25 of the way through.
The longest task of 87 days involved getting the WebView render pipeline working. In comparison getting the first successful build to complete took only 45 days. Both of these were quite dark and gloomy times. Without a working build it's impossible to debug or test the code, whilst without a working renderer nothing else can be effectively tested. Both periods felt like dark tunnels that took an age to emerge from.
Following these in terms of length of task were PDF Printing at 28 days, the WebGL renderer at 25 days and the Sec-Fetch-* headers at 15 days. These were the only tasks that took more than 14 days, which is a bit of a cut-off point for me. After two weeks of writing daily about the tasks it becomes really hard to write more without sounding (and seeming) a bit lost and exhausted.
It was particularly frustrating how long it took to get the WebView rendering working, given the browser already worked nicely. It could have been worse though: I had a clear plan which involved gradually stripping out and adjusting pieces of code to align with the code in the ESR 78 implementation. This gradual convergence towards ESR 78 meant I knew the task was inevitably going to be time-limited, also allowing me to identify progress on a daily basis. As it turned out I had to do it twice: first removing code, then adding code back in again. But it did eventually get there.
Realising on Day 254, after all this, that I'd broken the WebGL rendering process was also a bit of a low point. By then I really wanted to move on from the render pipeline.
But eventually I did emerge from all of these tunnels and the joy of getting something to work is a crucial counterbalance to the frustration when it isn't. In retrospect the low points were all worth it for the sake of the enjoyment I also got out of it.
Apart from how things turned out in practice it's also interesting to compare how closely it matched my initial expectations. Returning to the preamble once again, it's clear I was expecting a long haul, but I also had experience to draw from my previous involvement in browser upgrades at Jolla:
Another piece of wisdom that Raine taught me is that the first task of upgrading the engine should always be to get it to compile. Once it's compiling, getting it to actually run on a phone, patching all of the regressions and fixing up all the integrations can follow. But without a compiling build there's no point in spending time on these other parts.
I think it's fair to say that I did follow this approach, starting with getting things to compile and then focusing on the details afterwards. This led on to the following decision about the structure of the work:
I'm therefore going for a three-stage process with the upgrade:
Looking back I did broadly follow this structure. I got the build to complete, then I applied the patches needed to get rendering working and only after that did I apply the other patches. I did diverge from this advice in one important respect. Rather than applying all of the remaining patches I actually only applied a minimal set required to get the render working.- Apply a minimal set of changes and patches to get ESR 91 to build.
- Apply any remaining patches where possible and other changes to get it to run and render.
- Handle the Sailfish OS specific integrations.
In hindsight I think that was the right thing to do. But it also felt like a natural consequence of the situation I found myself in. Given the upstream code changes the patches I did apply needed quite a lot of work to get them to stick. That gave me the impression that many of the existing patches might turn out to be redundant, superseded by changes in the upstream code.
By applying only the patches that were necessary it give me the opportunity to potentially avoid patches which were no longer relevant in a more intentional way. Hopefully the patches I've ended up with are closer to the minimum required and have a slightly cleaner structure than would otherwise have been the case.
But practically speaking I think my original plan was a good one and, in retrospect, I followed it pretty closely.
Destination Gecko
Let's now consider where the journey took us. The point of all this work was to take the browser engine from ESR 78 to ESR 91. What does this give us?Abstractly speaking, one of the most compelling reasons to want to upgrade is because websites routinely attempt to fingerprint browsers and serve different content depending on the result. This practice is as old as the hills, yet remains as common today as it is problematic. I understand that different browsers have different capabilities and that website creators will be blamed (unfairly) if a page renders poorly as a result of a user failing to keep their browser up-to-date. But you'd have thought at the very least browsers could test for features rather than versions.
When browsing using ESR 78 it's not uncommon for a site to chastise its own customers. Updating the engine on Sailfish OS is one way to reduce the chance of seeing these invectives, even if just changing the user agent string is often just as effective as a browser upgrade without any of the effort.
One of the worst offenders is Cloudflare, which routinely blocks the Sailfish browser from accessing sites on its content delivery network. Upgrading to ESR 91 seems to circumvent this in at least some cases.
But browser upgrades also bring genuine improvements as well. New features, improved stability, increased security and bug fixes. There have been a total of 45 point releases between the previous Sailfish OS engine of 78.15.0 and the upgraded version at 91.9.1. Each of these point releases has brought improvements, although not all will be relevant to Sailfish OS. Major releases (e.g. from 78 to 79) will typically include new features, stability improvements and security fixes, whereas point releases (e.g. 91.1.0 to 91.2.0) will often only include security and regression fixes.
Working through the Firefox changelogs the following are some of the obvious improvements that have a direct impact on the Sailfish browser:
- Certificate performance improvements (80.0.1).
- WebGL rendering improvements (80.0.1).
- Support for viewing more filetypes (81.0).
- Improved element rendering (81.0.1, 86.0.1).
- Improved PDF export (81.0.1, 85.0.1, 90.0.2).
- Increased startup and rendering speeds (82.0).
- Fixes for WebSocket message duplication (82.0.2).
- SpiderMonkey JavaScript performance improvements (83.0).
- An HTTPS-Only mode option (83.0).
- Improved shared memory performance (84.0).
- Increased cookie and supercookie isolation (85.0, 86.0, 89.0, 90.0, 91.0).
- Deprecation of WebRTC DTLS 1.0 (86.0).
- Private browsing compatibility improvements (87.0).
- Increased referrer privacy (87.0, 88.0).
- Working hyperlinks in PDF export (90.0).
- Removal of FTP support (90.0).
- Improved user-action response times (91.0).
- Fixes for microsoft.com certificate errors (91.4.1).
- Many crash bug fixes (81.0.1, 82.0.1, 85.0.1).
In addition to the above changes, there were 15 critical, 115 high severity, 68 medium severity and 30 low severity security fixes combined into these updates. The importance of these can be best understand with reference to Mozilla's security classification:
- Critical: Vulnerability can be used to run attacker code and install software, requiring no user interaction beyond normal browsing.
- High: Vulnerability can be used to gather sensitive data from sites in other windows or inject data or code into those sites, requiring no more than normal browsing actions.
- Moderate: Vulnerabilities that would otherwise be High or Critical except they only work in uncommon non-default configurations or require the user to perform complicated and/or unlikely steps.
- Low: Minor security vulnerabilities such as Denial of Service attacks, minor data leaks, or spoofs. (Undetectable spoofs of SSL indicia would have "High" impact because those are generally used to steal sensitive data intended for other sites.)
Whether this is actually the case is hard to say. My tests using various performance measurement tools don't suggest significant performance improvements. But I must admit to having the same feeling of improved responsiveness. I suspect that may be due to the upstream changes in version 91.0 that claim to have improved responsiveness for user-interactions by 10-20%. That would make a noticeable improvement for users in a way that may not show up in benchmarks. It's my suspicion that the page loading feedback that's used to drive the progress bar on Sailfish OS has also been improved, although I've not found any explicit changes that would do this.
What do all of these changes mean for the state of the code? The upgrade from ESR 78 to ESR 91 also, surprisingly for me, brought with it a larger codebase. Mozilla has been intentionally transitioning code from C++ to Rust, with the number of lines of Rust code increasing by 14%. But the number of lines of C++ code also increased by 3% and for the total combined C++, JavaScript and Rust code this increased by 7%. Plotting the lines of code categorised by language, these increases are clearly visible.
Although proportionally there's been a bigger increase in Rust code than C++, in absolute terms the increase in both is almost identical (380607 lines of Rust code added compared to 384080 lines of C++ code).
In the above diagram Docs refers to content that relates to documentation. Build refers to scripts used to manage the build pipeline. IDL refers to interface definition files.
It's worth pausing to consider the code needed to build the Gecko engine. Gecko has experienced several changes through its life accumulating a mixture technologies as it goes. As a result the build system is a strange combination of Build (the mozilla build system), Python, Make, ninja, GN and Cargo. At certain points the build system compiles Rust into native binaries that then become part of the build pipeline itself. This causes havoc for the scratchbox2 cross-platform build engine Sailfish OS uses. No small part of the work in getting gecko working for Sailfish OS involves taming these build systems.
Although the numbers for IDL shown in the graph are low compared to the other languages, I nevertheless wanted to include it because it's such a critical part of the way Gecko works. The combination of C++/Rust and JavaScript means that there needs to be a really solid way to expose native methods to JavaScript and JavaScript methods to native code. The type systems aren't equivalent and so this requires a careful arrangement. Gecko supports this using its Interface Definition Language. IDL files read a bit like C++ header files but are more generic. Any interface defined using IDL can be exposed both natively and to the JavaScript layer. It's critical glue that holds everything together.
The numbers shown in the graph are measured in millions of lines of code. They're big numbers, but it's worth bearing in mind that Gecko is a relative minnow when it comes to code size in the world of browsers. For comparison I ran the same code analysis on the Chromium source. I was pretty surprised by how large Chromium is compared to Gecko.
Chromium contains over four times the code: 154 981 674 lines of code for Chromium compared to a paltry 37 361 820 lines of code for Gecko ESR 91. It's also interesting to compare the range of technologies involved in the two projects. Chromium introduces TypeScript, Go, Java, Objective-C, Lua, AppleScript, TCL and WASM, although some of these will be target-specific.
Destination Sailfish
So far we've considered the differences between ESR 78 and ESR 91 in some detail, but none of this has touched on the actual changes needed to get the code to run on Sailfish OS.As any Sailfish OS developer will be aware, Sailfish OS uses RPMs for packaging software, a technology that originated on Red Hat Linux as the Red Hat Package Management system. Work started on RPM in 1995, a good ten years before the initial release of git and two years before Netscape started work on Gecko. Back then it was commonplace for software to be provided in the form of a tarball and in some ways the RPM build process reflects this. Distribution-specific changes are provided as patches applied directly to the upstream source. These patches are all listed in the spec file which is passed to the rpm tool to perform the build. On Sailfish OS this is all hidden behind sfdk which is itself a wrapper for the scratchbox2 sb2 tool. It's a complex layered system with multiple abstractions.
The point is that even now on Sailfish OS packages that use upstream code can pull directly from the upstream repositories, rather than having to use Sailfish-specific implementations. Any Sailfish OS specific changes can then be applied onto this code in the form of patches. It's not a process I enjoy working with because patching is a lot messier and less flexible than working with commits in a repository. Even though it's possible to convert a patch list into a series of commits and back again this adds an extra step and contrains what actions can be performed at different times.
The benefit is that we always retain a very clean and clear distinction between the upstream code and the Sailfish OS specific changes, with the latter being encapsulated in the patches to be applied. We can use this separation to discover how the changes needed to get Gecko ESR 78 to work with Sailfish OS differ compared to those needed for ESR 91.
This figure shows only a very high-level view, but nevertheless tells a story. Note that unlike the previous figures the y-axis of this chart uses a logarithmic scale to account for the big differences in scale between different languages. This can make the values harder to read so, for clarity, here they are in tabular form.
| Language | ESR 78 added | ESR 78 removed | ESR 91 added | ESR 91 removed |
|---|---|---|---|---|
| C++ | 22 726 | 606 | 22 476 | 631 |
| Docs | 510 | 2 | 508 | 12 |
| Build | 28 558 | 20 350 | 19 320 | 11 090 |
| JavaScript | 158 | 6 | 170 | 43 |
| Rust | 544 | 175 | 498 | 180 |
| IDL | 29 | 3 | 39 | 6 |
These numbers represent the actual code I've been working on for the last year. In general the number of lines added or removed has reduced as we've moved from ESR 78 to ESR 91. This is a good thing. The fewer changes made to the upstream code the better. In general the difference isn't huge, but it does exist. The total number of patches reduced from 98 to 84. The number of lines added to ESR 91 was 82% of the number of lines added to ESR 78. The number of lines removed from ESR 91 was only 57% of the number removed from ESR 91.
Interestingly, while there were fewer change made, the differences practically balance themselves out. Overall the patches to ESR 78 increased the code size by 31 383 lines compared to 31 049 lines for ESR 91. That's astonishingly similar.
These numbers don't quite capture all of the changes because they relate only to the gecko code. There were also changes needed in the other four components that make up the Sailfish browser stack, as well as to the EmbedLIte code (which is handled separately from gecko but ends up in the same xulrunner package). Let's briefly take a look at these other components.
The gecko renderer is by far the largest of the components. The qtmozembed component provides a QT wrapper around the renderer. The embedlite-components package adds the privileged JavaScript shims needed for Sailfish OS, largely replacing equivalent privileged JavaScript that would typically run in Firefox. The sailfish-components-webview component provides Qt components needed in order to support both the browser and WebView (for example the pop-up dialogues), but also provides the code needed to offer the rendering engine as a WebView component to other Qt apps. Finally the sailfish-browser component is the actual browser app you run when you open the browser on your phone.
Apart from the gecko renderer all of these are Sailfish-specific packages, so they don't have any "upstream" code. The Jolla repositories are the upstream repositories for these. Consequently there's no need to apply patches and we can work on the code directly. That means that when analysing changes for these we're just using the commits that take the code from ESR 78 versions to ESR 91 versions. Between them they accumulated 169 commits with the following additions and removals (these numbers also including the changes to the gecko source):
| Language | Lines added | Lines removed |
|---|---|---|
| C++ | 23 456 | 1 281 |
| Docs | 508 | 12 |
| Build | 19 724 | 11 381 |
| JavaScript | 452 | 114 |
| Rust | 498 | 180 |
| IDL | 52 | 17 |
| QML | 14 | 14 |
| Total | 44 704 | 12 999 |
This table essentially captures the sum total of the changes needed to move from one version to the next. As you can see, the majority of the additions have been to C++ code. The build scripts saw rather a lot of churn. I'm very surprised to see more Rust additions than JavaScript additions. The QML code changed very little, which is perhaps to be expected given the external appearance, renderer aside, is almost identical. That was intentional: there's always scope to improve the Sailfish browser user interface, but my objective with this work was to get the renderer upgraded as quickly as possible. Changing the interface would have been a diversion.
Mental Health
I put a lot of myself into the Gecko upgrade. Working on it practically every day for a year, even if not full-time, required a level of commitment that I wouldn't typically give outside of my work hours. This is a personal perspective: the world is blessed with many people who commit far more for far less reward and who don't then feel the need to tell the world about it in a blog post.Nevertheless, this was a big deal for me. I'm not a natural blogger so the prospect of writing about my coding on a daily basis was daunting at the outset. But it turned out to be surprisingly easy. Writing about specific tasks is very different from having to come up with inventive and interesting topics to write about on a daily basis.
Having to write daily diary entries undoubtedly helped keep me on track and working on the project every day. The need to have at least a few paragraphs to write about drove me to do the coding work.
There were a few occasions when I struggled with this. Typically on a Friday night after having spent two and a half hours on public transport returning from work. Having to then write up a diary entry in a tired state of semi-consciousness was not always ideal. But these cases were relatively rare.
There were also occasions — mostly in the middle of the work to get the various rendering pipelines working — when the work really got me down. Writing the diary entries made me very conscious of the progress I was — or in many cases wasn't — making. In the middle of the trough when it's really not clear whether it will be possible to come up with a solution, some of those occasions felt quite dark. If I hadn't been writing the diary I can imagine myself choosing to take a break and then having that break go on for several days.
But, and this is a big but, I was supported the entire way through by the amazing Sailfish community who responded to my posts on Mastodon and the forum, always encouraging and supportive. I'm not a social person and this was a bit of a shock for me. People out there in the Sailfish community and beyond really are the most encouraging and thoughtful people you could hope to interact with.
The amazing images and poetry from the likes of Thigg (thigg) and Leif-Jöran Olsson (ljo) are beautiful cases in point.

But there are so many people who helped and contributed in so many ways, I couldn't possibly mention everyone here. I apologise for not mentioning you all individually, but I'm really grateful.
Besides the community I also have to mention Joanna, my wife, who's sacrificed more than anyone else for the sake of me spending three hours each day and most of my weekends on gecko development. She carried me through this.
With all of this support, I found the experience surprisingly effortless. Perhaps the biggest challenge, as it turns out, was being able to find a suitable point to wind things down. Dropping off from posting diary entries every day and having a very clear purpose for my free time has been hard to manage in a measured way. It was too much of a cliff edge and, if I do this again, I think I'd want to look into ways to mitigate this. But I don't yet have a good solution: writing these diary entries doesn't lend itself to a tapered reduction of work.
Future Work
Future work for this project comes in two forms. There's the future work needed to achieve the (hopefully) near-term goal of getting the browser released to users as part of Sailfish OS. Then there's the longer term goal of what to do beyond that.As I write this the current situation is that three out of five pull requests have been merged into Jolla's repositories. The remaining three have been through a couple of review rounds already. So the immediate task is to get them through review and merged in. This alone won't result in their release as part of Sailfish OS as they're currently being merged into bespoke ESR 91 branches. Jolla will need to merge these into the main branch before they can become part of any official Sailfish OS release.
It's nevertheless exciting to see that as part of the recent upgrade from Sailfish OS 4.6.0.13 to 4.6.0.15, several changes to libhybris were included that will support the move to ESR 91. As readers of my diary entries will know, there were several issues that caused the browser to crash or hang which were ultimately traced back to libhybris and which, looking at the changelog, will now be fixed. If ESR 91 does go out in some future Sailfish OS release, this will make the transition much smoother.
At present I've been building exclusively for aarch64. The build will need to be tested and potentially amended for armv7hl and i486 targets. On top of this, it appears that getting the browser to work on native platforms such as the emulator and the PinePhone, where there is no libhybris layer, will also require some additional work.
In the longer term, there are two, maybe three, objectives. The obvious next step after the release of ESR 91 would be to move to the next ESR release, which is 102.15.1. Checking the various release notes we can see that ESR 91.9.1 was released on 20 May 2022, whereas ESR 102.15.1 was released on 12 September 2023. That's a gap of around 16 months. So far the upgrade from ESR 78 has taken 13 months, so it looks like we may have an opportunity to catch up with Firefox ESR latest. In practice though it's usually around 12 months between ESR releases so some acceleration will be needed if we're to properly keep up. It's worth noting that the extended service releases have a much longer support cycle than other releases, which can lead to some overlap. For example both ESR 115.15.0 and ESR 128.2.0 were released on 3 September 2024.
Besides the obvious upgrade to the renderer engine it would also be great to add features to the browser. On the Sailfish OS Forum Niels (fingus) suggested supporting MPRIS for the video and audio controls of the browser. That's the sort of thing I'd love to add, but which would require some research and effort to investigate and implement. I'd also love to introduce support for reader mode, scrollbars and maybe even extensions. There's no shortage of interesting ideas for things to work on.
The third objective would be to properly support the WebRender compositor on Sailfish OS. It's not clear how much work this would involve, but it's potentially substantial. Integrating this with the Sailfish OS render pipeline could be quite a challenge.
Finally there's plenty of scope to make important improvements to the browser build process. Updating Rust, fixing the multi-process hang — which remains a significant barrier to reducing build times — and introducing a build cache would all help to make development easier.
Lessons Learned
The main outcome of this work for me has been the reaffirmation that the browser is a critical component of Sailfish OS. The better the browser the more usable Sailfish OS becomes as a daily driver. Make no mistake, the reason I wanted to do this work was for entirely selfish reasons: Sailfish OS is my mobile phone operating system of choice. I enjoy using it and I want it to remain relevant so that it continues to be supported. Upgrading the browser is my way of helping ensure this happens; it's my itch and I've been scratching it.But I've learnt a whole lot more than this and not just from the process of development, but also from the experience of writing a daily diary about it. I'd like to think that the work has helped demonstrate the importance and benefit of open source, for users of course, but also for Jolla. Jolla invested heavily in ensuring the browser is open source. Not just in giving the code the right licence and making the source available, but also in documenting it, following an open development model and supporting the community in making it accessible. In no way was this a "free" browser upgrade for Jolla, but I hope it goes some small way to justifying this open source strategy. I'd also like to think the diary entries have demonstrated some of the benefits of being open about progress as well.
I've also learnt more than I'd like to admit about Brownian debugging. This is the process of performing a random walk, changing bits of the code en route, until it works. It may not be the most efficient debugging approach and it may be that an element of strategic direction improves matters, but as long as the problem space can be constrained I've found Brownian debugging can be unexpectedly effective. Given enough time and patience.
There's a follow-up to this, which is that it also demonstrates how much can be achieved without the benefit of understanding or insight, but relying on perseverance alone. I'm definitely more familiar with the gecko code than when I started, but the gaps in my knowledge remain prodigious. Armed only with my abilities in Brownian debugging and enough time to deploy them, I managed to make some progress.
I admit this wasn't my first involvement in upgrading the browser. While working at Jolla I contributed to the upgrade from ESR 60 to ESR 68, and then again from ESR 68 to ESR 78. But that was as part of a team with an incredible depth of knowledge of the browser and impressive software development skills. When I started this process I wasn't at all certain whether I'd be able to make any meaningful contribution to the next upgrade. I'm now much more confident that not only has this been possible, but that I'd be able to do it again.
It's been great to feel some purpose within the Sailfish OS community. I really enjoyed working for Jolla, not least because it felt worthwhile contributing to an operating system I love using, but also contributing to the community I felt a part of. Doing this work has served as a great way to continue feeling like I have something to contribute.
Writing the development diaries was, I hope, helpful in demonstrating that work was continuing on the browser: it hadn't been forgotten or left to decay. It gave me a lot more visibility than I would have got otherwise. Crucially though it made me realise that there are many, many, Sailfish OS developers putting in similar or greater levels of commitment, for ports and apps and bug checking, who may not have the same visibility because they're not writing a diary, but who nevertheless put in more work and deserve the same appreciation that I've felt privileged to have received from the community.
15 Sep 2024 : Week 49 Summary #
It's been a week since I last posted a diary entry. It turns out that not writing a diary entry everyday is almost as hard as writing one. If I'm not wandering aimlessly around the house trying to find a purpose, I find I'm sitting on the sofa quietly mumbling gdb backtrace nonsense to myself.
Thankfully there are still some tasks to do, addressing review comments and reviewing others' commits. I'll talk about these happenings today. But I also want to share some retrospective analysis of the project: what went well, what went badly and how the whole process felt as an experience. I'll be expanding on all that in a future post.
First up I want to highlight the really nice fix from from Vlad G (vlagged) that's fixed certificate overrides. When the browser accesses a site using HTTPS but receives a bad certificate, it'll present the user with an error page. This is to avoid the user mistakenly believing that the data being sent from the site, or that they're sending back to it, is being done so securely (i.e. using a channel that maintains integrity and confidentiality).
There are still some sites that don't support HTTPS which provide no more security than a site with a broken or bad certificate. But the latter is worse in that could give the user a false sense of security. If there's a failure it could be an attack. Exposing this to the user in an overt way is critical for them to make an informed decision about how to proceed.
That means that Firefox typically offers the option to view the site anyway, as long as the warning page has been prominently presented. It's hard to imagine anyone could miss the bad certificate page given the way it's presented on Sailfish OS.
Changes to the underlying API however mean that the ESR 91 upgrade broke the option to bypass the certificate check. With this broken code, selecting the option to "view the page anyway" caused the browser to return the same certificate warning page rather than actually going to the site. That's because the button is supposed to record a "certificate override" stating that the browser should ignore the bad certificate. But the method to perform this has changed parameters, so it was throwing up an error rather than recording the site details.
Here we can see the blame for the interface file where the new parameter was added by R. Martinho Fernandes:
As I write this I've approved the change myself and hopefully it'll be picked up and reviewed by Jolla so that it can be merged swiftly in to the ESR 91 branch.
Besides this I also received really nice review feedback from sailors Raine (rainemak) and Mal (mlehtima) in relation to my gecko-dev pull request. This pull request is the one that actually performs the upgrade from ESR 78 to ESR 91. The upgrade takes the form of redirecting a submodule to a different upstream commit so is a super-simple change. The bigger part is the set of patches that then has to be applied on top of the upstream code to make it all work. This is all in the pull request as well.
Raine and Mal clearly spent some time going through the commits and I'm really grateful for their suggestions. The result was better preference handling and several commits being merged or removed entirely. On Mal's request I also rebased the code to bring in recent changes needed to support Jolla's updated SDK. The totality of these changes all make for a much cleaner commit history and impoved code.
This pull request, along with the pull requests for the sailfish-browser and sailfish-components-webview repositories, are now awaiting a second review from the Jolla team. As far as I'm aware I've completed the changes requested, but there may still be a few more review rounds to go before they get merged in.
The other change this week has been to the package tarballs available from my website. These are very much still testing packages and you should read all of the info in the installation instructions before you use them. Nevertheless these new packages should provide some nice improvements over the previous ones. The main changes are:
You should, however, still do step 5 to clean out the old settings files. This won't clear cookies, tabs, history or anything like that, but it will reset any preferences you've changed using about:config. In summary, if you already have ESR 91 installed you should complete the following steps:
That summarises the changes this week. I'm still writing up my retrospective of the project so far and will post it once it's ready.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
Comment
Thankfully there are still some tasks to do, addressing review comments and reviewing others' commits. I'll talk about these happenings today. But I also want to share some retrospective analysis of the project: what went well, what went badly and how the whole process felt as an experience. I'll be expanding on all that in a future post.
First up I want to highlight the really nice fix from from Vlad G (vlagged) that's fixed certificate overrides. When the browser accesses a site using HTTPS but receives a bad certificate, it'll present the user with an error page. This is to avoid the user mistakenly believing that the data being sent from the site, or that they're sending back to it, is being done so securely (i.e. using a channel that maintains integrity and confidentiality).
There are still some sites that don't support HTTPS which provide no more security than a site with a broken or bad certificate. But the latter is worse in that could give the user a false sense of security. If there's a failure it could be an attack. Exposing this to the user in an overt way is critical for them to make an informed decision about how to proceed.
That means that Firefox typically offers the option to view the site anyway, as long as the warning page has been prominently presented. It's hard to imagine anyone could miss the bad certificate page given the way it's presented on Sailfish OS.
Changes to the underlying API however mean that the ESR 91 upgrade broke the option to bypass the certificate check. With this broken code, selecting the option to "view the page anyway" caused the browser to return the same certificate warning page rather than actually going to the site. That's because the button is supposed to record a "certificate override" stating that the browser should ignore the bad certificate. But the method to perform this has changed parameters, so it was throwing up an error rather than recording the site details.
Here we can see the blame for the interface file where the new parameter was added by R. Martinho Fernandes:
$ git blame -c --date=short \
security/manager/ssl/nsICertOverrideService.idl -L 84,113
[...]
345598abc1d6f (Masatoshi Kimura 2019-06-11) void rememberValidityOverride(
in AUTF8String aHostName,
e368dc9c853cf (Ehsan Akhgari 2012-08-22) in int32_t aPort,
7ea1bcd018a32 (R. Martinho Fernandes 2021-06-01) in jsval aOriginAttributes,
61d16d4cd9588 (kaie@kuix.de 2007-10-03) in nsIX509Cert aCert,
e368dc9c853cf (Ehsan Akhgari 2012-08-22) in uint32_t aOverrideBits,
f2e2a270fb9a4 (kaie@kuix.de 2007-11-19) in boolean aTemporary);
If we check out the commit 7ea1bcd018a32 that introduced the change, we can see it takes us to differential revision D91962:
$ git log -1 7ea1bcd018a32
commit 7ea1bcd018a32a8e98216cf9f675c49d582950ca
Author: R. Martinho Fernandes <bugs@rmf.io>
Date: Tue Jun 1 06:55:07 2021 +0000
Bug 1597600 - make certificate overrides depend on origin attributes
r=keeler,geckoview-reviewers,smaug,agi
Differential Revision: https://phabricator.services.mozilla.com/D91962
This was noticed by Vlad who dug down into the code and found the source of the error, fixing it by adding the missing parameter. It's great detective work and a nice fix.As I write this I've approved the change myself and hopefully it'll be picked up and reviewed by Jolla so that it can be merged swiftly in to the ESR 91 branch.
Besides this I also received really nice review feedback from sailors Raine (rainemak) and Mal (mlehtima) in relation to my gecko-dev pull request. This pull request is the one that actually performs the upgrade from ESR 78 to ESR 91. The upgrade takes the form of redirecting a submodule to a different upstream commit so is a super-simple change. The bigger part is the set of patches that then has to be applied on top of the upstream code to make it all work. This is all in the pull request as well.
Raine and Mal clearly spent some time going through the commits and I'm really grateful for their suggestions. The result was better preference handling and several commits being merged or removed entirely. On Mal's request I also rebased the code to bring in recent changes needed to support Jolla's updated SDK. The totality of these changes all make for a much cleaner commit history and impoved code.
This pull request, along with the pull requests for the sailfish-browser and sailfish-components-webview repositories, are now awaiting a second review from the Jolla team. As far as I'm aware I've completed the changes requested, but there may still be a few more review rounds to go before they get merged in.
The other change this week has been to the package tarballs available from my website. These are very much still testing packages and you should read all of the info in the installation instructions before you use them. Nevertheless these new packages should provide some nice improvements over the previous ones. The main changes are:
- The user agent patch has now been applied, so problems with pages serving desktop rather than mobile variants should now be largely resolved.
- Vlad's HTTPS fix is included so you can now view pages with broken TLS certificates if you so choose.
You should, however, still do step 5 to clean out the old settings files. This won't clear cookies, tabs, history or anything like that, but it will reset any preferences you've changed using about:config. In summary, if you already have ESR 91 installed you should complete the following steps:
- Download the tarball to your phone.
$ curl -O https://www.flypig.co.uk/dnload/dnload/sailfishos/gecko/gecko-dev-esr91-release.tar.bz2
- Unpack the tarball:
$ tar -xvf gecko-dev-esr91-release.tar.bz2
- Ensure the browser and any apps using the WebView are closed.
- [Skip this step]
- Remove settings that need to be updated for ESR 91:
$ rm ~/.local/share/org.sailfishos/browser/.mozilla/ua-update.json $ rm -rf ~/.local/share/org.sailfishos/browser/.mozilla/startupCache $ rm ~/.local/share/org.sailfishos/browser/.mozilla/prefs.js $ rm ~/.local/share/org.sailfishos/browser/__PREFS_WRITTEN__
- Install the ESR 91 packages:
$ devel-su rpm -U --force \ xulrunner-qt5-91.*.rpm \ xulrunner-qt5-misc-91.*.rpm \ qtmozembed-qt5-1.*.rpm \ sailfish-components-webview-qt5-1.*.rpm \ sailfish-components-webview-qt5-pickers-1.*.rpm \ sailfish-components-webview-qt5-popups-1.*.rpm \ embedlite-components-qt5-1.*.rpm \ sailfish-browser-2.*.rpm \ sailfish-browser-settings-2.*.rpm \ mapplauncherd-booster-browser-0.*.rpm - [Skip this step]
- Finally kill the browser booster:
$ killall booster-browser
- You're good to go!
That summarises the changes this week. I'm still writing up my retrospective of the project so far and will post it once it's ready.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
8 Sep 2024 : Day 339 #
It's been just under a week since I posted my last diary entry. In the meantime I've been attending RSECon24 learning about assorted software engineering topics and meeting others in the research software engineering community. But you'll be pleased to hear that I did also find some time for gecko dev work as well.
Not as much as I would normally do, so in retrospect pausing my diary entries was the right thing to do. But it's been enough progress to justify my promised summary today.
Before we get into the details of what I've personally been working on I want to first talk about what others have been doing, as well as considering the future of these dev diaries.
Before heading to the conference I submitted five pull requests:
And that seems to have been borne out by how things have been moving since then. There have been exciting developments pulling in input from across the Sailfish community and beyond, from both developers and users. I'd like to highlight just some of the things that have started happening recently and which give me great optimism for the future of both Sailfish OS browser development and the Sailfish OS platform more broadly.
Started by Frajo (krnlyng), but then contributed to by Mal (mlehtima) and Affe Nul (affenull2345), the hangs and crashes coming from the EGL rendering pipeline have been carefully ironed out in the libhybris layer. The solutions were completely unexpected as far as I was concerned and I'd never have been able to figure them out myself, so this was a source of much celebration and admiration from me.
There have also been other pull requests to address actual issues in the browser brought on by the upgrade. There are so many features in a browser it's very hard to test everything (an argument for good unit tests, but that's a real challenge given the discrete approach to upgrades required for Gecko on Sailfish OS). A great example of this is the pull request submitted by Vlad G (vlagged) to fix bad certificate overrides. It was easy for me to miss this functionality. Vlad has been a dedicated follower of the dev diaries and it's important not to underestimate how important contributions like this are. It's this kind of diligent, proactive and practical help that the browser really need to be a success.
Quite apart from the motivation it's given me over the last year, the discussion on the Sailfish forum has driven some important advances for the browser. There's been a healthy discussion about sites that have glitches or aren't working correctly, for example from Tone (tortoisedoc), Daniel (jauri.gagarin.II), Sebastian (smatkovi) and others.
I'm hoping that many of these issues will turn out to be related to user-agent strings and the fact that I'd missed off an important user-agent patch. This was flagged up through a discussion between Attah (attah) and Raine (rainemak). Now that the patch has been applied, thanks to their work, many of the pages will hopefully work more successfully.
Members of the Sailfish community have invested their time and energy into testing ESR 91 on a range of difference devices, including Pasi (Pasik2) testing on the Pinetab 2, Ladislav Hodas (lhodas) on the Gemini and Affe Nul (affenull2345) on the Samsung Galaxy A40. Matti Viljanen (direc85) deserves a special mention for getting complete rebuilds working for armv7hl and i486 versions of the packages, demonstrating that this can be achieved with minimal changes. From what I understand there are still issues to be worked out with the resulting packages, but this is work that I'd have struggled to do on my own.
Sticking with Matti, who I'm very pleased to see is now working for Jolla (congratulations!), he provided me with excellent advice on improving the build both in public and private communications, especially in relation to the Rust components. On the topic of Rust, I also received really useful suggestions from Tone (tortoisedoc) which also has the potential to improve Rust builds.
There was some useful discussion on the forum about the WebRender pipeline and its relationship to Progressive Web Apps, with Simon Schmeisser (simonschmeisser), Tone (tortoisedoc), Attah (attah) and olf (Olf0) all contributing. It was a worthwhile read covering important ground. These are the sorts of topics that will deserve even more discussion once we start thinking about ESR 102 (it will happen!).
I can't possibly mention everyone who's spent time encouraging me over the last year, but let me just say that it was gratifying to receive such kind remarks on the forum from so many users who tried out the packages, including Harry (hschmitt), hanswf, Helge, Patrick (pherjung), ric9k, 247, Tuomas Nurmi (Mazoon), Christian (p1rat), Maximilian (Maximilian1st), Edz, Uli (Fellfrosch), Mark Washeim (poetaster), Throwaway69, eson, Gabriele (gabrigubin), Felix (FelixWilke), Ricardo (monkeyisland) and KeksKopf (davidrasch), as well as many more on Mastodon.
And finally, the really hard work will now fall to the Jolla team. Raine (rainemak) and Mal (mlehtima) have already provided invaluable review comments. Alongside Frajo (krnlyng), Matti (direc85) and no doubt others, I'm hoping they'll be able to pick up some of this work to chisel off the sharper corners and sand down the rough edges. The result of Jolla's unparalleled engineering expertise will give a better result than I could ever hope to achieve.
An important thread that runs throughout these contributions is that I'd have struggled to do all this on my own. Focused on the code, I've not been spending my time trying to persuade others to contribute. Members of the community have therefore taken their own initiative to help and the browser has benefited enormously as a result.
This list turned out far longer than I was expecting and by necessity captures only some of the exciting developments that have been driven by the community recently. I'm very excited to see how things continue to progress.
But it also highlights the challenge that's now presented to me as I write this development diary. The work has become more distributed and this will inevitably dilute my contributions in a positive way. That's a great thing and my expectation is that I'll likely now spend less of my time directly working on the code and more of my time on the processes needed to get the browser released.
That means a daily development diary probably doesn't make much sense any more. Up until now the act of writing daily has been critical in driving me forwards, ensuring I don't lose focus and keeping me on track. That's no longer needed; the browser now has its own momentum.
But I do still want to maintain a record of progress. I hope to capture developments up until the browser is properly released, assuming it can get to that point. So my plan for this diary in the future is to write a weekly update on how things are progressing. If there's not much to write about, I'll write up my thoughts on a topic related to Gecko and Sailfish OS more generally. I'll publish them at the weekend because that's when the other pieces of my life are least frantic, giving me the opportunity to consolidate my thoughts from the week gone by. To reflect this change in pace I'll no longer count the days but rather give each post a proper title.
That's my plan. If it doesn't work out, I can always change it. Please do share your thoughts about it with me as I'm always grateful to receive them.
With all this in mind, let's return to those pull requests and talk about what's happened to them over the last week. I'm really happy that two of them have already been merged into the upstream repository. They're not on the main branch yet, which is still on ESR 78, but this is an important step towards that.
That leaves three remaining. Raine and Mal both added comments to these which left me with a bit of work to do to address their requests. Some of these changes were straightforward, like removing extraneous empty lines that I added during development and forgot to remove.
Changes like these have no impact on the code semantics and so wouldn't even necessarily justify a rebuild. But they still take a surprising length of time to address. If they're part of the mirrored gecko code the repository has to be reset, cleaned and all patches applied. Once the change has been made it needs to be squashed into the commit where it was added. Then the patches need to be regenerated. Only then can the changes be committed and pushed to the remote repository.
This is one of the reasons I'm not keen on working with patches. I find myself repeatedly having to clean the repository, apply the patches and then regenerate them before a fresh set of commits can be pushed. I find it surprisingly laborious. And while I fully understand the reasons for using them (the rpm build process has been tailored for this approach) that doesn't make me like them any more.
That's for the simplest of changes, but some of the changes are more substantial. For example Raine requested various changes to how preferences should be applied, all of which are very legitimate.
These changes centre around Sailfish OS specific preferences which differ depending on whether the browser or WebView is in use.
In these cases they can either be set to the default of the browser or set to the default of the WebView. Whichever way is chosen, some code is needed in either the WebView or the browser to ensure the value is correctly toggled from the default for the other.
My original code set the value to a default that worked for the browser, then flipped them in the WebView initialisation code. From what I understand, Raine was keen for me to do the opposite. That is, to set defaults that work for the WebView but are then flipped by the browser initialisation code. The request itself was spread over several or Raine's comments, but the following is perhaps the pithiest of the descriptions:
Consequently I updated the default values set in the gecko code, removed some code from the WebView and added some equivalent code to the browser like this:
Having made these changes I then merged them in to the existing branch. To keep things clean I've squashed the changes into relevant commits. But this did also mean spending a bit of time rebasing all of the commits in the pull request.
The resulting in changes to all three of the outstanding pull requests:
Consequently I've pushed the changes upstream to the pull requests. My timing isn't ideal, right before the weekend, but I'll look forward to hearing more from the Jolla team in due course.
That's it for today. I'll return next week with a summary of changes that have taken place during the week. I'm also planning a retrospective to summarise the entire process of the last 339 days of development: what went well, what could have gone better and what the experience has been like for me.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.
Comment
Not as much as I would normally do, so in retrospect pausing my diary entries was the right thing to do. But it's been enough progress to justify my promised summary today.
Before we get into the details of what I've personally been working on I want to first talk about what others have been doing, as well as considering the future of these dev diaries.
Before heading to the conference I submitted five pull requests:
- https://github.com/sailfishos/gecko-dev/pull/162
- https://github.com/sailfishos/qtmozembed/pull/49
- https://github.com/sailfishos/sailfish-browser/pull/1074
- https://github.com/sailfishos/embedlite-components/pull/100
- https://github.com/sailfishos/sailfish-components-webview/pull/169
And that seems to have been borne out by how things have been moving since then. There have been exciting developments pulling in input from across the Sailfish community and beyond, from both developers and users. I'd like to highlight just some of the things that have started happening recently and which give me great optimism for the future of both Sailfish OS browser development and the Sailfish OS platform more broadly.
Started by Frajo (krnlyng), but then contributed to by Mal (mlehtima) and Affe Nul (affenull2345), the hangs and crashes coming from the EGL rendering pipeline have been carefully ironed out in the libhybris layer. The solutions were completely unexpected as far as I was concerned and I'd never have been able to figure them out myself, so this was a source of much celebration and admiration from me.
There have also been other pull requests to address actual issues in the browser brought on by the upgrade. There are so many features in a browser it's very hard to test everything (an argument for good unit tests, but that's a real challenge given the discrete approach to upgrades required for Gecko on Sailfish OS). A great example of this is the pull request submitted by Vlad G (vlagged) to fix bad certificate overrides. It was easy for me to miss this functionality. Vlad has been a dedicated follower of the dev diaries and it's important not to underestimate how important contributions like this are. It's this kind of diligent, proactive and practical help that the browser really need to be a success.
Quite apart from the motivation it's given me over the last year, the discussion on the Sailfish forum has driven some important advances for the browser. There's been a healthy discussion about sites that have glitches or aren't working correctly, for example from Tone (tortoisedoc), Daniel (jauri.gagarin.II), Sebastian (smatkovi) and others.
I'm hoping that many of these issues will turn out to be related to user-agent strings and the fact that I'd missed off an important user-agent patch. This was flagged up through a discussion between Attah (attah) and Raine (rainemak). Now that the patch has been applied, thanks to their work, many of the pages will hopefully work more successfully.
Members of the Sailfish community have invested their time and energy into testing ESR 91 on a range of difference devices, including Pasi (Pasik2) testing on the Pinetab 2, Ladislav Hodas (lhodas) on the Gemini and Affe Nul (affenull2345) on the Samsung Galaxy A40. Matti Viljanen (direc85) deserves a special mention for getting complete rebuilds working for armv7hl and i486 versions of the packages, demonstrating that this can be achieved with minimal changes. From what I understand there are still issues to be worked out with the resulting packages, but this is work that I'd have struggled to do on my own.
Sticking with Matti, who I'm very pleased to see is now working for Jolla (congratulations!), he provided me with excellent advice on improving the build both in public and private communications, especially in relation to the Rust components. On the topic of Rust, I also received really useful suggestions from Tone (tortoisedoc) which also has the potential to improve Rust builds.
There was some useful discussion on the forum about the WebRender pipeline and its relationship to Progressive Web Apps, with Simon Schmeisser (simonschmeisser), Tone (tortoisedoc), Attah (attah) and olf (Olf0) all contributing. It was a worthwhile read covering important ground. These are the sorts of topics that will deserve even more discussion once we start thinking about ESR 102 (it will happen!).
I can't possibly mention everyone who's spent time encouraging me over the last year, but let me just say that it was gratifying to receive such kind remarks on the forum from so many users who tried out the packages, including Harry (hschmitt), hanswf, Helge, Patrick (pherjung), ric9k, 247, Tuomas Nurmi (Mazoon), Christian (p1rat), Maximilian (Maximilian1st), Edz, Uli (Fellfrosch), Mark Washeim (poetaster), Throwaway69, eson, Gabriele (gabrigubin), Felix (FelixWilke), Ricardo (monkeyisland) and KeksKopf (davidrasch), as well as many more on Mastodon.
And finally, the really hard work will now fall to the Jolla team. Raine (rainemak) and Mal (mlehtima) have already provided invaluable review comments. Alongside Frajo (krnlyng), Matti (direc85) and no doubt others, I'm hoping they'll be able to pick up some of this work to chisel off the sharper corners and sand down the rough edges. The result of Jolla's unparalleled engineering expertise will give a better result than I could ever hope to achieve.
An important thread that runs throughout these contributions is that I'd have struggled to do all this on my own. Focused on the code, I've not been spending my time trying to persuade others to contribute. Members of the community have therefore taken their own initiative to help and the browser has benefited enormously as a result.
This list turned out far longer than I was expecting and by necessity captures only some of the exciting developments that have been driven by the community recently. I'm very excited to see how things continue to progress.
But it also highlights the challenge that's now presented to me as I write this development diary. The work has become more distributed and this will inevitably dilute my contributions in a positive way. That's a great thing and my expectation is that I'll likely now spend less of my time directly working on the code and more of my time on the processes needed to get the browser released.
That means a daily development diary probably doesn't make much sense any more. Up until now the act of writing daily has been critical in driving me forwards, ensuring I don't lose focus and keeping me on track. That's no longer needed; the browser now has its own momentum.
But I do still want to maintain a record of progress. I hope to capture developments up until the browser is properly released, assuming it can get to that point. So my plan for this diary in the future is to write a weekly update on how things are progressing. If there's not much to write about, I'll write up my thoughts on a topic related to Gecko and Sailfish OS more generally. I'll publish them at the weekend because that's when the other pieces of my life are least frantic, giving me the opportunity to consolidate my thoughts from the week gone by. To reflect this change in pace I'll no longer count the days but rather give each post a proper title.
That's my plan. If it doesn't work out, I can always change it. Please do share your thoughts about it with me as I'm always grateful to receive them.
With all this in mind, let's return to those pull requests and talk about what's happened to them over the last week. I'm really happy that two of them have already been merged into the upstream repository. They're not on the main branch yet, which is still on ESR 78, but this is an important step towards that.
That leaves three remaining. Raine and Mal both added comments to these which left me with a bit of work to do to address their requests. Some of these changes were straightforward, like removing extraneous empty lines that I added during development and forgot to remove.
Changes like these have no impact on the code semantics and so wouldn't even necessarily justify a rebuild. But they still take a surprising length of time to address. If they're part of the mirrored gecko code the repository has to be reset, cleaned and all patches applied. Once the change has been made it needs to be squashed into the commit where it was added. Then the patches need to be regenerated. Only then can the changes be committed and pushed to the remote repository.
This is one of the reasons I'm not keen on working with patches. I find myself repeatedly having to clean the repository, apply the patches and then regenerate them before a fresh set of commits can be pushed. I find it surprisingly laborious. And while I fully understand the reasons for using them (the rpm build process has been tailored for this approach) that doesn't make me like them any more.
That's for the simplest of changes, but some of the changes are more substantial. For example Raine requested various changes to how preferences should be applied, all of which are very legitimate.
These changes centre around Sailfish OS specific preferences which differ depending on whether the browser or WebView is in use.
In these cases they can either be set to the default of the browser or set to the default of the WebView. Whichever way is chosen, some code is needed in either the WebView or the browser to ensure the value is correctly toggled from the default for the other.
My original code set the value to a default that worked for the browser, then flipped them in the WebView initialisation code. From what I understand, Raine was keen for me to do the opposite. That is, to set defaults that work for the WebView but are then flipped by the browser initialisation code. The request itself was spread over several or Raine's comments, but the following is perhaps the pithiest of the descriptions:
I think embedding.js (embedlite omni.ja) should default to false and browser set it true.
Consequently I updated the default values set in the gecko code, removed some code from the WebView and added some equivalent code to the browser like this:
// Ensure the renderer is configured correctly
webEngineSettings->setPreference(QStringLiteral(
"embedlite.compositor.external_gl_context"),
QVariant(true));
webEngineSettings->setPreference(QStringLiteral(
"embedlite.compositor.request_external_gl_context_early"),
QVariant(true));
Thankfully these are also pretty simple changes, but they did need a bit of thought, not least because they touch on three separate packages. The gecko engine, the browser and the WebView code all needed updating, albeit each in only a small way.Having made these changes I then merged them in to the existing branch. To keep things clean I've squashed the changes into relevant commits. But this did also mean spending a bit of time rebasing all of the commits in the pull request.
The resulting in changes to all three of the outstanding pull requests:
- https://github.com/sailfishos/gecko-dev/pull/162
- https://github.com/sailfishos/sailfish-browser/pull/1074
- https://github.com/sailfishos/sailfish-components-webview/pull/169
Consequently I've pushed the changes upstream to the pull requests. My timing isn't ideal, right before the weekend, but I'll look forward to hearing more from the Jolla team in due course.
That's it for today. I'll return next week with a summary of changes that have taken place during the week. I'm also planning a retrospective to summarise the entire process of the last 339 days of development: what went well, what could have gone better and what the experience has been like for me.
If you'd like to read any of my other gecko diary entries, they're all available on my Gecko-dev Diary page.